Redis 入门到分布式 (四) 瑞士军刀Redis其他功能
个人博客网:https://wushaopei.github.io/ (你想要这里多有)
目录:
- 慢查询
- Pipeline
- 发布订阅
- Bitmap(位图)
- HyperLogLog
- GEO
一、慢查询
1、慢查询:
生命周期
三个命令
两个配置
运维经验
2、生命周期图解:

两点说明:
- 慢查询发生在第3阶段 (如:keys *)
- 客户端超时不一定慢查询,但慢查询是客户端超时的一个可能因素
两个配置: -slowlog-max-len
- 慢查询是一个先进先出队列
- 队列是固定长度的
- Redis是保存在内存内

slowlog list 是慢查询的集合;
slowlog-max-len 是慢查询的长度或者数量,如图,慢查询从slowlog100到slowlog1以队列形式排列入列;
两个配置 —— slowlog-log-slower-than
- 慢查询阈值(单位:微秒)
- Slowlog-log-slower-than=0,记录所有命令
- Slowlog-log-slower-than<0,不记录任何命令
3、配置方法
1) 默认值
config get slowlog-max-len = 128
config get slowlog-log-slower-than = 10000
2) 修改配置文件重启
3) 动态配置
config set slowlog-max-len 1000
config set slowlog-log-slower-than 1000
4、慢查询命令:
1) slowlog get [n] : 获取慢查询队列
2)slowlog len : 获取慢查询队列长度
3)slowlog reset : 清空慢查询队列
5、慢查询运维经验:
1) slowlog-max-len 不要设置过大,默认10ms,通常设置1ms
2) slowlog-log-slower-than 不要设置过小,通常设置1000左右
3)理解命令生命周期
4)定期持久化慢查询
二、pipeline
什么是流水线?
客户端实现
与原生操作对比
使用建议
1次网络命令通信模型

如图,经历了 1次时间 = 1次网络时间 + 1次命令时间
批量网络命令通信模型

如图,经历了 n次时间 = n次网络时间 + n次命令时间
1、什么是流水线?

如图,经历了 1次pipeline(n条命令) = 1次网络时间 + n次命令时间,这大大减少了网络时间的开销,这就是流水线。
2、流水线的作用

两点注意:
- redis的命令时间是微秒级别
- pipeline每次条数要控制(网络)
3、案例展示——从北京到上海的一条命令的生命周期有多长?

由图可知,执行一条命令在redis端可能需要几百微秒,而在网络光纤中传输只花费了13毫秒。假如在执行批量操作而没有使用pipeline功能,会将大量的时间耗费在每一次网络传输的过程上;而使用pipeline后,只需要经过一次网络传输,然后批量在redis端进行命令操作。这会大大提高了效率。
4、pipeline-Jedis实现?
首先,引入jedis依赖包:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
<type>jar</type>
<scope>compile</scope>
</dependency>
演示:
1) 没有pipeline的命令执行:
Jedis jedis - new Jedis("127.0.0.1",6379);
for ( int i = 0 ; i < 10000 ; i ++ ){
jedis.hset("hashkey:" + i , "field" + i , "value" + i);
}

假设,在不使用pipeline的情况下,使用for循环进行每次一条命令的执行操作,耗费的时间可能达到 1w 条插入命令的耗时为50s。
2) 使用pipeline:
Jedis jedis = new Jedis("127.0.0.1",6379);
for ( int i = 0; i < 100 ; i++) {
Pipeline pipeline = jedis.ppipelined();
for (int j = i * 100 ; j < (i + 1) * 100 ; j++) {
pipeline.hset("hashkey:" + j,"field" + j, "value" + j);
}
pipeline.syncAndReturnAll();
}

假设使用了pipeline 进行批量操作,每次传输100条命令到redis端进行执行操作,大概 1w插入条命令需耗时 0.7s
3)与原生M操作?

在原生的redis命令操作中,命令的执行是依次按入列的顺序一条一条执行,具有原子性。

在使用pipeline进行批量操作后,会将大量命令用pipeline 包装起来,一次性发送到服务端,然后在服务端进行拆分成多个基本命令,此时命令的执行次序是不一定的,因此是非原子性的。
但,命令执行结果的返回是有序的。
5、使用建议
1) 注意每次pipeline 携带数据量
2) pipeline每次只能作用在一个Redis节点上
3)M操作与pipeline区别
三、发布订阅
角色
模型
API
发布订阅与消息队列
1、角色:
发布者
频道
订阅者
2、模型:
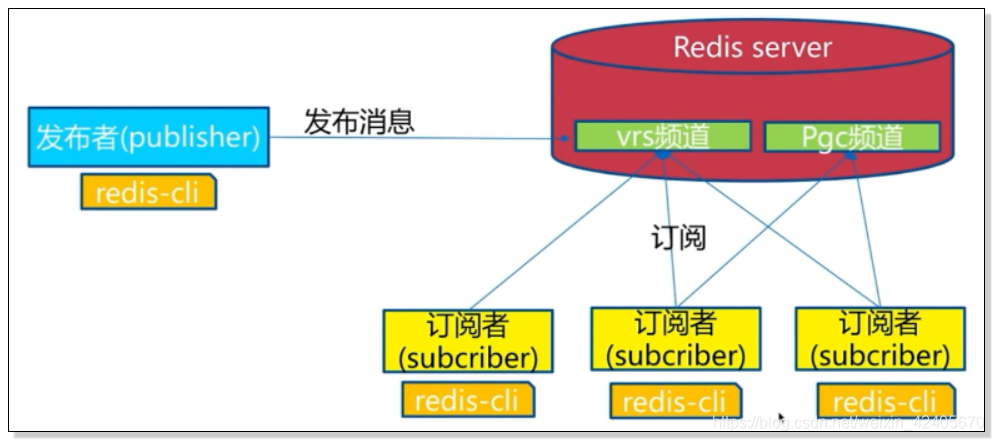
发布者发布一条消息,订阅者如果订阅了这个频道就可以收到这条消息。
注意:所有的订阅者都能够收到消息。并且一个订阅者可以订阅不同的频道。
订阅者无法获取到未订阅前已发布的消息,即无法对已发布消息尽心追击。
3、API
1.Publish
2.Subscribe
3.Unsubscribe
4.其他
1)publish (发布命令)

2)subcribe(订阅)

3)unsubcribe(取消订阅)

4)其他API:

4、消息队列:

Redis中并没有消息队列这一功能,它对消息队列的实现是通过List发布数据后利用阻塞的机制,将发布的消息如图中的hello\java到服务端,由客户端进行抢夺,客户端拿到后原来的值发生删改的变化来实现的。
5、发布订阅总结:
- 发布订阅模式中的角色
- 重要的API
- 发布订阅和消息队列的使用场景
四、 bitmap(位图)
位图
相关命令
独立用户统计
1、什么是位图?
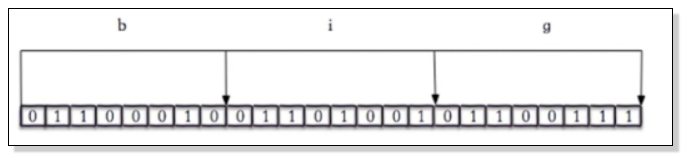
字符串big 对应的二进制
如上图,位图将字符串以对应二进制进行存储。
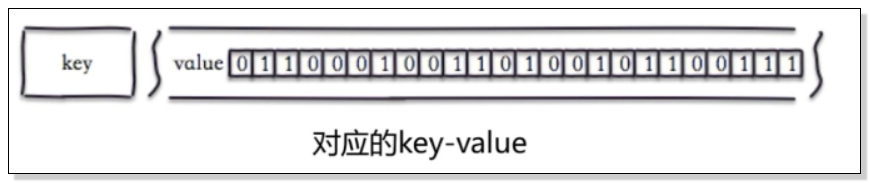
位图的最大意义在于能够直接去操作redis中的value进行转换后的二进制码,即01100....等。
2、API : 位图偏移设置—— setbit

演示:
127.0.0.1:6379> setbit unique:users:2016-04-05 0 1
(integer) 0
127.0.0.1:6379> setbit unique:users:2016-04-05 5 1
(integer) 0
127.0.0.1:6379> setbit unique:users:2016-04-05 11 1
(integer) 0
127.0.0.1:6379> setbit unique:users:2016-04-05 15 1
(integer) 0
127.0.0.1:6379> setbit unique:users:2016-04-05 19 1
(integer) 0
演示效果图:
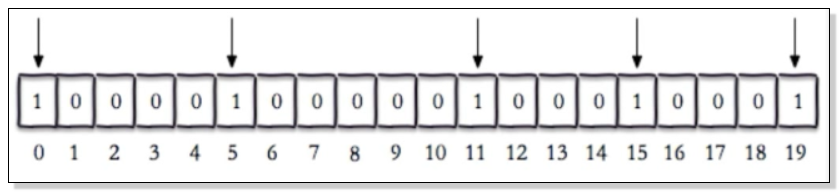
以上设置一个以unique:users:2016-04-05为key的数据,这里由于没有对该key的value进行初始化设置,默认每一次的setbit操作会在对应的二进制中指定的索引位置插入1,而为声明部分默认为0;即索引为0、5、11、15、19的位置值为1,其他索引位置值为0.
3、API : 位图偏移范围值获取——bitcount

演示:
127.0.0.1:6379> bitcount unique:users:2016-04-05
(integer) 5
127.0.0.1:6379> bitcount unique:users:2016-04-05 1 3
(integer) 3
上图中,key为unique:users:2016-04-05的位图长度为5,其中偏移量从1到3的值长度为3.
4、API : 位图区间交互——bitop:

演示:
127.0.0.1:6379> bitop and unique:users:and:2016_04_04-2016_04_05 unique:users:2016-04-05 unique:users:2016-04-04
(integer) 3
127.0.0.1:6379> bitcount unique:users:and:2016_04_04-2016_04_05
(integer) 0
5、API : 获取位图指定值的偏移坐标——bitpos

注意,返回的位的位置始终是从0开始的,即使使用了start来指定了一个开始字节也是这样。
演示:
127.0.0.1:6379> bitpos unique:users:2016-04-04 1
(integer) 1
127.0.0.1:6379> bitpos unique:users:2016-04-04 0 1 2
(integer) 8
6、独立用户统计:
- 使用set 和Bitmap
- 1亿用户,5千万独立

使用经验:
- type = string , 最大512MB
- 注意setbit时的偏移量,可能有较大耗时
- 位图不是绝对好
五、 hyperloglog
新的数据结构
内存消耗
三个命令
使用经验
1、基于HyperLogLog算法:
绩效空间完成独立数量统计。
2、本质还是字符串
127.0.0.1:6379> type hyperloglog_key
string
3、三个API命令:
1) pfadd key element [element ...] :向hyperloglog添加元素
2)pfcount key [key ...] : 计算hyperloglog的独立总数
3)pfmerge destkey sourcekey [sourcekey ...] : 合并多个hyperloglog
使用方法:
1) Demo演示:
127.0.0.1:6379> pfadd 2017_03_06:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-4"
(integer) 1
127.0.0.1:6379> pfcount 2017_03_06:unique:ids
(integer) 4
127.0.0.1:6379> pfadd 2017_03_06:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-90"
(integer) 1
127.0.0.1:6379> pfcount 2017_03_06:unique:ids
(integer) 5
①向id添加四个独立元素,返回结果为1
②查看独立元素为4个;
③再添加四个独立元素,其中三个重复,一个新的,返回1
④查询独立元素为5个,说明独立元素不可重复。
2) 模拟—— 两个key的八个独立用户的统计合并:
127.0.0.1:6379> pfadd 2016_03_06:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-4"
(integer) 1
127.0.0.1:6379> pfcount 2016_03_06:unique:ids
(integer) 4
127.0.0.1:6379> pfadd 2016_03_05:unique:ids "uuid-4" "uuid-5" "uuid-6" "uuid-7"
(integer) 1
127.0.0.1:6379> pfcount 2016_03_05:unique:ids
(integer) 4
127.0.0.1:6379> pfmerge 2016_03_05_06:unique:ids 2016_03_05:unique:ids 2016_03_06:unique:ids
OK
127.0.0.1:6379> pfcount 2016_03_05_06:unique:ids
(integer) 7
4、统计:内存消耗(百万独立用户):
①定义一个key;
②声明一个百万次的for循环
③拼接1000次元素;
④拼接满1000次,执行一次独立元素的插入
⑤清空element 临时变量
性能展示:

5、使用经验:
1) 是否能容忍错误?(错误率: 0.81%)
127.0.0.1:6379> pfcount 2016_05_01:unique:ids(integer)
1009838
2) 是否需要单条数据
六、geo
1、GEO是什么
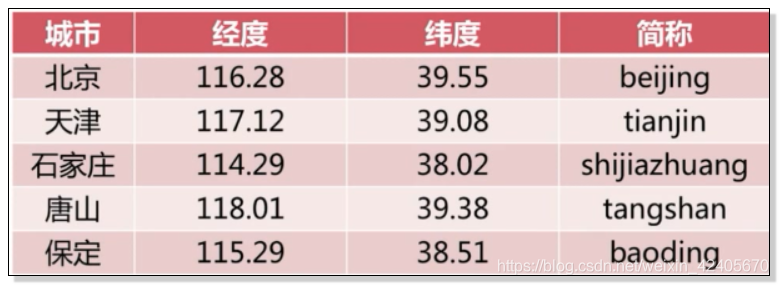
以计算5个城市经纬度为例:
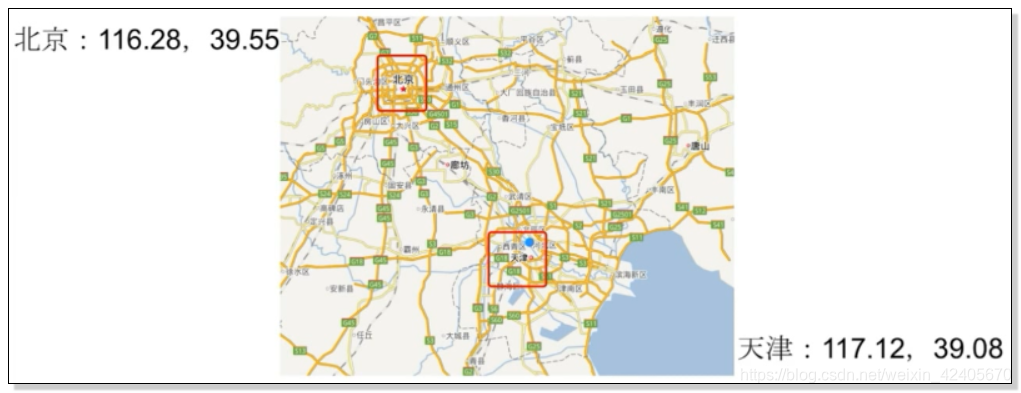
GEO(地理信息定位):存储经纬度,计算两地距离,范围计算等
2、API: geoadd

演示:
127.0.0.1:6379> geoadd cities:locations 116.28 39.55 beijing
(integer) 1
127.0.0.1:6379> geoadd cities:locations 116.28 39.55 beijing
(integer) 0
127.0.0.1:6379> geoadd cities:locations 117.12 39.08 tianjin 114.29 38.02 shijianzhuang 118.01 39.38 tangshan 115.29 38.51 baoding
(integer) 4
3、API——geopos:

演示:
127.0.0.1:6379> geopos cities:locations tianjin
1) 1) "117.12000042200088501"
2) "39.0800000535766543"
4、API——geodist

演示:
127.0.0.1:6379> geodist cities:locations tianjin beijing km
"87.3054"
5、复杂API——georadius

演示:
127.0.0.1:6379> georadiusbymember cities:locations beijing 150 km
1) "beijing"
2) "tianjin"
3) "tangshan"
4) "baoding"
6、相关说明:
1) since 3.2+
2) type geoKey = zset
3) 没有删除API: zrem key member
Redis 入门到分布式 (四) 瑞士军刀Redis其他功能的更多相关文章
- redis入门指南(四)—— redis如何节省空间
写在前面 学习<redis入门指南>笔记,结合实践,只记录重要,明确,属于新知的相关内容. 节省空间 1.redis对于它所支持的五种数据类型,每种都提供了两种及以上的编码方式去存储(具体 ...
- 分布式缓存技术redis学习系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
本文是redis学习系列的第四篇,前面我们学习了redis的数据结构和一些高级特性,点击下面链接可回看 <详细讲解redis数据结构(内存模型)以及常用命令> <redis高级应用( ...
- Redis 入门到分布式 (二)API的理解和使用
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 内容: 通用命令 单线程架构 数据结构和内部编码 一.常用的通用命令: keys 计算所有的 ...
- Redis 入门到分布式 (一)Redis初识
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.Redis特性目录 Redis的特性: 速度快 持久化 多种数据结构 支持多种编辑语言 功能丰富 简 ...
- Redis 入门到分布式 (八)Redis Sentinel
个人博客网:https://wushaopei.github.io/ (你想要这里多有) sentinel-目录 主从复制高可用 安装配置 实现原理 架构说明 客户端连接 常见开发运维问题 一. ...
- Redis 入门到分布式 (五) Redis持久化的取舍和选择
个人博客网:https://wushaopei.github.io/ (你想要这里多有) Redis持久化的取舍和选择 持久化的作用 RDB AOF RDB和AOF的选择 一.持久化的作用 ...
- Redis入门必读,The Little Redis Book中文版
csdn的博客都要搬到这里了 The Little Redis Book中文版 入门 The Little Redis Book中文版 第一章 - 基础知识 The Little Redis Book ...
- redis之(十四)redis的主从复制的原理
一:redis主从复制的原理,步骤. 第一步:复制初始化 --->从redis启动后,会根据配置,向主redis发送SYNC命令.2.8版本以后,发送PSYNC命令. --->主red ...
- <Redis> 入门X 分布式锁
分布式其实就是多进程的程序,当多个进程访问一个资源,会造成问题: 1.资源共享的竞争问题 2.数据的安全性 分布式锁的解决方案: 1.怎么去获取锁 数据库 zookeeper redis 2.怎么释放 ...
随机推荐
- spark-2.4.5 安装记录
参考 https://data-flair.training/blogs/install-apache-spark-multi-node-cluster/ 下载 spark 地址为 http://sp ...
- [ACdream 1211 Reactor Cooling]无源无汇有上下界的可行流
题意:无源无汇有上下界的可行流 模型 思路:首先将所有边的容量设为上界减去下界,然后对一个点i,设i的所有入边的下界和为to[i],所有出边的下界和为from[i],令它们的差为dif[i]=to[i ...
- hdu2336 (匈牙利最大匹配+二分)
Describe 这是一个简单的游戏,在一个n*n的矩阵中,找n个数使得这n个数都在不同的行和列里并且要求这n个数中的最大值和最小值的差值最小. Input 输入一个整数T表示T组数据. 对于每组数据 ...
- 《学习笔记》.NET Core API搭建
1.创建 ASP.NET Core Web程序,记住取消HTTPS配置 2.此时一个简单的.NET Core API 架子搭建好了,细心的人可以发现Properties下面不是CS文件,确是launc ...
- 1026 Table Tennis (30分) 难度不高 + 逻辑复杂 +细节繁琐
题目 A table tennis club has N tables available to the public. The tables are numbered from 1 to N. Fo ...
- Redis学习笔记(十) 客户端
Redis服务器是典型的一对多服务器程序:一个服务器可以与多个客户端建立网络连接,每个客户端可以向服务器发送命令请求,而服务器则接收并处理客户端发送的命令请求,并向客户端返回命令回复. 通过使用由I/ ...
- tpcc-mysql 试用
percona 出的一个mysql压力测试工具,至于tpcc的话,是一个衡量事务处理能力的一个值.具体可以看老外对他的定义. http://www.tpc.org/tpcc/results/tpcc_ ...
- Appium自动化(9) - appium元素定位的快速入门
如果你还想从头学起Appium,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1693896.html 快速入门栗子:boss直聘 app ...
- Error: ER_BAD_FIELD_ERROR: Unknown column 'xxx' in 'where clause'
node中调用mysql模块读写时候,如果直接插入字符串: connection.query('SELECT * from users WHERE name=' + data.name , call ...
- WARN: Establishing SSL connection without server’s identity verification is not recommended
问题 使用Spring JDBC 连接 MySQL时,出现如下警告: WARN: Establishing SSL connection without server's identity verif ...