elasticsearch kibana + 分词器安装详细步骤
elasticsearch kibana + 分词器安装详细步骤
一、准备环境
系统:Centos7
JDK安装包:jdk-8u191-linux-x64.tar.gz
ES安装包:elasticsearch-7.2.0-linux-x86_64.tar.gz,下载地址
Kibana安装包:kibana-7.2.0-linux-x86_64.tar.gz,下载地址
IK分词器安装包:elasticsearch-analysis-ik-7.2.0.zip,下载地址
目前准备两个节点做节点规划,分别是
192.168.56.105、192.168.56.106
首先需要将JAVA环境安装完毕,目前的ES版本使用的是1.9版本的JDK,但是在安装包中已经包含了1.9的版本,所以我们自己可以使用1.8的,最终ES检测是否安装了1.9版本的,如果没有安装则使用自己安装包内的JDK。
#分别在两台机器上创建用户和用户组,这里每台机器上创建两个用户,后面涉及到单台机器多节点安装直接使用,如果只是单台机器单节点安装,每台建一个用户就行,主要是起到一个隔离作用,而且ES不能通过root用户启动
$ groupadd elastic
$ useradd -g elastic elastic1
$ useradd -g elastic elastic2
$ passwd elastic1
$ passwd elastic2
#关闭防火墙,禁止开机启动
$ systemctl stop firewalld
$ systemctl disable firewalld
二、每台机器单节点集群
在做当前类型的安装的时候只使用elastic1用户,后面需要单机安装多节点的时候才用elastic2用户
#我是安装在/opt目录 分别对两台机器做如下操作
root@localhost$ tar -zxvf elasticsearch-7.2.0-linux-x86_64.tar.gz
root@localhost$ mv elasticsearch-7.2.0 elasticsearch-7.2.0-elastic1
#设置目录属于elastic1用户elastic用户组
root@localhost$ chown -R elastic1:elastic elasticsearch-7.2.0-elastic1
如上内容设置完成之后,进行配置ES,在进行配置之前:
192.168.56.105节点作为master
192.168.56.106节点作为slave1
master(105)节点 config/elasticsearch.yml文件配置:
#集群名称
cluster.name: es_cluster
#节点角色名称
node.name: master
#当前主机Host
network.host: 192.168.56.105
#http端口
http.port: 9200
#tcp端口
transport.tcp.port: 9300
#是否为master节点
node.master: true
#是否作为数据节点
node.data: true
#这里是跨域相关内容的配置
http.cors.enabled: true
http.cors.allow-origin: "*"
#这里代表的是当前服务器上运行几个节点的ES实例
node.max_local_storage_nodes: 1
#符合master要求的节点,目前就只有一个,ES是自己内部实现了高可用的,所以可以多master
cluster.initial_master_nodes: ["192.168.56.105"]
#日志存储位置(不配置默认在安装包路径)
path.logs: /opt/elastic1/logs
#数据存储位置(不配置默认在安装包路径)
path.data: /opt/elastic1/data
slave1(106)节点 config/elasticsearch.yml文件配置:
cluster.name: es_cluster
node.name: slave1
network.host: 192.168.56.106
http.port: 9200
transport.tcp.port: 9300
node.data: true
http.cors.enabled: true
http.cors.allow-origin: "*"
node.max_local_storage_nodes: 1
#这里填写的是master节点的IP和TCP端口,有多少master填多少个,主要是用来做心跳检测和数据交互
discovery.seed_hosts: ["192.168.56.105:9300"]
path.logs: /opt/elastic1/logs
path.data: /opt/elastic1/data
如果在真实项目中还需要设置节点堆栈内存,默认是1G
config/jvm.options
-Xms1g
-Xmx1g
设置内存的时候根据自己情况设置,但是最好别超过32G,我在真实项目中设置的是31G因为超过的话会存在大内存问题,会造成内存资源浪费。
如上内容设置完成之后可以进行启动测试,启动的时候需要切到指定用户去启动,因为ES不能使用root启动,并且启动的时候很可能会报错,报错看下面解决办法,需要设置一些系统参数
# 终端启动运行
$ ./bin/elasticsearch
# 后台启动运行
$ ./bin/elasticsearch -d
三、每台机器多节点集群
每台机器上安装2个ES节点(两个ES实例)相关配置方式,目前规划
192.168.56.105
elastic1:masterelastic2:slave2
192.168.56.106
elastic1:slave1elastic2:slave2
根据上面的操作,准备好相关的包,并且设置好相关的权限,设置完成之后进行配置,目前是两台机器,四个ES节点(实例)
相关配置:
在进行相关配置的时候可以直接从另外一个slave节点copy一份配置文件来进行修改
192.168.56.105-master(elaster1):config/elasticsearch.yml
#只需要修改每台机器上能够部署的节点数就可以,其他的和上面的配置相同
node.max_local_storage_nodes: 2
192.168.56.105-slave2(elaster2):config/elasticsearch.yml
cluster.name: es_cluster
#修改节点名称
node.name: slave2
network.host: 192.168.56.105
#这里需要修改端口,不能和master节点冲突
http.port: 9201
#这里需要修改端口,不能和master节点冲突
transport.tcp.port: 9301
node.data: true
http.cors.enabled: true
http.cors.allow-origin: "*"
#将机器能够部署的节点数进行修改
node.max_local_storage_nodes: 2
#这里填写的是master节点的IP和TCP端口,有多少master填多少个,主要是用来做心跳检测和数据交互
discovery.seed_hosts: ["192.168.56.105:9300"]
path.logs: /opt/elastic2/logs
path.data: /opt/elastic3/data
192.168.56.106-slave1(elaster1):config/elasticsearch.yml
# 根据上面的配置修改机器能够部署的节点数,其他参数不变
node.max_local_storage_nodes: 2
192.168.56.106-slave2(elaster2):config/elasticsearch.yml
cluster.name: es_cluster
#修改节点名称
node.name: slave2
#修改节点ip
network.host: 192.168.56.106
#这里需要修改端口,不能和master节点冲突
http.port: 9201
#这里需要修改端口,不能和master节点冲突
transport.tcp.port: 9301
node.data: true
http.cors.enabled: true
http.cors.allow-origin: "*"
#将机器能够部署的节点数进行修改
node.max_local_storage_nodes: 2
#这里填写的是master节点的IP和TCP端口,有多少master填多少个,主要是用来做心跳检测和数据交互
discovery.seed_hosts: ["192.168.56.105:9300"]
path.logs: /opt/elastic2/logs
path.data: /opt/elastic3/data
如上内容配置完成之后进行各个节点的启动,启动的时候不同节点需要使用不同用户进行启动,这样能保证程序的隔离性,包括在停进程的时候也是,如果都启动完成了,可以通过root账户进行jps命令进行检查实例是否存在两个。
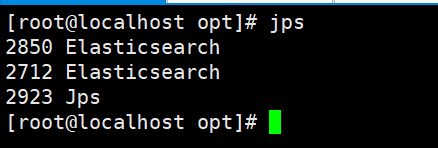
105-elastic1$ ./bin/elasticsearch -d
105-elastic2$ ./bin/elasticsearch -d
106-elastic1$ ./bin/elasticsearch -d
106-elastic2$ ./bin/elasticsearch -d
#关闭es,直接kill 进程,当然最好是到指定用户下进行kill这样能够区分,不容易混淆
注:其实单台机器装多个节点只需要注意同一机器上的节点端口不要重复就行,其他的配置和横向扩展没区别
四、kibana安装和分词器安装
安装Kibana
$ tar -zxvf kibana-7.2.0-linux-x86_64.tar.gz
kibana只是一个客户端,主要是方便自己管理和查看ES集群状态,并且提供了一些数据分析的功能,数据查询工具,索引管理以及监控等功能,所以装在一台机器上就行,目前就装在192.168.56.105机器上,可以设置为和master节点相同的用户和用户组也可以直接用elastic1
kibana-7.2.0-linux-x86_64/config/kibana.yml配置
#当前kibana所提供服务的节点地址
server.host: "192.168.8.108"
#服务名称
server.name: "yourkibana"
#连接的ES集群,连接master就行
elasticsearch.hosts: ["http://192.168.8.108:9200"]
#设置请求超时时间,默认是30000
elasticsearch.requestTimeout: 90000
配置完成之后启动验证是否成功
#现在终端启动,看看日志有没有报错的,没有的话再后台启动
$ ./bin/kibana
$ nohup ../bin/kibana &
访问Kibana
默认访问的端口是5601,地址是自己配置的地址,我这里是http://192.168.56.105:5601
Elasticsearch安装中文分词插件:
安装IK中文分词插件,将下载好的分词包安装解压然后放入到ES/plugin目录就可以了,但是在安装的时候要注意看版本之间的联系,刚开始的时候我使用的是7.5版本的分词器,安装的时候版本不兼容,后面下载了7.2版本的
$ yum install -y unzip
$ unzip -d ik elasticsearch-analysis-ik-7.2.0.zip
$ cp -r ik/ elasticsearch-7.2.0-elastic1/plugins/
$ cp -r ik/ elasticsearch-7.2.0-elastic2/plugins/
$ scp -r ik/ 192.168.56.106:/opt/elasticsearch-7.2.0-elastic1/plugins/
$ scp -r ik/ 192.168.56.106:/opt/elasticsearch-7.2.0-elastic2/plugins/
#登录到不同的节点去修改对应的ik文件夹的权限
$ chown -R elastic1:elastic /opt/elasticsearch-7.2.0-elastic1/plugins/
上面操作完成后,重启集群,然后验证是否能够进行正常的中文分词

如上图所示,能够对中文进行正确的分词,说明分词器安装成功
五、启动错误问题及解决办法
ERROR: [3] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[3]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
解决办法:
编辑/etc/security/limits.conf,追加以下内容
* soft nofile 65536
* hard nofile 65536
当前内容设置完成之后需要重新登录才能生效
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决办法:
编辑文件/etc/sysctl.conf,追加一下内容:
vm.max_map_count=655360
编辑完成之后保存,并执行sysctl -p命令
[3]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
解决办法:
出现上面两个错误说明没有在配置文件中配置好ES,需要配置上面中括号中的参数,具体的配置根据节点角色定,该问题一般不会遇到
[4]: max number of threads [2048] for user [tongtech] is too low, increase to at least [4096]
解决办法:
编辑文件/etc/security/limits.d/20-nproc.conf ,修改文件中的数值
* soft nproc 65535
root soft nproc unlimited
以上内容修改完成之后启动ES,查看ES是否能够正常启动成功
Likely root cause: java.nio.file.AccessDeniedException: /opt/elasticsearch-7.2.0-elastic1/config/elasticsearch.keystore
出现这个错误说明没有权限,看下confg/elasticsearch.keystore文件是否拥有相关权限,如果么有权限,则进行设置
root@localhost$ chown -R elastic1:elastic elasticsearch.keystore
elasticsearch kibana + 分词器安装详细步骤的更多相关文章
- solr8.2 环境搭建 配置中文分词器 ik-analyzer-solr8 详细步骤
一.下载安装Apache Solr 8.2.0 下载地址:http://lucene.apache.org/solr/downloads.html 因为是部署部署在windows系统上,所以下载zip ...
- 七、Elasticsearch+elasticsearch-head的安装+Kibana环境搭建+ik分词器安装
一.安装JDK1.8 二.安装ES 三个节点:master.slave01.slave02 1.这里下载的是elasticsearch-6.3.1.rpm版本包 https://www.elastic ...
- Elasticsearch教程(三),IK分词器安装 (极速版)
如果只想快速安装IK,本教程管用.下面看经过. 简介: 下面讲有我已经打包并且编辑过的zip包,你可以在下面下载即可. 当前讲解的IK分词器 包的 version 为1.8. 一.下载zip包. 下面 ...
- Elasticsearch 中文分词(elasticsearch-analysis-ik) 安装
由于elasticsearch基于lucene,所以天然地就多了许多lucene上的中文分词的支持,比如 IK, Paoding, MMSEG4J等lucene中文分词原理上都能在elasticsea ...
- linux/centos下安装nginx(rpm安装和源码安装)详细步骤
Centos下安装nginx rpm包 ...
- MySql Server 5.7的下载及安装详细步骤
1.下载安装包 1)找到官网下载地址(https://dev.mysql.com),选择downloads,找到windows
- linux下mysql-5.5.15安装详细步骤
linux下mysql-5.5.15安装详细步骤 注:该文档中用到的目录路径以及一些实际的值都是作为例子来用,具体的目录路径以各自安装时的环境为准 mysql运行时需要一个启动目录.一个安装目录和一个 ...
- Elasticsearch之分词器的作用
前提 什么是倒排索引? Analyzer(分词器)的作用是把一段文本中的词按一定规则进行切分.对应的是Analyzer类,这是一个抽象类,切分词的具体规则是由子类实现的,所以对于不同的语言,要用不同的 ...
- Elasticsearch之分词器的工作流程
前提 什么是倒排索引? Elasticsearch之分词器的作用 Elasticsearch的分词器的一般工作流程: 1.切分关键词 2.去除停用词 3.对于英文单词,把所有字母转为小写(搜索时不区分 ...
随机推荐
- 【学习笔记】splay入门(更新中)
声明:本博客所有随笔都参照了网络资料或其他博客,仅为博主想加深理解而写,如有疑问欢迎与博主讨论✧。٩(ˊᗜˋ)و✧*。 前言 终于学习了 spaly \(splay\) !听说了很久,因为dalao总 ...
- C#栈、堆的理解(2)
接上一遍博文有关值类型和引用类型的相关概念. 所有值类型数据存放:栈(内存) 引用类型的数据存放:堆(内存) 栈:可以认为是一本书的目录部分称其为栈.栈可快速检索,运行速度比堆大,而且栈的空间小得多. ...
- cgi、fastCGI、php-fpm、 php-CGI的区别
cgi.fastCGI.php-fpm. php-CGI的区别 作为面试的高频热点问题,必须来一波记录: 我们发送一个请求到收到响应之间的一个过程是什么? 如果客户端请求的是 index.html,那 ...
- linux上Docker安装gogs私服
一.背景介绍 Gogs 是一款类似GitHub的开源文件/代码管理系统(基于Git),Gogs 的目标是打造一个最简单.最快速和最轻松的方式搭建自助 Git 服务.使用 Go 语言开发使得 Gogs ...
- Serlvet容器与Web应用
对启动顺序的错误认识 之前一直有个观点,应用运行在Servlet容器中,因为从Servlet容器与Web应用的使用方式来看,确实很有这种感觉. 我们每次都是启动Servlet容器,然后再启动我们的应用 ...
- keras数据集读取
from tensorflow.python import keras (x_train,y_train),(x_test,y_test) = keras.datasets.cifar100.load ...
- Unity 极简UI框架
写ui的时候一般追求控制逻辑和显示逻辑分离,经典的类似于MVC,其余大多都是这个模式的衍生,实际上书写的时候M是在整个游戏的底层,我更倾向于将它称之为D(Data)而不是M(Model),而C(Ctr ...
- java关于throw Exception的一个小秘密
目录 简介 throw小诀窍 总结 java关于throw Exception的一个小秘密 简介 之前的文章我们讲到,在stream中处理异常,需要将checked exception转换为unche ...
- 在Spring Boot中使用内存数据库
文章目录 H2数据库 HSQLDB Apache Derby SQLite 在Spring Boot中使用内存数据库 所谓内存数据库就是可以在内存中运行的数据库,不需要将数据存储在文件系统中,但是相对 ...
- tcpdump常用抓包命令
主要语法 过滤主机/IP: tcpdump -i eth1 host 172.16.7.206 抓取所有经过网卡1,目的IP为172.16.7.206的网络数据 过滤端口: tcpdump -i ...