java8 新特性Stream流的应用
作为一个合格的程序员,如何让代码更简洁明了,提升编码速度尼。
今天跟着我一起来学习下java 8 stream 流的应用吧。
废话不多说,直入正题。
考虑以下业务场景,有四个人员信息,我们需要根据性别统计人员的姓名。
package com; import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map; public class Test {
public static void main(String[] args) { List<Map<String, String>> list = new ArrayList<>();
Map<String, String> map = new HashMap<>();
map.put("userName", "张三");
map.put("age", "18");
map.put("sex", "男");
list.add(map); Map<String, String> map1 = new HashMap<>();
map1.put("userName", "李四");
map1.put("age", "20");
map1.put("sex", "女");
list.add(map1); Map<String, String> map2 = new HashMap<>();
map2.put("userName", "王五");
map2.put("age", "15");
map2.put("sex", "女");
list.add(map2); Map<String, String> map3 = new HashMap<>();
map3.put("userName", "若风");
map3.put("age", "23");
map3.put("sex", "男");
list.add(map3); //现在我们要根据性别统计人员的姓名
//初级写法
StringBuilder stringBuilder1 = new StringBuilder();
StringBuilder stringBuilder2 = new StringBuilder();
for (Map<String, String> item : list) {
//指向当前下标的map
System.out.println("item: " + item);
if (item.get("sex").equals("男")) {
//存性别为男的人员名称,以逗号隔开
stringBuilder1.append(item.get("userName")).append(",");
} else {
//存性别为女的人员名称,以逗号隔开
stringBuilder2.append(item.get("userName")).append(",");
}
}
//去掉最后一个逗号
String userName_nan = stringBuilder1.deleteCharAt(stringBuilder1.length() - 1).toString();
String userName_nv = stringBuilder2.deleteCharAt(stringBuilder2.length() - 1).toString();
System.out.println("userName_nan: " + userName_nan);
System.out.println("userName_nv: " + userName_nv);
}
}
打印记录如下:
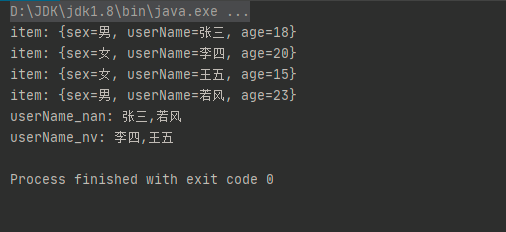
是不是感觉代码写的不怎么优雅,那么我们开始换个姿势,用java8 Stream 流的方式来操作。
package com; import org.apache.commons.lang.StringUtils; import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map; public class Test {
public static void main(String[] args) { List<Map<String, String>> list = new ArrayList<>();
Map<String, String> map = new HashMap<>();
map.put("userName", "张三");
map.put("age", "18");
map.put("sex", "男");
list.add(map); Map<String, String> map1 = new HashMap<>();
map1.put("userName", "李四");
map1.put("age", "20");
map1.put("sex", "女");
list.add(map1); Map<String, String> map2 = new HashMap<>();
map2.put("userName", "王五");
map2.put("age", "15");
map2.put("sex", "女");
list.add(map2); Map<String, String> map3 = new HashMap<>();
map3.put("userName", "若风");
map3.put("age", "23");
map3.put("sex", "男");
list.add(map3); //现在我们要根据性别统计人员的姓名
//初级写法
// StringBuilder stringBuilder1 = new StringBuilder();
// StringBuilder stringBuilder2 = new StringBuilder();
// for (Map<String, String> item : list) {
// //指向当前下标的map
// System.out.println("item: " + item);
// if (item.get("sex").equals("男")) {
// //存性别为男的人员名称,以逗号隔开
// stringBuilder1.append(item.get("userName")).append(",");
// } else {
// //存性别为女的人员名称,以逗号隔开
// stringBuilder2.append(item.get("userName")).append(",");
// }
// }
// //去掉最后一个逗号
// String userName_nan = stringBuilder1.deleteCharAt(stringBuilder1.length() - 1).toString();
// String userName_nv = stringBuilder2.deleteCharAt(stringBuilder2.length() - 1).toString();
// System.out.println("userName_nan: " + userName_nan);
// System.out.println("userName_nv: " + userName_nv); //java8 stream流的写法
//先定义一个Map 用来存储我们的人员姓名
Map<String, String> userNameMap = new HashMap<>(4);
//装逼开始
//
list.stream().map(v1 -> {
//map 可以理解为new 一个新的对象,复制原来list的数据copy 到一个新的List ,用map对数据进行修改操作时,不会改变原来的对象。需要返回值!!!
//v1指向当前下标的map对象
System.out.println("v1: " + v1);
//定义一个新的map 用来存储人员的姓名和性别
Map<String, String> data = new HashMap<>();
map.put("userName", v1.get("userName"));
map.put("sex", v1.get("sex"));
return map;
}).reduce(userNameMap, (a, b) -> {
//a 可以理解为上一次循环的返回结果
//b 当前的循环对象
//取出当前循环的人员姓名
String thisUserName = b.get("userName");
//取出当前循环的人员性别
String thisSex = b.get("sex");
if (thisSex.equals("男")) {
//取上一次循环的返回结果,第一次循环,是没有值的,第二次循环时,取得是第一次循环的返回结果,以此类推。
String val = a.get("newMenUserName");
System.out.println("val: " + val);
//第一次循环时val 是没有值的,我们赋值一个空的字符串,
// 第二次循环时,把第一次循环的返回的newUserName的值取出来,加上逗号,拼接当前下标的人员姓名
String newUserName = (StringUtils.isBlank(val) ? StringUtils.EMPTY : val + ",") + thisUserName;
//把拼接好的人员姓名添加到map 中
System.out.println("newUserName: " + newUserName);
a.put("newMenUserName", newUserName);
} else {
//取上一次循环的返回结果,第一次循环,是没有值的,第二次循环时,取得是第一次循环的返回结果,以此类推。
String val = a.get("newWomenUserName");
System.out.println("val: " + val);
//第一次循环时val 是没有值的,我们赋值一个空的字符串,
// 第二次循环时,把第一次循环的返回的newUserName的值取出来,加上逗号,拼接当前下标的人员姓名
String newUserName = (StringUtils.isBlank(val) ? StringUtils.EMPTY : val + ",") + thisUserName;
System.out.println("newUserName: " + newUserName);
//把拼接好的人员姓名添加到map 中
a.put("newWomenUserName", newUserName);
}
//返回当前循环的map
return a;
});
System.out.println("userNameMap: " + userNameMap);
System.out.println("userName_nan: " + userNameMap.get("newMenUserName"));
System.out.println("userName_nv: " + userNameMap.get("newWomenUserName")); }
}
打印的值如下:
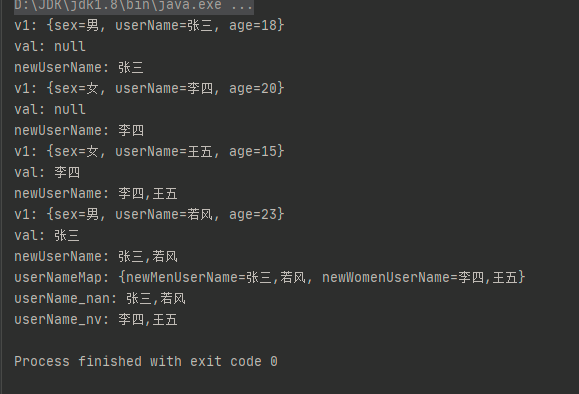
场景二、取两个List 的交集
package com; import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors; public class Test {
public static void main(String[] args) { // 业务场景2:取出两个List 的数值相同的元素(交集)
List<Integer> list1=new ArrayList<>();
list1.add(1);
list1.add(2);
list1.add(3);
list1.add(4);
List<Integer> list2=new ArrayList<>();
list2.add(2);
list2.add(4);
//交集
List<Integer> list3=new ArrayList<>();
//初级写法
for(Integer item:list1){
if(list2.contains(item)){
list3.add(item);
}
}
System.out.println("for循环的结果");
System.out.println("list3: "+list3); System.out.println("------------------------------------------------------------"); //stream 流的写法
//v1 表示当前下标的对象
//filter 过滤掉结果为false 的数据
list3=list1.stream().filter(v1->list2.contains(v1)).collect(Collectors.toList());
System.out.println("stream循环的结果");
System.out.println("list3: "+list3); //list 本身的方法
System.out.println("------------------------------------------------------------");
System.out.println("old 数据,list1:"+list1);
System.out.println("old 数据,list2:"+list2);
list1.retainAll(list2);
System.out.println("new 数据,list1"+list1);
System.out.println("new 数据,list2"+list2);
}
}
打印结果:
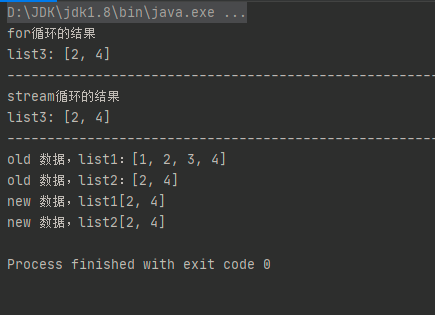
场景三、对一个List 排序
package com; import java.util.*;
import java.util.stream.Collectors; public class Test {
public static void main(String[] args) { // 业务场景3:对List 排序
List<Map<String, String>> list = new ArrayList<>();
Map<String, String> map = new HashMap<>();
map.put("userName", "张三");
map.put("age", "18");
map.put("sex", "男");
list.add(map); Map<String, String> map1 = new HashMap<>();
map1.put("userName", "李四");
map1.put("age", "20");
map1.put("sex", "女");
list.add(map1); Map<String, String> map2 = new HashMap<>();
map2.put("userName", "王五");
map2.put("age", "15");
map2.put("sex", "女");
list.add(map2); Map<String, String> map3 = new HashMap<>();
map3.put("userName", "若风");
map3.put("age", "23");
map3.put("sex", "男");
list.add(map3); //stream 流的写法
System.out.println("------------------------排序前--------------------------------");
System.out.println("排序前,List :"+list);
//sorted stream排序,这里我们根据年龄和姓名进行排序
//Test::age Java 8 中我们可以通过 `::` 关键字来访问类的构造方法,对象方法,静态方法。
//装逼开始
List<Map<String, String>> list2=list.stream().sorted(Comparator.comparing(Test::age).thenComparing(Comparator.comparing(Test::userName))).collect(Collectors.toList());
System.out.println();
System.out.println("------------------------排序后--------------------------------");
System.out.println("排序后,list2 :"+list2);
}
private static String userName(Map<String,String> map){
return map.get("userName");
}
private static Integer age(Map<String,String> map){
return Integer.parseInt(map.get("age"));
}
}
打印结果:

总结:
2、这些操作是惰性的,即每当访问到流中的一个元素,才会在此元素上执行这一系列操作。
3、Stream不保存数据,故每个Stream流只能使用一次。
1、filter(Predicate)
将结果为false的元素过滤掉,不会改变原来对象的数据,需要显示指定返回值!!!
2、map(fun)
把对象copy到一个新的对象中,遍历新的对象,对数据进行修改不会改变原来对象的数据,需要显示指定返回值!!!
3、flatMap(fun)
若元素是流,将流摊平为正常元素,再进行元素转换
4、limit(n)
保留前n个元素
5、 skip(n)
跳过前n个元素
6、distinct()
剔除重复元素
7、sorted(Comparator)
将流元素按Comparator排序
8、peek(fun)
流不变,但会把每个元素传入fun执行,可以用作调试
9、forEach()
遍历当前对象,对数据进行修改时,会改变对象的数据,不需要显示指定返回值!!!(注意和map的区别)
约简操作
取最大值
2、min(Comparator)
取最小值
3、 count()
去和
4、findFirst()
返回第一个元素
5、 findAny()
返回任意元素
6、anyMatch(Predicate)
任意元素匹配时返回true
7、allMatch(Predicate)
所有元素匹配时返回true
8、noneMatch(Predicate)
没有元素匹配时返回true
9、reduce(fun)
从流中计算某个值,接受一个二元函数作为累积器,从前两个元素开始持续应用它,累积器的中间结果作为第一个参数,流元素作为第二个参数
10、 reduce(a, fun)
a为幺元值,作为累积器的起点
11、reduce(a, fun1, fun2)
与二元变形类似,并发操作中,当累积器的第一个参数与第二个参数都为流元素类型时,可以对各个中间结果也应用累积器进行合并,但是当累积器的第一个参数不是流元素类型而是类型T的时候,各个中间结果也为类型T,需要fun2来将各个中间结果进行合并(参考场景一)
三、stream流的收集操作:
1、Collectors.toList()
2、Collectors.toSet()
3、Collectors.toCollection(集合的构造器引用)
4、Collectors.joining()、Collectors.joining(delimiter)、Collectors.joining(delimiter、prefix、suffix)
字符串元素连接
5、Collectors.summarizingInt/Long/Double(ToInt/Long/DoubleFunction)
产生Int/Long/DoubleSummaryStatistics对象,它有getCount、getSum、getMax、getMin方法,注意在没有元素时,getMax和getMin返回Integer/Long/Double.MAX/MIN_VALUE
6、Collectors.toMap(fun1, fun2)/toConcurrentMap
两个fun用来产生键和值,若值为元素本身,则fun2为Function.identity()
7、Collectors.toMap(fun1, fun2, fun3)/toConcurrentMap
fun3用于解决键冲突,例如(oldValue, newValue) -> oldValue,有冲突时保留原值
8、Collectors.toMap(fun1, fun2, fun3, fun4)/toConcurrentMap
默认返回HashMap或ConcurrentHashMap,fun4可以指定返回的Map类型,为对应的构造器引元
9、Collectors.groupingBy(fun)/groupingByConcurrent(fun)
fun是分类函数,生成Map,键是fun函数结果,值是具有相同fun函数结果元素的列表
10、Collectors.partitioningBy(fun)
键是true/false,当fun是断言函数时用此方法,比groupingBy(fun)更高效
11、Collectors.groupingBy(fun1, fun2)
fun2为下游收集器,可以将列表转换成其他形式,例如toSet()、counting()、summingInt/Long/Double(fun)、maxBy(Comparator)、minBy(Comparator)、mapping(fun1, fun2)(fun1为转换函数,fun2为下游收集器)
参考: https://blog.csdn.net/lixiaobuaa/article/details/81099838
java8 新特性Stream流的应用的更多相关文章
- 这可能是史上最好的 Java8 新特性 Stream 流教程
本文翻译自 https://winterbe.com/posts/2014/07/31/java8-stream-tutorial-examples/ 作者: @Winterbe 欢迎关注个人微信公众 ...
- Java8新特性 Stream流式思想(二)
如何获取Stream流刚开始写博客,有一些不到位的地方,还请各位论坛大佬见谅,谢谢! package cn.com.zq.demo01.Stream.test01.Stream; import org ...
- Java8新特性Stream流应用示例
Java8新特性介绍 过滤集合 List<String> newList = list.stream().filter(item -> item != null).collect(C ...
- Java8新特性 Stream流式思想(一)
遍历及过滤集合中的元素使用传统方式遍历及过滤集合中的元素package cn.com.zq.demo01.Stream.test01.Stream; import java.util.ArrayLis ...
- Java8新特性 Stream流式思想(三)
Stream接口中的常用方法 forEach()方法package cn.com.cqucc.demo02.StreamMethods.Test02.StreamMethods; import jav ...
- Java8 新特性 —— Stream 流式编程
本文部分摘自 On Java 8 流概述 集合优化了对象的存储,大多数情况下,我们将对象存储在集合是为了处理他们.使用流可以帮助我们处理对象,无需迭代集合中的元素,即可直接提取和操作元素,并添加了很多 ...
- Java8新特性——stream流
一.基本API初探 package java8.stream; import java.util.Arrays; import java.util.IntSummaryStatistics; impo ...
- java8 新特性 Stream流 分组 排序 过滤 多条件去重
private static List<User> list = new ArrayList<User>(); public static void main(String[] ...
- Java8 新特性 Stream 无状态中间操作
无状态中间操作 Java8 新特性 Stream 练习实例 中间无状态操作,可以在单个对单个的数据进行处理.比如:filter(过滤)一个元素的时候,也可以判断,比如map(映射)... 过滤 fil ...
随机推荐
- STL入门大全(待编辑)
前言:这个暑假才接触STL,仿佛开启了新世界的大门(如同学完结构体排序一般的快乐\(≧▽≦)/),终于彻底领悟了大佬们说的“STL大法好”(虽然我真的很菜www现在只学会了一点点...)这篇blog主 ...
- 对 ThreadLocal 的了解(一)
Threadlocal ThreadLocal 在我个人理解范围内,主要作用是在同一个线程里面,去共享某个数据给这个线程在不同的阶段去使用. 本次使用范围 在集成 pageOffice 在线 word ...
- 桌面上的Flutter:Electron又多了个对手
从本质上看,Flutter是一个独立的二进制可执行文件.它不仅改变了移动设备的玩法,在桌面设备上也同样不可小觑.一次编写,可在Android.iOS.Windows.Mac和Linux上进行原生部署, ...
- Redis(二):单机数据库的实现
概要 本部分内容主要是研究单机数据库.分别介绍单机数据库的实现原理,数据库的持久化,Redis事件,服务器维护管理客户端以及单机服务器的运作机制. 数据库 数据库结构 Redis数据库由redis.h ...
- flask学习笔记(二)
一.视图函数的传参方式 修改前: 目标: 传参方式改成 途径: 通过request获取参数 注意:args并不是地点类型,而是dict的一个子类,如图: immutable意思是不可变 不可变的字典转 ...
- pfSense®2.4.4发布后,原pfSense 黄金会员的服务将免费使用!
2018年7月16日,Doug McIntire 从即将发布的pfSense®2.4.4开始,之前在"pfSense Gold"下提供的所有服务都将继续,但所有pfSense用户都 ...
- How to get binary string from ArrayBuffer?
https://stackoverflow.com/questions/16363419/how-to-get-binary-string-from-arraybuffer https://stack ...
- 图论--最长路--基于SPFA的调整模板
#include<iostream> #include<queue> #include<algorithm> #include<set> #includ ...
- 网络流--最大流--EK模板
#include <iostream> #include <cstdio> #include <cstring> #include <cmath> #i ...
- [bzoj5329] P4606 [SDOI2018]战略游戏
P4606 [SDOI2018]战略游戏:广义圆方树 其实会了圆方树就不难,达不到黑,最多算个紫 那个转换到圆方树上以后的处理方法,画画图就能看出来,所以做图论题一定要多画图,并把图画清楚点啊!! 但 ...