《机器学习_08_代价敏感学习_添加sample_weight支持》
简介
这一节主要是为模型打补丁,在这之前笔者已经介绍并实现了几种典型的机器学习模型,比如线性回归、logistic回归、最大熵、感知机、svm等,但目前它们都有一个共性,那就是构造的损失函数对每个样本都是“一视同仁”的,即每个样本在损失函数中权重都是一样的,为了方便,可以将它们的损失函数做如下抽象:
\]
这里\(L(\cdot)\)表示整体的损失函数,\(l(w,x_i,y_i)\)表示第\(i\)个样本的损失函数,样本量为\(N\),对具体情况有:
线性回归有:
\]
对logistic回归:
\]
对感知机:
\]
对最大熵模型:
\]
对svm:
\]
代价敏感
如果对所有样本的损失函数都考虑一样的权重其实是有问题的,比如对于离群点、异常点这样的数据,其实可以忽略掉其损失函数;特别地,对于类别不平衡分类问题,我们可以给少数类样本更高的权重,而对于多数类更低的权重;另外对于像adaboost这样的集成学习方法,我们可以迭代调整每个样本点的权重以组合得到一个不错的强分类器;所以在损失函数中考虑样本权重,在某些场景下其实很有必要,简单来说考虑样本权重后,损失函数可以更新如下:
\]
这里\(\alpha_i\)表示样本\(i\)的权重
代码实现
代码实现其实很easy,根据目前的情况可以分为两类:
(1)若采用的随机梯度下降,可以对每次更新时的梯度\(dw\)乘以\(\alpha_i\);
(2)若采用对偶方式求解,则对其拉格朗日乘子做调整
具体地,我们为fit函数添加一个参数sample_weight以指定每个样本的权重(对各模型的更新代码就不帖了,见ml_models),接下来我们用svm测试不平衡分类的效果
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
import numpy as np
import os
os.chdir('../')
from ml_models import utils
from ml_models.svm import SVC
%matplotlib inline
X, y = make_classification(n_samples=500, n_features=2,
n_informative=2,n_redundant=0,
n_repeated=0, n_classes=2,
n_clusters_per_class=1,weights=[0.05, 0.95],
class_sep=3,flip_y=0.05, random_state=0)
svc_without_sample_weight=SVC(kernel='rbf',gamma=2.0,tol=0.01)
svc_without_sample_weight.fit(X,y)
utils.plot_decision_function(X=X,y=y,clf=svc_without_sample_weight)
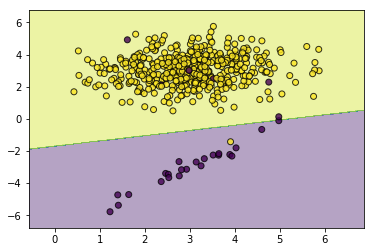
#然后我们加大少数类的权重
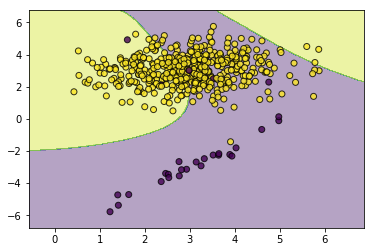
weights=np.where(y==0,20,1)
svc_with_sample_weight=SVC(kernel='rbf',gamma=2.0,tol=0.01)
svc_with_sample_weight.fit(X,y,sample_weight=weights)
utils.plot_decision_function(X=X,y=y,clf=svc_with_sample_weight)
《机器学习_08_代价敏感学习_添加sample_weight支持》的更多相关文章
- 简单物联网:外网访问内网路由器下树莓派Flask服务器
最近做一个小东西,大概过程就是想在教室,宿舍控制实验室的一些设备. 已经在树莓上搭了一个轻量的flask服务器,在实验室的路由器下,任何设备都是可以访问的:但是有一些限制条件,比如我想在宿舍控制我种花 ...
- 利用ssh反向代理以及autossh实现从外网连接内网服务器
前言 最近遇到这样一个问题,我在实验室架设了一台服务器,给师弟或者小伙伴练习Linux用,然后平时在实验室这边直接连接是没有问题的,都是内网嘛.但是回到宿舍问题出来了,使用校园网的童鞋还是能连接上,使 ...
- 外网访问内网Docker容器
外网访问内网Docker容器 本地安装了Docker容器,只能在局域网内访问,怎样从外网也能访问本地Docker容器? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Docker容器 ...
- 外网访问内网SpringBoot
外网访问内网SpringBoot 本地安装了SpringBoot,只能在局域网内访问,怎样从外网也能访问本地SpringBoot? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装Java 1 ...
- 外网访问内网Elasticsearch WEB
外网访问内网Elasticsearch WEB 本地安装了Elasticsearch,只能在局域网内访问其WEB,怎样从外网也能访问本地Elasticsearch? 本文将介绍具体的实现步骤. 1. ...
- 怎样从外网访问内网Rails
外网访问内网Rails 本地安装了Rails,只能在局域网内访问,怎样从外网也能访问本地Rails? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Rails 默认安装的Rails端口 ...
- 怎样从外网访问内网Memcached数据库
外网访问内网Memcached数据库 本地安装了Memcached数据库,只能在局域网内访问,怎样从外网也能访问本地Memcached数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装 ...
- 怎样从外网访问内网CouchDB数据库
外网访问内网CouchDB数据库 本地安装了CouchDB数据库,只能在局域网内访问,怎样从外网也能访问本地CouchDB数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Cou ...
- 怎样从外网访问内网DB2数据库
外网访问内网DB2数据库 本地安装了DB2数据库,只能在局域网内访问,怎样从外网也能访问本地DB2数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动DB2数据库 默认安装的DB2 ...
- 怎样从外网访问内网OpenLDAP数据库
外网访问内网OpenLDAP数据库 本地安装了OpenLDAP数据库,只能在局域网内访问,怎样从外网也能访问本地OpenLDAP数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动 ...
随机推荐
- 解决w3wp.exe占用CPU和内存问题
在WINDOWS2003+IIS6下,经常出现w3wp的内存占用不能及时释放,从而导致服务器响应速度很慢.可以做以下配置进行改善:1.在IIS中对每个网站进行单独的应用程序池配置.即互相之间不影响.2 ...
- mybatis源码学习(二):SQL的执行过程
从上一篇文章中,我们了解到MapperMethod将SQL的执行交给了sqlsession处理.今天我们继续往下看处理的过程. SqlSession接口除了提供获取Configuration,Mapp ...
- Blockchain
一.中心化 中心化原则是我们日常比较常见的支付手段. 科普文章喜欢用网购举例: 1.你在某宝支付了一件商品,钱先到马云爸爸手中,通知商家发货: 2.商家发货,你收货后确认无误,点击确认收货: 3.马云 ...
- 初识Matlab及界面认识
通过本章节的学习,需要掌握: MATLAB语言是什么 MATLAB在互联网语言中地位与应用 目标:利用MATLAB进行问题求解的基本规律.够使用MATLAB作为专业应用的工具. 1.什么叫计算? (1 ...
- 【FPGA篇章四】FPGA状态机:三段式以及书写方法
欢迎大家关注我的微信公众账号,支持程序媛写出更多优秀的文章 状态机是fpga设计中极其重要的一种技巧,状态机通过不同的状态迁移来完成特定的逻辑操作,掌握状态机的写法可以使fpga的开发事半功倍. 状态 ...
- k-modes聚类算法
为什么要用k-modes算法 k-means算法是一种简单且实用的聚类算法,但是传统的k-means算法只适用于连续属性的数据集(数值型数据),而对于离散属性的数据集,计算簇的均值以及点之间的欧式距离 ...
- linux centos7搭建redis-5.0.5
1. 下载redis 1.1 下载地址 http://download.redis.io/releases/ 1.2 安装版本 redis-5.0.5.tar.gz 2. 安装redis 2.1 前置 ...
- flink源码阅读
Flink面试--源码篇 1.Flink Job的提交流程? 2.Flink所谓"三层图"结构是哪几个"图"? 3.JobManger在集群中扮演了什么角色? ...
- Vue中跨域问题解决方案1
我们需要配置代理.代理可以解决的原因:因为客户端请求服务端的数据是存在跨域问题的,而服务器和服务器之间可以相互请求数据,是没有跨域的概念(如果服务器没有设置禁止跨域的权限问题),也就是说,我们可以配置 ...
- 手把手教系列之IIR滤波器设计
[导读]:在嵌入式系统中经常需要采集模拟信号,采集模拟信号的信号链中难免引入干扰,那么如何滤除干扰呢?今天就来个一步一步描述如何设计部署一个IIR滤波器到你的系统. 何为IIR滤波器? 无限冲激响应( ...