RANSAC随机一致性采样算法学习体会
The RANSAC algorithm is a learning technique to estimate parameters of a model by random sampling of observed data. Given a dataset whose data elements contain both inliers and outliers, RANSAC uses the voting scheme to find the optimal fitting result. Data elements in the dataset are used to vote for one or multiple models. The implementation of this voting scheme is based on two assumptions: that the noisy features will not vote consistently for any single model (few outliers) and there are enough features to agree on a good model (few missing data). The RANSAC algorithm is essentially composed of two steps that are iteratively repeated:
- In the first step, a sample subset containing minimal data items is randomly selected from the input dataset. A fitting model and the corresponding model parameters are computed using only the elements of this sample subset. The cardinality of the sample subset is the smallest sufficient to determine the model parameters.首先从输入数据中采集最小数据集,根据这个最小数据集计算相应的fitting模型参数。
- In the second step, the algorithm checks which elements of the entire dataset are consistent with the model instantiated by the estimated model parameters obtained from the first step. A data element will be considered as an outlier if it does not fit the fitting model instantiated by the set of estimated model parameters within some error threshold that defines the maximum deviation attributable to the effect of noise.接着,应用第一步中得到的模型参数,检查整个输入数据集,如果和模型不匹配则视为离群点。通过一定的容错阈值范围限制由于噪声引起的最大误差,
The set of inliers obtained for the fitting model is called consensus set.适用模型的群内点被称为一致集。
The RANSAC algorithm will iteratively repeat the above two steps until the obtained consensus set in certain iteration has enough inliers.算法将重复上面的2个步骤进行迭代,直到通过一定迭代得到的一致集包含足够多的群内点。
The input to the RANSAC algorithm is a set of observed data values, a way of fitting some kind of model to the observations, and some confidence parameters. RANSAC achieves its goal by repeating the following steps:
- Select a random subset of the original data. Call this subset the hypothetical inliers.
- A model is fitted to the set of hypothetical inliers.//计算模型参数
- All other data are then tested against the fitted model. Those points that fit the estimated model well, according to some model-specific loss function, are considered as part of the consensus set.
- The estimated model is reasonably good if sufficiently many points have been classified as part of the consensus set.
- Afterwards, the model may be improved by reestimating it using all members of the consensus set.
This procedure is repeated a fixed number of times, each time producing either a model which is rejected because too few points are part of the consensus set, or a refined model together with a corresponding consensus set size. In the latter case, we keep the refined model if its consensus set is larger than the previously saved model.
关于采样次数的推导
The values of parameters t and d have to be determined from specific requirements related to the application and the data set, possibly based on experimental evaluation. The parameter k (the number of iterations), however, can be determined from a theoretical result. Let p be the probability that the RANSAC algorithm in some iteration selects only inliers from the input data set when it chooses the n points from which the model parameters are estimated. When this happens, the resulting model is likely to be useful so p gives the probability that the algorithm produces a useful result. Let w be the probability of choosing an inlier each time a single point is selected, that is,
- w = number of inliers in data / number of points in data
A common case is that w is not well known beforehand, but some rough value can be given. Assuming that the n points needed for estimating a model are selected independently, 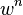 is the probability that all n points are inliers and
is the probability that all n points are inliers and 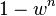 is the probability that at least one of the n points is an outlier, a case which implies that a bad model will be estimated from this point set. That probability to the power of k is the probability that the algorithm never selects a set of n points which all are inliers and this must be the same as
is the probability that at least one of the n points is an outlier, a case which implies that a bad model will be estimated from this point set. That probability to the power of k is the probability that the algorithm never selects a set of n points which all are inliers and this must be the same as 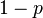 . Consequently,
. Consequently,

which, after taking the logarithm of both sides, leads to

This result assumes that the n data points are selected independently, that is, a point which has been selected once is replaced and can be selected again in the same iteration. This is often not a reasonable approach and the derived value for k should be taken as an upper limit in the case that the points are selected without replacement. For example, in the case of finding a line which fits the data set illustrated in the above figure, the RANSAC algorithm typically chooses two points in each iteration and computes maybe_model as the line between the points and it is then critical that the two points are distinct.
To gain additional confidence, the standard deviation or multiples thereof can be added to k. The standard deviation of k is defined as

RANSAC随机一致性采样算法学习体会的更多相关文章
- 过采样算法之SMOTE
SMOTE(Synthetic Minority Oversampling Technique),合成少数类过采样技术.它是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加 ...
- 一致性Hash算法(KetamaHash)的c#实现
Consistent Hashing最大限度地抑制了hash键的重新分布.另外要取得比较好的负载均衡的效果,往往在服务器数量比较少的时候需要增加虚拟节点来保证服务器能均匀的分布在圆环上.因为使用一般的 ...
- DSP算法学习-过采样技术
DSP算法学习-过采样技术 彭会锋 2015-04-27 23:23:47 参考论文: 1 http://wr.lib.tsinghua.edu.cn/sites/default/files/1207 ...
- Javascript经典算法学习1:产生随机数组的辅助类
辅助类 在几个经典排序算法学习部分,为方便统一测试不同算法,新建了一个辅助类,主要功能为:产生指定长度的随机数组,提供打印输出数组,交换两个元素等功能,代码如下: function ArraySort ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- 一致性哈希算法学习及JAVA代码实现分析
1,对于待存储的海量数据,如何将它们分配到各个机器中去?---数据分片与路由 当数据量很大时,通过改善单机硬件资源的纵向扩充方式来存储数据变得越来越不适用,而通过增加机器数目来获得水平横向扩展的方式则 ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
- 机器学习 —— 类不平衡问题与SMOTE过采样算法
在前段时间做本科毕业设计的时候,遇到了各个类别的样本量分布不均的问题——某些类别的样本数量极多,而有些类别的样本数量极少,也就是所谓的类不平衡(class-imbalance)问题. 本篇简述了以下内 ...
- MCMC等采样算法
一.直接采样 直接采样的思想是,通过对均匀分布采样,实现对任意分布的采样.因为均匀分布采样好猜,我们想要的分布采样不好采,那就采取一定的策略通过简单采取求复杂采样. 假设y服从某项分布p(y),其累积 ...
随机推荐
- git统计报告
2016年10月30日--2016年11月9日
- spring aop中的propagation的7种配置的意思
1.前言. 在声明式的事务处理中,要配置一个切面,即一组方法,如 <tx:advice id="txAdvice" transaction-manager="txM ...
- MySQL 数据库设计 笔记与总结(1)需求分析
数据库设计的步骤 ① 需求分析 ② 逻辑设计 使用 ER 图对数据库进行逻辑建模 ③ 物理设计 ④ 维护优化 a. 新的需求进行建表 b. 索引优化 c. 大表拆分 [需求分析] ① 了解系统中所要存 ...
- 使用 PHP 限制下载速度
使用 PHP 限制下载速度 [来源] 达内 [编辑] 达内 [时间]2012-12-12 经常遇到一个问题,那就是有人再办公室下载东西,影响大家上网.办公.同样的问题,要是出现在了服务器上面 ...
- PHP pear安装
PHP pear安装 Posted on 2012-07-06 10:19 bug yang 阅读(5787) 评论(0) 编辑 收藏 转自:http://wangye.org/blog/archiv ...
- Latex公式换行、对齐
http://blog.sina.com.cn/s/blog_64827e4c0100vnqu.html 换行后等式对齐 \begin{equation}\begin{aligned}R(S_2)&a ...
- mysql的事务和select...for update
一.mysql的事务mysql的事务有两种方式:1.SET AUTOCOMMIT=0;也就是关闭了自动提交,那么任何commit或rollback语句都可以触发事务提交;如果SET AUTOCOMMI ...
- linux下利用curl监控网页shell脚本
#!/bin/bash smail() {mail -s "$1" gjw_apparitor@gmail.com <<EOF$1$2====report time: ...
- Andrew Ng机器学习公开课笔记–Reinforcement Learning and Control
网易公开课,第16课 notes,12 前面的supervised learning,对于一个指定的x可以明确告诉你,正确的y是什么 但某些sequential decision making问题,比 ...
- IOS 跳转时传参数的常用方法
在iOS开发中常用的参数传递有以下几种方法: 采用代理模式 采用iOS消息机制 通过NSDefault存储(或者文件.数据库存储等) 通过AppDelegate定义全局变量(或者使用UIApplica ...