数据库优化和SQL操作的相关题目
SQL操作
1.有一个数据库表peope,表有字段name,age,address三个属性(注:没有主键)。现在如果表中有重复的数据,请删去重复只留下其中的一条。重复的定义就是两条记录的name,age,address值都一样。
关键是怎么把重复的数据过滤掉,后来我考虑的做法是这样的:
|
1
2
3
4
5
6
7
|
select * from people group by name,age,address having COUNT(DISTINCT name)=1这样就可以把重复的数据过滤掉,然后把这些数据插入到一个临时表中,删去原表中的所有数据,再把临时表中的数据插回来就可以了。CREATE TEMPORARY TABLE tmp_table select * from people group by name,age,address having COUNT(DISTINCT name)=1delete from peopleinsert into people select * from tmp_table |
2.有如下的部门员工表:
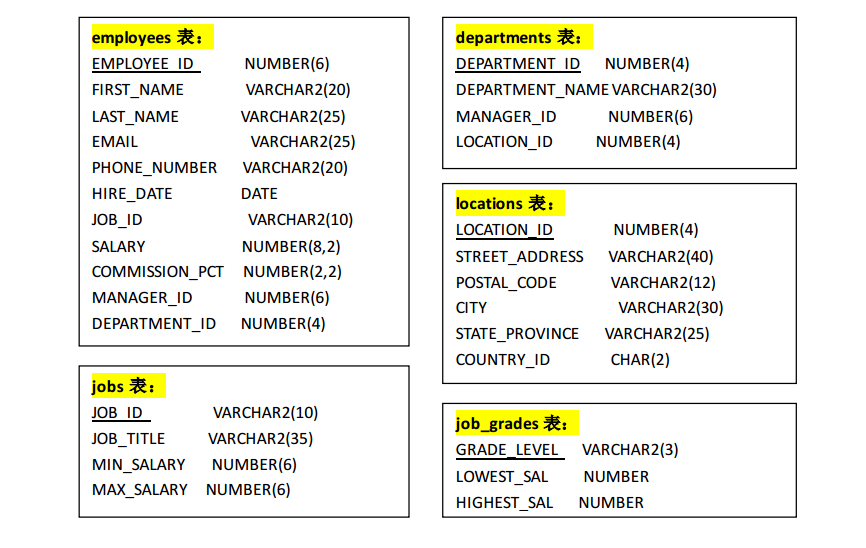
1.查询每个月倒数第 2 天入职的员工的信息.
2.查询出last_name为 ‘Chen’ 的 manager 的信息.
3.查询平均工资高于 8000 的部门 id 和它的平均工资.
4. 查询工资最低的员工信息: last_name, salary
5. 查询平均工资最低的部门信息
6. 查询平均工资最低的部门信息和该部门的平均工资
7. 查询平均工资最高的 job 信息
8. 查询平均工资高于公司平均工资的部门有哪些?
9. 查询出公司中所有 manager 的详细信息.
10. 各个部门中最高工资中最低的那个部门的最低工资是多少
11. 查询平均工资最高的部门的 manager 的详细信息: last_name, department_id, email, salary
12. 查询 1999 年来公司的人所有员工的最高工资的那个员工的信息.
13.返回其它部门中比job_id为‘IT_PROG’部门所有工资都低的员工的员工号、姓名、job_id以及salary
3.sql查询Oracle数据库最后10条记录并按降序排列。
SELECT TOP 10 FROM 表名 ORDER BY 排序列 DESC;
SQL的执行顺序先按照你的要求排序,然后才返回查询的内容。
例如有一个名为ID自动增长的列,表中有100条数据,列的值得分别是1、2、3、4………9、99、100。那么查询加了DESC你得到的是91到100条,就是最后十条,如果加ASC你得到的将会是1到10,也就是最前面的那几条记录,
如果说有先后的话 必然是根据某几个字段进行排序了的你反过来排序就变成求前10条记录了呗,把desc和 asc互换一下 (默认是 asc )oracle 的写法select * from (select * from tab order by col desc ) where rownum <= 10
最后10条降序与最前10条升序是一样的如果还想排序,那就按他们说的用临时表。
|
1
2
3
|
select top 10 * from table 1 order by field1 into table #tempselect * from #temp order by field1 desc //查询结果放临时表select * top 10 from table1 order by field1 asc into tabl temp //再从临时表查询select * from temp order by field1 desc |
数据库优化
1.假设有一亿个用户,每个用户至少关注100个人,如何设计数据库(关系型数据库)满足下面几个需求
1,查找a关注了哪些人
2,查找a被哪些人关注了
3,查找a和b共同关注了哪些人
2.数据库commit操作是否应该在一个大事务中实现,也就是一个大事务只有一个commit?
使用一个大事务来实现批量数据库操作,虽然回退和重提非常方便,但是不利于批量数据操作出现异常时的处理和时间要求。如果批量数据处理在最后一步运行缓慢或失败,那么事务回退时间将非常长,重新运行需要从头开始跑整个事务,可能无法满足有限的批量数据操作时间窗口要求
Oracle数据库的情况下,大事务操作需要设置足够大的undo表空间,insert操作要大于数据大小的一倍;update,delete操作要大于数据大小的两倍。另外还需要兼顾其他操作的消耗。
如果分批操作会影响业务完整性,则没必要分批进行,而且也不建议去故意分批进行操作,只需要保证有足够大的undo表空间。
3.数据库中记录较多,有20万条左右,需要反复查询记录匹配数据,如何做能提高算法效率,节省查询时间?
1,优化查询语句,避免全表扫描
2,引入缓存策略,尽量避免访问数据库
3,合理建立索引
4,避免SQL语句中不合理的连接和嵌套等
4.SQL语句优化的策略都有哪些?
创建表的时候。应尽量建立主键,根据主键查询数据;
●大数据表删除,用truncate table代替delete。
●合理使用索引,在OLTP应用中一张表的索引不要太多。组合索引的列顺序尽量与查询条件列顺序保持一致;对于数据操作频繁的表,索引需要定期重建,以减少失效的索引和碎片。
●查询尽量用确定的列名,少用*号。
尽量少嵌套子查询,这种查询会消耗大量的CPU资源;对于有比较多
or运算的查询,建议分成多个查询,用union all联结起来;多表查询
的查询语句中,选择最有效率的表名顺序(基于规则的优化器中有效)。Oracle解析器对表解析从右到左,所以记录少的表放在右边。
尽量多用commit语句提交事务,可以及时释放资源、解
锁、释放日志空间、减少管理花费;在频繁的、性能要求比较高的
数据操作中,尽量避免远程访问,如数据库链等,访问频繁的表可
以常驻内存:alter table...cache;
利用索引,避免大表FULL TABLE SCAN;
合理使用临时表;
避免写过于复杂的sql,不一定非要一个sql解决问题;
在不影响业务的前提下减小事务的粒度;
5.大量数据并发的情况下 ,不用自增列 怎样设置主键?
1:定义一张表,专门用来存放存所有需要唯一ID的表名称以及该表当前所使用到的ID值。
2: 写一个存储过程,专门用来在上一步的表中取ID值。
数据库优化和SQL操作的相关题目的更多相关文章
- mysql优化-数据库优化、SQL优化
我有一张表w1000,里面有1000万条数据,这张表结构如下:CREATE TABLE `w1000` ( `id` varchar(36) NOT NULL, `name` varchar(10) ...
- 数据库优化系列——SQL性能优化十条建议
1.查询的模糊匹配 尽量避免在一个复杂查询里面使用 LIKE '%parm1%'—— 红色标识位置的百分号会导致相关列的索引无法使用,最好不要用. 解决办法: 其实只需要对该脚本略做改进,查询速度便 ...
- 数据库优化之SQL语句优化-记录
1. 操作符优化 (a) IN 操作符 从Oracle执行的步骤来分析用IN的SQL与不用IN的SQL有以下区别: ORACLE试图将其转换成多个表的连接,如果转换不成功则先执行IN里面的子查询,再查 ...
- 数据库笔记--常见sql操作
1.数据库联表查询: 在实际项目中有时需要将两个表结合到一起进行查询,此处介绍其语法: 左连接查询:select * from tableA left join tableB on tableA.fi ...
- Mysql数据库优化之SQL及索引优化
1. 如何发现有问题的SQL? 使用mysql慢查询日志对有效率问题的Sql进行监视 (1) show variables like 'slow_query_log'; 查看慢查询日志是否 ...
- [Sqlite] 移动嵌入式数据库Sqlite日报SQL操作语句汇总
,EXPLAIN分析 没有建立索引之前.分析都是表扫描: sqlite> EXPLAIN SELECT * FROM COMPANY WHERE Salary < 20000; add ...
- 常用SQL操作(MySQL或PostgreSQL)与相关数据库概念
本文对常用数据库操作及相关基本概念进行总结:MySQL和PostgreSQL对SQL的支持有所不同,大部分SQL操作还是一样的. 选择要用的数据库(MySQL):use database_name; ...
- 面试问题之数据库:SQL优化的具体操作
转载于:https://www.cnblogs.com/wangzhengyu/p/10412499.html SQL优化的具体操作: 1.尽量避免使用select *,返回无用的字段会降低查询效率. ...
- Oracle数据库该如何着手优化一个SQL
这是个终极问题,因为优化本身的复杂性实在是难以总结的,很多时候优化的方法并不是用到了什么高深莫测的技术,而只是一个思想意识层面的差异,而这些都很可能连带导致性能表现上的巨大差异. 所以有时候我们应该先 ...
随机推荐
- linux 搭建SVN服务器,为多个项目分别建立版本库并单独配置权限
1.安装svn服务 # yum install subversion 2.新建一个目录用于存储SVN所有文件 # mkdir /home/svn 3.在上面创建的文件夹中为项目 p ...
- python 与 mysql
1.开发环境: 1)CLion-2016.1.3 C/C++ 与 Python 混合编程 IDE,先安装好以下 2) 3) 编译器再关联 2)tdm-gcc-4.8.1-3 C/C++ 编译器 3)W ...
- [LeetCode] Binary Tree Preorder/Inorder/Postorder Traversal
前中后遍历 递归版 /* Recursive solution */ class Solution { public: vector<int> preorderTraversal(Tree ...
- XSS 自动化检测 Fiddler Watcher & x5s & ccXSScan 初识
一.标题:XSS 自动化检测 Fiddler Watcher & x5s & ccXSScan 初识 automated XSS testing assistant 二.引言 ...
- Windows 下安装项目管理工具 Redmine 1.1.2
1.InstantRails-2.0-win 下载地址 https://rubyforge.org/frs/?group_id=904 2.redmine1.1.2 下载地址 http://www ...
- springmvc中@PathVariable和@RequestParam的区别(百度收集)
http://localhost:8080/Springmvc/user/page.do?pageSize=3&pageNow=2 你可以把这地址分开理解,其中问号前半部分:http://lo ...
- linux cp命令参数及用法详解
cp (复制档案或目录)[root@linux ~]# cp [-adfilprsu] 来源档(source) 目的檔(destination)[root@linux ~]# cp [options] ...
- CSS包含块containing block详解
“包含块(containing block)”,W3c中一个很重要的概念,今天带大家一起来好好研究下. 初步理解 在 CSS2.1 中,很多框的定位和尺寸的计算,都取决于一个矩形的边界,这个矩形,被称 ...
- JVM<一>----------运行时数据区域
参考:1.JVM Specification: http://docs.oracle.com/javase/specs/jvms/se7/html/jvms-2.html#jvms-2.5 2.< ...
- linux查看python安装路径,版本号
一.想要查看ubuntu中安装的Python路径 方法一:whereis python 方法二:which python 二.想要查看ubuntu中安装的python版本号 python