python大杂铺
python中continue,break,return三者之间的区别
return 会直接令函数返回,所有该函数体内的代码都不再执行了,所以该函数体内的循环也不可能再继续运行。
break:跳出所在的当前整个循环,到外层代码继续执行。
continue:跳出本次循环,从下一个迭代继续运行循环,内层循环执行完毕,外层代码继续运行。
import time
while True:
time.sleep(0.5) #可简单理解为程序休止一秒
print("执行了")
continue # 结束本次循环,进行下次循环
print("没有执行")#不会执行
continue
def say_hello():
print("No Hello!")
return #可以加返回值
print("Can not say hello") #不会执行 say_hello()
return
while True:
print("执行了")
break # 跳出当前循环
print("没有执行") #不会执行
print("OVER!!!")
break
深浅copy:
1.copy.copy 浅拷贝 只拷贝父对象,不会拷贝对象的内部的子对象。
dic1 = {
'k1': 'v1',
'k2': [11]
}
dic2 = dic1.copy()
print(dic1,dic2)
print("********区分线********")
dic1['k2'].append(66)
print(dic1,dic2)
输出:
可看到,浅拷贝后再次对原数据(dic1)更改时,新的数据也会发生更改(dic2会随之更改)
2. copy.deepcopy() 深拷贝,拷贝对象及其子孙对象
dic1 = {
'k1': 'v1',
'k2': [11,22,33,44]
}
import copy
dic2 = copy.deepcopy(dic1)
print(dic1,dic2)
dic1['k2'].append(666)
print(dic1,dic2)
深copy时,dic1有两层对象,可以理解为父对象和子孙对象;一层是'k1'(key1): 'v1'(value1),'k2'(key2):[11,22,33,44] (value2),而value2又是一层对象(子对象)
输出:
总结:
deepcopy : 即深拷贝,与我们寻常理解的拷贝的意义相同,拷贝原数据,形成新的相同数据,并且两份数据保持独立,没有关联关系。
copy: 即浅拷贝,拷贝原数据,实际上是给原数据贴上新的标签,都是指向同一对象。既然两个数据是指向相同对象,当其中一个数据做出修改,另一个数据也随之改变。
参考:https://www.cnblogs.com/wujiaqing/p/11024382.html
enumerate函数
描述:
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,
同时列出数据和数据下标,一般用在 for 循环当中。
语法:
enumerate(sequence, [start=0])
sequence :一个序列、迭代器或其他支持迭代对象。
start :下标起始位置。
实例:
# _*_coding:utf-8_*_
'''
需求a = [1,2,3,4,5,6,7,8,9],把列表中的值加一 方法? '''
#方法: # 方法1:
'''
a = [1,2,3,4,5,6,7,8,9]
b = []
for i in a:
b.append(i+1)
a = b
print(a)
''' #方法2:
'''
a = [1,2,3,4,5,6,7,8,9]
b =map(lambda x:x+1,a)
for i in b:
print(i) '''
#方法3:
'''
a = [1,2,3,4,5,6,7,8,9]
for index,value in enumerate(a):
a[index] += 1
# print(i,index)
print(a) '''
#方法4:
'''
a = [1,2,3,4,5,6,7,8,9]
a = [i+1 for i in a]
print(a) '''
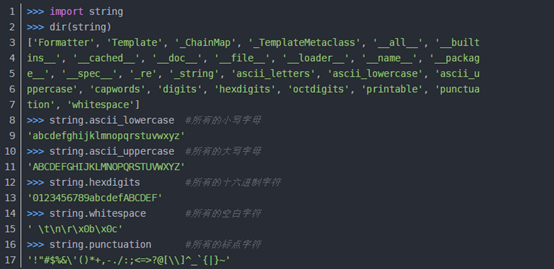
去掉string(英文状态)的标点符号

python大杂铺的更多相关文章
- Python 10 —— 杂
Python 10 —— 杂 科学计算 NumPy:数组,数组函数,傅里叶变换 SciPy:依赖于NumPy,提供更多工具,比如绘图 绘图 Matplitlib:依赖于NumPy和Tkinter
- python大数据工作流程
本文作者:hhh5460 大数据分析,内存不够用怎么办? 当然,你可以升级你的电脑为超级电脑. 另外,你也可以采用硬盘操作. 本文示范了硬盘操作的一种可能的方式. 本文基于:win10(64) + p ...
- 2 python大数据挖掘系列之淘宝商城数据预处理实战
preface 在上一章节我们聊了python大数据分析的基本模块,下面就说说2个项目吧,第一个是进行淘宝商品数据的挖掘,第二个是进行文本相似度匹配.好了,废话不多说,赶紧上车. 淘宝商品数据挖掘 数 ...
- 《零起点,python大数据与量化交易》
<零起点,python大数据与量化交易>,这应该是国内第一部,关于python量化交易的书籍. 有出版社约稿,写本量化交易与大数据的书籍,因为好几年没写书了,再加上近期"前海智库 ...
- python大文件读取
python大文件读取 https://stackoverflow.com/questions/8009882/how-to-read-a-large-file-line-by-line-in-pyt ...
- 学习推荐《零起点Python大数据与量化交易》中文PDF+源代码
学习量化交易推荐学习国内关于Python大数据与量化交易的原创图书<零起点Python大数据与量化交易>. 配合zwPython开发平台和zwQuant开源量化软件学习,是一套完整的大数据 ...
- 零起点Python大数据与量化交易
零起点Python大数据与量化交易 第1章 从故事开始学量化 1 1.1 亿万富翁的“神奇公式” 2 1.1.1 案例1-1:亿万富翁的“神奇公式” 2 1.1.2 案例分析:Python图表 5 1 ...
- Python大数据与机器学习之NumPy初体验
本文是Python大数据与机器学习系列文章中的第6篇,将介绍学习Python大数据与机器学习所必须的NumPy库. 通过本文系列文章您将能够学到的知识如下: 应用Python进行大数据与机器学习 应用 ...
- 1 python大数据挖掘系列之基础知识入门
preface Python在大数据行业非常火爆近两年,as a pythonic,所以也得涉足下大数据分析,下面就聊聊它们. Python数据分析与挖掘技术概述 所谓数据分析,即对已知的数据进行分析 ...
随机推荐
- SVN的一些操作
一丶 .csproj文件夹必须提交 Revert Changes 撤销
- 数据结构与算法(6) -- heap
binary heap就是一种complete binary tree(完全二叉树).也就是说,整棵binary tree除了最底层的叶节点之外,都是满的.而最底层的叶节点由左至右又不得有空隙. 以上 ...
- do{}while(0)
有时会在源码中或在写代码时在宏定义中用到do...while(0). 采用这种方式进行宏定义, 主要是为了防止出现以下错误 : do{}while(0) 空的宏定义避免出现warnning. #def ...
- nexus3的安装和使用
参考:https://www.cnblogs.com/2YSP/p/9533506.html http://www.54tianzhisheng.cn/2017/10/14/Nexus3-Maven/ ...
- 20.混合使用match和近似匹配实现召回率与精准度的平衡
主要知识点: 召回率的慨念 精准度的慨念 match和近似匹配混合使用方法 召回率(recall):比如你搜索一个java spark,总共有100个doc,能返回多少个doc作为结果 ...
- 联想小新Air 15 安装黑苹果macOS High Sierra 10.13.6过程
联想小新Air 15 安装黑苹果全过程 本文参考:https://blog.csdn.net/qq_28735663/article/details/80634300 本人是联想小新AIr 15 , ...
- gitblit 搭建本地git服务器
本文主要描述gitblit搭建本地服务器
- python 简单爬取今日头条热点新闻(一)
今日头条如今在自媒体领域算是比较强大的存在,今天就带大家利用python爬去今日头条的热点新闻,理论上是可以做到无限爬取的: 在浏览器中打开今日头条的链接,选中左侧的热点,在浏览器开发者模式netwo ...
- Django REST framework - 版本控制
目录 Django REST framework 版本控制 为什么需要版本控制 DRF提供了5种版本控制方案 版本控制系统的使用 全局配置 局部配置 获取版本信息 Django REST framew ...
- 第二节:web爬虫之lxml解析库
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高.