python数据分析处理库-Pandas
1、读取数据
import pandas
food_info = pandas.read_csv("food_info.csv")
print(type(food_info)) # <class 'pandas.core.frame.DataFrame'>
2、数据类型
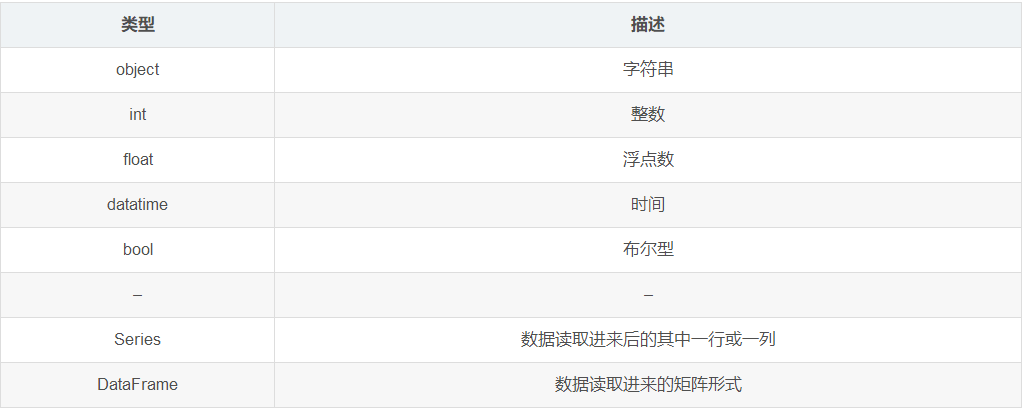
3、数据显示
food_info.head() # 显示读取数据的前5行
food_info.head(3) # 显示读取数据的前3行
food_info.tail(3) # 显示读取数据的后3行
food_info.columns # 列名
food_indo.shape # 数据规格
food_info.loc[0] # 第0行数据
food_info.loc[3:6] # 第3-6行数据
food_info.log[83,"NDB_No"] # 读取第83行的NDB_No数据
food_info["NDB_No"] # 通过列名读取列
columns = ["Zinc_(mg)", "Copper_(mg)"]
food_info[columns] # 读取多个列 # 读取单位为g的列
col_names = food_info.columns.tolist() # 列名
gram_columns = []
for c in col_names:
if c.endswith("(g)"):
gram_columns.append(c)
gram_df = food_info[gram_columns]
4、数据操作
# 对该列每一个值都除以1000,+-*同理
food_info["Iron_(mg)"] / 1000
# 维度相同的列对应元素相乘
water_energy = food_info["Water_(g)"] * food_info["Energ_Kcal"]
# 添加新的一列
iron_grams = food_info["Iron_(mg)"] / 1000
food_info["Iron_(g)"] = iron_grams
# 最大值
food_info["Energ_Kcal"].max()
# 排序 inplace-是否新生成一个DataFrame ascending-默认为True
food_info.sort_values("Sodium_(mg)", inplace=True, ascending=False)
# 将排序后的数据的索引值重置,生成新的索引
new_titanic_survival = titanic_survival.sort_values("Age",ascending=False)
new_titanic_survival.reset_index(drop=True)
5、缺失值处理
# 缺失值
pd.isnull(age)
titanic_survival["Age"].mean() # 去掉缺失值后的平均值 #去掉含有缺失值的数据
titanic_survival.dropna(axis=1) # 丢掉含有缺失值的列
titanic_survival.dropna(axis=0,subset=["Age", "Sex"]) # 丢掉"Age"与"Sex"中含有缺失值的行
6、简单的统计函数
# 统计在不同船舱中获救人数的平均值 aggfunc-默认为求均值
passenger_survival = titanic_survival.pivot_table(index="Pclass", values="Survived", aggfunc=np.mean)
7、自定义函数
# 返回行值
def hundredth_row(column):
# Extract the hundredth item
hundredth_item = column.loc[99]
return hundredth_item
hundredth_row = titanic_survival.apply(hundredth_row) # 置换列值
def which_class(row):
pclass = row['Pclass']
if pd.isnull(pclass):
return "Unknown"
elif pclass == 1:
return "First Class"
elif pclass == 2:
return "Second Class"
elif pclass == 3:
return "Third Class"
classes = titanic_survival.apply(which_class, axis=1)
8、Series结构
from pandas import Series
series_custom = Series(rt_scores , index=film_names)
series_custom[['Minions (2015)', 'Leviathan (2014)']]
python数据分析处理库-Pandas的更多相关文章
- Python数据分析入门之pandas基础总结
Pandas--"大熊猫"基础 Series Series: pandas的长枪(数据表中的一列或一行,观测向量,一维数组...) Series1 = pd.Series(np.r ...
- Python数据分析工具:Pandas之Series
Python数据分析工具:Pandas之Series Pandas概述Pandas是Python的一个数据分析包,该工具为解决数据分析任务而创建.Pandas纳入大量库和标准数据模型,提供高效的操作数 ...
- python科学计算库-pandas
------------恢复内容开始------------ 1.基本概念 在数据分析工作中,Pandas 的使用频率是很高的, 一方面是因为 Pandas 提供的基础数据结构 DataFrame 与 ...
- 《Python 数据分析》笔记——pandas
Pandas pandas是一个流行的开源Python项目,其名称取panel data(面板数据)与Python data analysis(Python 数据分析)之意. pandas有两个重要的 ...
- 浅谈python的第三方库——pandas(一)
pandas作为python进行数据分析的常用第三方库,它是基于numpy创建的,使得运用numpy的程序也能更好地使用pandas. 1 pandas数据结构 1.1 Series 注:由于pand ...
- Python数据分析扩展库
Anaconda和Python(x,y)都自带了下面的这些库. 1. NumPy 强大的ndarray和ufunc函数. import numpy as np xArray = np.ones((3, ...
- Python 数据分析包:pandas 基础
pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包 类似于 Numpy 的核心是 ndarray,pandas 也是围绕着 Series 和 DataFrame 两个核心数据 ...
- Python数据分析numpy库
1.简介 Numpy库是进行数据分析的基础库,panda库就是基于Numpy库的,在计算多维数组与大型数组方面使用最广,还提供多个函数操作起来效率也高 2.Numpy库的安装 linux(Ubuntu ...
- 快速学习 Python 数据分析包 之 pandas
最近在看时间序列分析的一些东西,中间普遍用到一个叫pandas的包,因此单独拿出时间来进行学习. 参见 pandas 官方文档 http://pandas.pydata.org/pandas-docs ...
随机推荐
- Linux 下shell 编程学习脚手架
linux body { font-family: Helvetica, arial, sans-serif; font-size: 14px; line-height: 1.6; padding-t ...
- PFC电源设计与电感设计计算学习笔记
PFC电源设计与电感设计计算 更新于2018-11-30 课程概览 常见PFC电路和特点1 常见PFC电路和特点1 CRM PFC电路设计计算 CCM PFC电路设计计算 CCM Interleave ...
- September 10th 2017 Week 37th Sunday
Dream most deep place, only then the smile is not tired. 梦的最深处,只有微笑不累. Everyday I expect I can go to ...
- HBase学习之路 (七)HBase 原理
系统架构 错误图解 这张图是有一个错误点:应该是每一个 RegionServer 就只有一个 HLog,而不是一个 Region 有一个 HLog. 正确图解 从HBase的架构图上可以看出,HBas ...
- Day17 多线程编程
基本概念 进程:内存中正则运行的一个应用程序.一个进程包含多个线程. 线程:进程中的一个执行流程. 多线程:有两个或两个以上的并发执行流程. 线程的声明周期 说明: 1. 新建状态(New) ...
- tp5简要
1.实例化模型 namespace app\web\controller; use think\Controller; use app\web\model\Member; use think\Load ...
- 支持xhr浏览器:超时设定、加载事件、进度事件
各个浏览器虽然都支持xhr,但还是有些差异. 1.超时设定 IE8为xhr对象添加了一个timeout属性,表示请求在等待响应多少毫秒后就终止.再给timeout这只一个数值后,如果在规定的时间内浏览 ...
- JavaScript小例子
1. alert.html <html> <head> <title></title> <script type="text/javas ...
- jlink RTT 打印 BUG , FreeRTOS 在开启 tickless 模式下 无法使用的问题
一开始我以为是 jlink 的问题,后面发现是 tickless 模式搞鬼 tickless 模式下 ,内核 会 根据任务需求,会停止工作,这个时候 jlink rtt 打印就会失效!!! 不过 NR ...
- Hibernate第一天——入门和基本操作
第一个接触的框架就是这个Hibernate框架了,Hibernate本意是 冬眠 ,这里有必要引用CSDN上某位网友某个帖子的评论先引出框架的概念: 框架:一个软件半成品,帮你做了一些基础工作,你就可 ...