python数据分析处理库-Pandas
1、读取数据
import pandas
food_info = pandas.read_csv("food_info.csv")
print(type(food_info)) # <class 'pandas.core.frame.DataFrame'>
2、数据类型
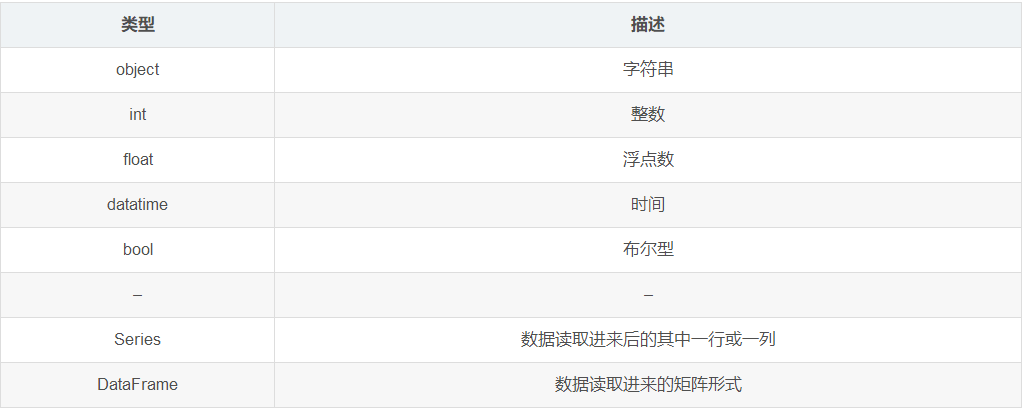
3、数据显示
food_info.head() # 显示读取数据的前5行
food_info.head(3) # 显示读取数据的前3行
food_info.tail(3) # 显示读取数据的后3行
food_info.columns # 列名
food_indo.shape # 数据规格
food_info.loc[0] # 第0行数据
food_info.loc[3:6] # 第3-6行数据
food_info.log[83,"NDB_No"] # 读取第83行的NDB_No数据
food_info["NDB_No"] # 通过列名读取列
columns = ["Zinc_(mg)", "Copper_(mg)"]
food_info[columns] # 读取多个列 # 读取单位为g的列
col_names = food_info.columns.tolist() # 列名
gram_columns = []
for c in col_names:
if c.endswith("(g)"):
gram_columns.append(c)
gram_df = food_info[gram_columns]
4、数据操作
# 对该列每一个值都除以1000,+-*同理
food_info["Iron_(mg)"] / 1000
# 维度相同的列对应元素相乘
water_energy = food_info["Water_(g)"] * food_info["Energ_Kcal"]
# 添加新的一列
iron_grams = food_info["Iron_(mg)"] / 1000
food_info["Iron_(g)"] = iron_grams
# 最大值
food_info["Energ_Kcal"].max()
# 排序 inplace-是否新生成一个DataFrame ascending-默认为True
food_info.sort_values("Sodium_(mg)", inplace=True, ascending=False)
# 将排序后的数据的索引值重置,生成新的索引
new_titanic_survival = titanic_survival.sort_values("Age",ascending=False)
new_titanic_survival.reset_index(drop=True)
5、缺失值处理
# 缺失值
pd.isnull(age)
titanic_survival["Age"].mean() # 去掉缺失值后的平均值 #去掉含有缺失值的数据
titanic_survival.dropna(axis=1) # 丢掉含有缺失值的列
titanic_survival.dropna(axis=0,subset=["Age", "Sex"]) # 丢掉"Age"与"Sex"中含有缺失值的行
6、简单的统计函数
# 统计在不同船舱中获救人数的平均值 aggfunc-默认为求均值
passenger_survival = titanic_survival.pivot_table(index="Pclass", values="Survived", aggfunc=np.mean)
7、自定义函数
# 返回行值
def hundredth_row(column):
# Extract the hundredth item
hundredth_item = column.loc[99]
return hundredth_item
hundredth_row = titanic_survival.apply(hundredth_row) # 置换列值
def which_class(row):
pclass = row['Pclass']
if pd.isnull(pclass):
return "Unknown"
elif pclass == 1:
return "First Class"
elif pclass == 2:
return "Second Class"
elif pclass == 3:
return "Third Class"
classes = titanic_survival.apply(which_class, axis=1)
8、Series结构
from pandas import Series
series_custom = Series(rt_scores , index=film_names)
series_custom[['Minions (2015)', 'Leviathan (2014)']]
python数据分析处理库-Pandas的更多相关文章
- Python数据分析入门之pandas基础总结
Pandas--"大熊猫"基础 Series Series: pandas的长枪(数据表中的一列或一行,观测向量,一维数组...) Series1 = pd.Series(np.r ...
- Python数据分析工具:Pandas之Series
Python数据分析工具:Pandas之Series Pandas概述Pandas是Python的一个数据分析包,该工具为解决数据分析任务而创建.Pandas纳入大量库和标准数据模型,提供高效的操作数 ...
- python科学计算库-pandas
------------恢复内容开始------------ 1.基本概念 在数据分析工作中,Pandas 的使用频率是很高的, 一方面是因为 Pandas 提供的基础数据结构 DataFrame 与 ...
- 《Python 数据分析》笔记——pandas
Pandas pandas是一个流行的开源Python项目,其名称取panel data(面板数据)与Python data analysis(Python 数据分析)之意. pandas有两个重要的 ...
- 浅谈python的第三方库——pandas(一)
pandas作为python进行数据分析的常用第三方库,它是基于numpy创建的,使得运用numpy的程序也能更好地使用pandas. 1 pandas数据结构 1.1 Series 注:由于pand ...
- Python数据分析扩展库
Anaconda和Python(x,y)都自带了下面的这些库. 1. NumPy 强大的ndarray和ufunc函数. import numpy as np xArray = np.ones((3, ...
- Python 数据分析包:pandas 基础
pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包 类似于 Numpy 的核心是 ndarray,pandas 也是围绕着 Series 和 DataFrame 两个核心数据 ...
- Python数据分析numpy库
1.简介 Numpy库是进行数据分析的基础库,panda库就是基于Numpy库的,在计算多维数组与大型数组方面使用最广,还提供多个函数操作起来效率也高 2.Numpy库的安装 linux(Ubuntu ...
- 快速学习 Python 数据分析包 之 pandas
最近在看时间序列分析的一些东西,中间普遍用到一个叫pandas的包,因此单独拿出时间来进行学习. 参见 pandas 官方文档 http://pandas.pydata.org/pandas-docs ...
随机推荐
- Centos下防止ssh暴力破解密码
参考文章地址:https://yq.aliyun.com/ziliao/48446 https://www.cnblogs.com/lsdb/p/7095288.html 1.收集 /var/log/ ...
- ES6中map和set用法
ES6中map和set用法 --转载自廖雪峰的官方网站 一.map Map是一组键值对的结构,具有极快的查找速度. 举个例子,假设要根据同学的名字查找对应的成绩,如果用Array实现,需要两个Arra ...
- php操作redis的两个个小脚本
redis这东西,查询起来没有mysql那么方便,只能自己写脚本了.下面是工作中写的两个小脚本 第一个脚本,查找有lottery|的键,将他们全部删除|打印出来 <?php $redis = n ...
- Git rebase日志
Git日志重写 为了方便管理,最近公司git接了jira,然后开发任务需要在jira上面先建立task,然后再task上面建立分支,后面该分支就和这个task进行了绑定. 因为之前一直使用传统的svn ...
- impala jdbc驱动执行impala sql的一个坑(不支持多行sql)
架构使用spark streaming 消费kafka的数据,并通过impala来插入到kudu中,但是通过对比发现落地到kudu表中的数据比kafka消息数要少,通过后台日志发现,偶发性的出现jav ...
- HDU5343:MZL's Circle Zhou(SAM,记忆化搜索DP)
Description Input Output Sample Input Sample Output Solution 题意:给你两个串,分别从两个里面各选出一个子串拼到一起,问能构成多少个本质不同 ...
- 【bzoj 4710】 [Jsoi2011]分特产
题目 容斥加组合计数 显然答案是 \[\sum_{i=0}^n(-1)^i\binom{n}{i}f_{n-i}\] \(f_i\)表示至多有\(i\)个人没有拿到特产 考虑求\(f\) 发现\(m\ ...
- [JSOI2008]Blue Mary的战役地图
嘟嘟嘟 当看到n <= 50 的时候就乐呵了,暴力就行了,不过最暴力的方法是O(n7)……然后加一个二分边长达到O(n6logn),然后我们接着优化,把暴力比对改成O(1)的比对hash值,能达 ...
- Day1 MySql安装和基本操作
数据和数据库 1.数据:客观事物的符号表示. 2.存储介质:纸,光盘,磁盘,u盘,云盘… 3.存储的目的:检索(查询) 存储数据量加大,导致检索的难度升高. 4.数据库(DB:database):按照 ...
- mybatis提取<where><if>共用代码
mybatis项目dao层中很多sql语句都会拥有某些相同的查询条件,以<where><if test=""></if></where&g ...