分布式缓存技术memcached学习系列(三)——memcached内存管理机制
几个重要概念
Slab
memcached通过slab机制进行内存的分配和回收,slab是一个内存块,它是memcached一次申请内存的最小单位,。在启动memcached的时候一般会使用参数-m指定其可用内存,但是并不是在启动的那一刻所有的内存就全部分配出去了,只有在需要的时候才会去申请,而且每次申请一定是一个slab。Slab的大小固定为1MB(1MB=1024KB=1024×1024B=1048576B,1048576字节),一个slab由若干个大小相等的chunk组成。
Slab的分类
根据chunk的大小而将Slab分为不同的类,chunk大小的增幅由增长因子factor决定。根据memcached版本的不同而分类也各有不同,-vv查询分类。
Chunk
chunk是Slab的组成单位,每个Slab都被分割成大小相等的chunk,分割Slab时,不够一个chunk大小的内存空间将被不可以避免的浪费(内存碎片化)。每个chunk中都保存了一个item结构体,item结构体由属性域和数据域组成,数据域中有一个变长数据data,是真正存储缓存记录key和value的地方。
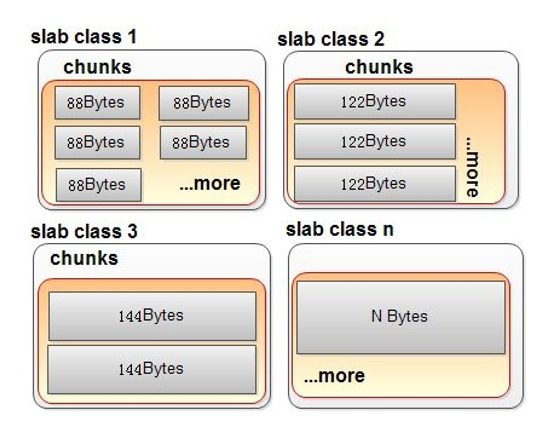
图memcached Slab 分类示意图
源码
typedef struct _stritem {
//属性域
struct _stritem *next;
struct _stritem *prev;
......
//数据域
union {
uint64_t cas;
char end;
} data[];
} item;
Chunk的计算
对于Slab 分类 i,求Slab 分类 i中的chunk的大小:
chunkSize = (default_size + item_size)*f^(i-1) + CHUNK_ALIGN_BYTES
各参数含义:
l i,分类
l default_size,默认大小为48字节,也就是item结构体中数据域的大小为48字节,可以通过-n参数来调节其大小
l item_size, item结构体的长度,固定为32字节
l f,factor,增长因子,是chunk变化大小的因素,默认值为1.25,调节f可以改变chunk的增幅,在启动时可以使用-f来指定
l CHUNK_ALIGH_BYTES 是一个长常量值,用来保证chunk的大小是这个常量值的整数倍,防止越界。CHUNK_ALIGH_BYTES 大小为sizeof(void *)
例如:void *的长度在不同系统上不一样,在32位机器上,sizeof(void *)值为4
所以,在32为的系统中,Slab 分类1中chunk的大小为:
chunkSize1 = (48 + 32)* 1.25^(1-1) + 4 = 84(有待验证)
从chunkSize的计算公式可以看出,可以通过调节-n,-f参数来调整chunk的大小,这也是实际中mecahced调优的关键,合理的调节-n,-f参数以充分利用内存资源,尽可能的减少内存碎片化。
内存分配
当我们通过add命令向memcached中添加一条记录的时候,memcached会根据数据的大小选择合适的slab,memcached维护着slab中空闲的chunk列表,并从中选择一块分配给要添加的记录。
如要存的item大小为100byte,chunk大小为80byte的slab将存不下,而chunk大小为120byte的slab又有剩余,此时memcached会将数据存到chunk大小为120byte的slab中。而剩余的20byte空间将不可避免的浪费。
需要注意的是,当chunk大小为120byte的slab已经满时,memcached并不会寻找更大chunk的slab,如chunk大小为140byte的slab来存储,而是把chunk大小为120byte的slab中的旧数据踢掉。
增长因子调优
memcached 在启动时可以通过f 选项指定增长因子,默认为1.25。增长因子的不同,chunk大小也不同,应根据实际情况,指定合理的增长因子避免过多的内存空间浪费。
过期数据惰性删除
Memcached中,当某个chunk 中的数据过期后,并不会马上从内存中删除,因此,使用stats 统计时,curr_item中仍然有其信息,直到新的数据占用该chunk ;当试图去get改数据时,先判断是否过期,如果过期则返回空并清空chunk,curr_item减1。过期数据不会马上删除,这种机制称为lazy expiration,即惰性失效,好处是不需要另外去检查数据是否失效,节省了CUP的检测成本。
LRU删除机制
和操作系统内存管理类似,memcached数据删除机制使用的是“最近最少使用”机制(Least Recently Used)进行数据剔除,memcached通过维护一个计数器,来判断最近谁最少被使用,当有新的数据进来时,最近最少用的数据将被剔除。
memcached使用三十二位元的循环冗余校验(CRC-32)计算键值后,将数据分散在不同的机器上。当chunk满了以后,接下来新增的数据会以LRU机制替换掉。
即使某个key被设置永久有效期,也一样会被踢出来,即永久数据被踢现象。
参考文档:
http://kenby.iteye.com/blog/1423989
http://www.dexcoder.com/selfly/article/2248
http://www.dexcoder.com/selfly/series/63
http://www.cnblogs.com/luluping/archive/2009/01/14/1375456.html
分布式缓存技术memcached学习系列(三)——memcached内存管理机制的更多相关文章
- 分布式缓存技术redis学习系列
分布式缓存技术redis学习系列(一)--redis简介以及linux上的安装以及操作redis问题整理 分布式缓存技术redis学习系列(二)--详细讲解redis数据结构(内存模型)以及常用命令 ...
- 分布式缓存技术redis学习系列(一)——redis简介以及linux上的安装
redis简介 redis是NoSQL(No Only SQL,非关系型数据库)的一种,NoSQL是以Key-Value的形式存储数据.当前主流的分布式缓存技术有redis,memcached,ssd ...
- 分布式缓存技术redis学习系列(三)——redis高级应用(主从、事务与锁、持久化)
上文<详细讲解redis数据结构(内存模型)以及常用命令>介绍了redis的数据类型以及常用命令,本文我们来学习下redis的一些高级特性. 安全性设置 设置客户端操作秘密 redis安装 ...
- 分布式缓存技术redis学习系列(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
本文是redis学习系列的第四篇,前面我们学习了redis的数据结构和一些高级特性,点击下面链接可回看 <详细讲解redis数据结构(内存模型)以及常用命令> <redis高级应用( ...
- 分布式缓存技术redis学习系列(五)——redis实战(redis与spring整合,分布式锁实现)
本文是redis学习系列的第五篇,点击下面链接可回看系列文章 <redis简介以及linux上的安装> <详细讲解redis数据结构(内存模型)以及常用命令> <redi ...
- 分布式缓存技术redis学习(三)——redis高级应用(主从、事务与锁、持久化)
上文<详细讲解redis数据结构(内存模型)以及常用命令>介绍了redis的数据类型以及常用命令,本文我们来学习下redis的一些高级特性.目录如下: 安全性设置 设置客户端操作秘密 客户 ...
- 分布式缓存技术redis学习系列(二)——详细讲解redis数据结构(内存模型)以及常用命令
Redis数据类型 与Memcached仅支持简单的key-value结构的数据记录不同,Redis支持的数据类型要丰富得多,常用的数据类型主要有五种:String.List.Hash.Set和Sor ...
- 分布式缓存技术redis学习(一)——redis简介以及linux上的安装
redis简介 redis是NoSQL(No Only SQL,非关系型数据库)的一种,NoSQL是以Key-Value的形式存储数据.当前主流的分布式缓存技术有redis,memcached,ssd ...
- 分布式缓存技术redis学习(四)——redis高级应用(集群搭建、集群分区原理、集群操作)
本文是redis学习系列的第四篇,前面我们学习了redis的数据结构和一些高级特性,点击下面链接可回看 <详细讲解redis数据结构(内存模型)以及常用命令> <redis高级应用( ...
- C语言深入学习系列 - 字节对齐&内存管理
用C语言写程序时需要知道是大端模式还是小端模式. 所谓的大端模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中:所谓的小端模式,是指数据的低位保存在内存的低地址中,而数据的高 ...
随机推荐
- IOS之Block讲解
Block,称为代码块,它是一个C级别的语法以及运行时的一个特性,和标准C中的函数(函数指针)类似,但是其运行需要编译器和运行时支持,从ios4.0开始就很好的支持Block. Block很像匿名方法 ...
- 升级mojave后的小问题解决
首先是xcode没了,我到苹果软件市场上重新下载了一个,可以了. 然后是virtualbox无法打开了,现实版本不兼容,我到官网重新下载了一个最新的6.0.然后就可以正常打开了,并且是无感升级,原来的 ...
- Delegate模式
转载:http://www.cnblogs.com/limlee/archive/2012/06/13/2547367.html 代理模式 顾名思义就是委托别人去做事情. IOS中经常会遇到的两种情况 ...
- Ajax中文传参出现乱码
Ajax技术的核心为Javascript,而javascript使用的是UTF-8编码,因此在页面采用GBK或者其他编码,同时没有进行编码转换时,就会出现中文乱码的问题. 以下是分别使用GET和POS ...
- Android IO存储总结
1 前言 android设备的存储特点: 分内存和SD卡两种存储设备,且android设备存储空间小,且系统碎片化等情况. SD卡:老版本的android设备 不存在内置SD ...
- Java从零开始学二十九(大数操作(BigIntger、BigDecimal)
一.BigInteger 如果在操作的时候一个整型数据已经超过了整数的最大类型长度long的话,则此数据就无法装入,所以,此时要使用BigInteger类进行操作. 不可变的任意精度的整数.所有操作中 ...
- cat 命令(转)
原文:http://www.cnblogs.com/peida/archive/2012/10/30/2746968.html cat命令的用途是连接文件或标准输入并打印.这个命令常用来显示文件内容, ...
- 子查询一(WHERE中的子查询)
子查询 子查询就是指的在一个完整的查询语句之中,嵌套若干个不同功能的小查询,从而一起完成复杂查询的一种编写形式,为了让读者更加清楚子查询的概念. 子查询返回结果子查询可以返回的数据类型一共分为四种: ...
- Loadrunner错误-26601、-27492、-27727处理方法
1.错误 -26601: 解压缩函数(wgzMemDecompressBuffer)失败,返回代码=-5 (Z_BUF_ERROR).inSize=0.inUse=0.outUse=0 用LR做压力测 ...
- JavaWeb 路径问题
路径问题 CreateTime--2016年9月22日15:19:56 Author:Marydon 一.jsp页面 src="../demo/clazz/clazz_add.js&qu ...