Java之IO(二)BufferedInputStream和BufferedOutputStream
转载请注明源出处:http://www.cnblogs.com/lighten/p/6971234.html
1.前言
本文主要介绍输入输出流中的BufferedInputStream和BufferedOutStream的实现,其虽是InputStream和OutputStream的子类,但中间还隔了一个FilterInputStream和FilterOutputStream。前言中先介绍一下这两个类。这两个类都是简单的包装类。
1.1 FilterInputStream
FilterInputStream继承了父类InputStream,其没有进行什么特殊的处理,做法很简单。持有一个输入流,然后每个方法都是调用这个输入流的方法。如下图所示:


如上图所示,其覆写了InputStream的所有方法,实现过程都是直接调用持有的输入流的相应方法。这个类就是对一个输入流的简单封装罢了,但是其子类可能有其它的方法。
1.2 FilterOutputStream
FilterOutputStream和上述实现原理基本一致,也是继承自OutputStream,但是不同之处在于其中有些方法并不是直接调用持有的输出流的相应方法。


write(byte, int, int)方法比较父类,没有对输入的byte[]数组进行非空校验,其它的操作基本相同。不过不写实际上也是抛出了空指针异常。所以也没什么问题。
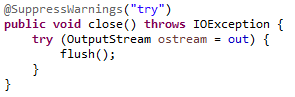
close()方法,先调用了flush()方法,然后关闭了这个流。这个写法有些奇怪,实际上使用的是JDK1.7 build 105之后的一个特性:try-with-resources。自动资源管理。新的语句支持包括流以及任何可关闭的资源,前提是可关闭的资源必须实现 java.lang.AutoCloseable 接口。
2.BufferedInputStream
bufferedInputStream类继承自刚刚所说的FilterInputStream类。其默认缓存大小为8192个字节,最大的缓存大小是整数类型最大值-8,即2^31-1-8。具体实现是内部有一个byte[]缓存数组。这个类比较重要的成员变量如下:
protected volatile byte buf[]; // 缓存的字节数组 private static final
AtomicReferenceFieldUpdater<BufferedInputStream, byte[]> bufUpdater =
AtomicReferenceFieldUpdater.newUpdater
(BufferedInputStream.class, byte[].class, "buf"); // 原子引用字段,关闭流的时候可能是异步的,使用这个的CAS机制来根据buf是否为null判断流是否关闭 protected int count; // 当前读取完的流的长度
protected int pos; // 当前已使用缓存数组中的长度,也就是下一个从缓存中读取的数组下标
protected int markpos = -1; // 调用mark方法时pos的位置
protected int marklimit; // 最大允许读取的标记长度,mark之后reset后能重复读取的最大长度
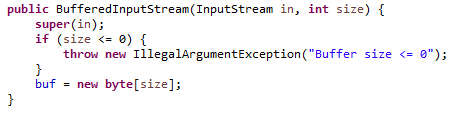
BufferedInputStream也需要一个可读的输入流,其初始化没指定缓存大小就使用默认缓存大写8192。值得一提的是其判断是否关闭都是通过是否为null来判断,即将流和缓存在关闭时设置成null。使用时判断为null就抛出流关闭IO异常。


上面是BufferedInputStream重写的read()方法。可以看出使用了锁,因此这个类是线程安全的。整个过程如下:
1.先判断读取的字节其位置pos是否超过了字节数组已缓存的大小count,如果超过了,就调用fill的方法,从流中继续读取,之后再比较一次,如果还是比当前数组记录数要大,就表示流已经读取完了,返回-1。否则返回我当前要读取的位置的值。pos移动一位。
2.fill方法如果标记位置小于0就重置pos,再将pos赋给count,调用被包装流的read(byte, int, int)方法,读取到pos位置开始,读满缓存数组。
整个调用read()方法,就是返回当前要读取的数组的那个位置,如果位置大于等于缓存内容的长度(也就是缓存内容读完了),就去重新填满缓存,pos和count重新计算。否则就没读完缓存内容,就返回缓存中这个位置的值。这个过程又涉及到标记位置,所以如果有标记位的话,就不能简单的重置缓存和计数了。这也就是中间那大段的逻辑了。

close()方法也就是前面提到的,将bufUpdater中的buffer置为null,然后关闭流。
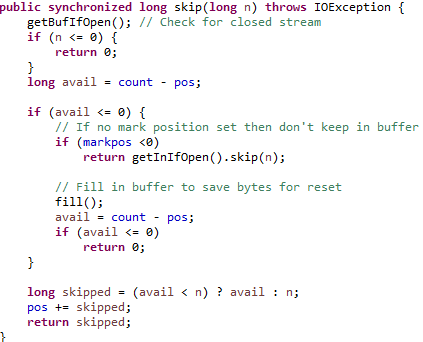
skip方法过程就是:1.判读流是否还开启;2.计算当前未读取的缓存;3.如果当前没有可读缓存,且没有标记,就调用流的skip跳过流中的字节,返回跳过数;4.如果有标记,就通过fill()方法,将标记的那段重置一下,再计算一次可用缓存,如果还是没有就返回跳过0。5.如果缓存中有可用,就正常跳过,pos位置加上跳过的值。
也就是说skip方法在缓存有未读取的时候,最多只会跳过目前缓存中的值,没有缓存的时候,也没标记则会跳过流中的个数。若没缓冲有标记的时候,就会重置缓存,读取流,如果此时可用的长度还为0则没有跳过项,否则就最多跳过目前缓存中的值。
还有一个read(byte[], int, int)方法就不介绍了,过程也比较好懂。
小结一下,BufferInputStream最重要的字段就是pos,count。负责调控整个调用过程。pos是当前将要读取位置,count是已缓存的流的长度。读取和跳过都是优先缓存的,缓存中没有,才会到流中去操作。fill()方法就是用来将流中的数据填充到缓存中,但这个方法有一个前提,那就是必须是被同步方法块调用,并且缓存必须是被读完了,即之后就会pos > count。如果不满足,则不能调用这个方法。理解这一点就比较好理解这个运算过程了,不然看别人代码就比较困难,这个就是此类的设计思路了。
3.BufferedOutputStream
BufferedOutputStream比较简单,里面就两个成员变量。这个类的主要作用就是避免了反复一个个write(byte)。
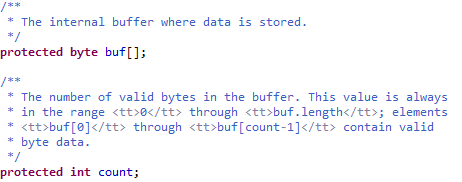
buf[]就是缓存的数据字节数组,count就是缓存中内容长度了。默认缓冲大小也是8192。

实现也很简单,如果缓存的长度操作数组长度,就整个缓存输入包装的输出流。否者就放入缓存数据中,count位置+1。
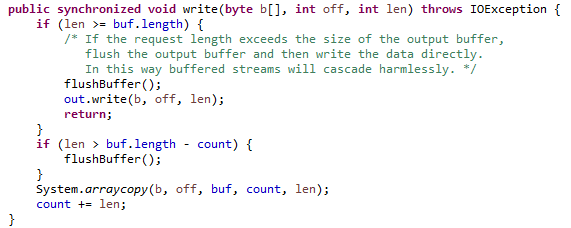
输入一个数组,会先判断是否超过缓存长度,超过了,就先刷目前的缓存,再直接调用包装输出流的write(byte[], int, int)方法,不走缓存。如果比缓存大小小,但大于可用长度,还是先刷入目前的缓存。之后就是将数组拷贝到缓存可用的后面。

flush()方法就是先刷新缓存,在调用包装的输出流的flush()方法。
4.后记
缓存输入输出流都是对一个已有的流进行包装,最终都是调用已有的流相关方法。这两者都是缓存优先的,所以使用的时候要注意,比如输入流的skip方法使用就要注意了。输入流缓存,避免了使用in.read()一个个读取,关键是使得mark()方法可用(流一般都是读取完了就没了,缓存就意味着可以重置),输出流也是避免了一个个byte输出。最后两者都是线程安全的。
Java之IO(二)BufferedInputStream和BufferedOutputStream的更多相关文章
- Java IO流 BufferedInputStream、BufferedOutputStream的基本使用
BufferedInputStream.BufferedOutputStream的基本使用 BufferedInputStream是FilterInputStream流的子类,FilterInputS ...
- Java基础---IO(二)--File类、Properties类、打印流、序列流(合并流)
第一讲 File类 一.概述 1.File类:文件和目录路径名的抽象表现形式 2.特点: 1)用来将文件或文件夹封装成对象 2)方便于对文件与文件夹的属性信息进行操作 3)File类的实例是不 ...
- Java之IO(零)总结
转载请注明原出处:http://www.cnblogs.com/lighten/p/7274378.html 1.前言 本章是对之前所讲述的整个Java的IO包的一个总结,抽出个人认为比较重要的知识点 ...
- Java基础-IO流对象之字节缓冲流(BufferedOutputStream与BufferedInputStream)
Java基础-IO流对象之字节缓冲流(BufferedOutputStream与BufferedInputStream) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在我们学习字 ...
- Java IO(十) BufferedInputStream 和 BufferedOutputStream
Java IO(十)BufferedInputStream 和 BufferedOutputStream 一.BufferedInputStream 和 BufferedOutputStream (一 ...
- Java IO流学习总结三:缓冲流-BufferedInputStream、BufferedOutputStream
Java IO流学习总结三:缓冲流-BufferedInputStream.BufferedOutputStream 转载请标明出处:http://blog.csdn.net/zhaoyanjun6/ ...
- java 输入输出IO流 字节流| 字符流 的缓冲流:BufferedInputStream;BufferedOutputStream;BufferedReader(Reader in);BufferedWriter(Writer out)
什么是缓冲流: 缓冲流的基本原理,是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率. 图解: 1.字节缓冲流BufferedInputStr ...
- Java IO(二)
字节流 字符流: FileReader FileWriter BufferedReader BufferedWriter 字节流: FileInputStream FileOutputStream B ...
- java io系列13之 BufferedOutputStream(缓冲输出流)的认知、源码和示例
本章内容包括3个部分:BufferedOutputStream介绍,BufferedOutputStream源码,以及BufferedOutputStream使用示例. 转载请注明出处:http:// ...
随机推荐
- win10 新增删除文件不刷新
实际上是桌面图标缓存出问题,以下是一个简单动作即可解决问题. 按Win+R键打开“运行”窗口,输入如下命令后按回车键执行: ie4uinit -show 立竿见影,效果同360,魔方等工具软件,可参考 ...
- HDU 1718 Rank (排序)
题意:给你n个学号和成绩,并且给定一个学号,让找这个学号是多少名. 析:用个结构体,按成绩排序,然后找那个学号,这个题有一个小坑,那就是并列的情况, 可能并列多少名,这个要考虑一下,其他的easy! ...
- LA 3942 && UVa 1401 Remember the Word (Trie + DP)
题意:给你一个由s个不同单词组成的字典和一个长字符串L,让你把这个长字符串分解成若干个单词连接(单词是可以重复使用的),求有多少种.(算法入门训练指南-P209) 析:我个去,一看这不是一个DP吗?刚 ...
- ORBSlam with ROS
...相机标定 calibration 基本就是做CV 的常识 ORBSlam源码:
- TurtleBot教程
TurtleBot TurtleBot combines popular off-the-shelf robot components like the iRobot Create, Yujin Ro ...
- 被“1”和“l”给坑了
由于输入法的原因,导致小写的英文字母“L”和阿拉伯数字“1”长得非常像,在写秘钥的时候很容易把看错.由于对方发秘钥的时候给的是图片,而且不太清晰,手动输入的时候把“1”写成“l”了,对了好几遍秘钥也没 ...
- 股票——成交量加权平均价VWAP
成交量加权平均价是将多笔交易的价格按各自的成交量加权而算出的平均价,若是计算某一证券在某交易日的VWAP,将当日成交总值除以总成交量即可.VWAP可作为交易定价的一种方法,亦可作为衡量机构投资者或交易 ...
- ORACLE 管道技术应用
但是使用管道函数的时候是可以返回一个package里面定义的type的. create or replace package test_typeis type test_type_record ...
- Android-Java-了解编译
在多年以前,计算机早期的运行方式是 01010100 ....., 这种方式的时候,开发人员编写代码是把01010101/01100101/01010111 ..... /来汇编写代码,这种方式特别痛 ...
- CSharp如何自定义鼠标样式
一.如何设置鼠标样式? 在CSharp的WinForm开发中,可以通过下面的API设置鼠标样式: //把鼠标样式设置为十字(系统自带的一种鼠标样式) this.Cursor = Cursors.Cro ...