Hadoop学习之路(七)Hadoop集群shell常用命令
Hadoop常用命令
启动HDFS集群
[hadoop@hadoop1 ~]$ start-dfs.sh
Starting namenodes on [hadoop1]
hadoop1: starting namenode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-namenode-hadoop1.out
hadoop2: starting datanode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-datanode-hadoop2.out
hadoop3: starting datanode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-datanode-hadoop3.out
hadoop4: starting datanode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-datanode-hadoop4.out
hadoop1: starting datanode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-datanode-hadoop1.out
Starting secondary namenodes [hadoop3]
hadoop3: starting secondarynamenode, logging to /home/hadoop/apps/hadoop-2.7./logs/hadoop-hadoop-secondarynamenode-hadoop3.out
[hadoop@hadoop1 ~]$
启动YARN集群
[hadoop@hadoop4 ~]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-resourcemanager-hadoop4.out
hadoop2: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-nodemanager-hadoop2.out
hadoop3: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-nodemanager-hadoop3.out
hadoop4: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-nodemanager-hadoop4.out
hadoop1: starting nodemanager, logging to /home/hadoop/apps/hadoop-2.7./logs/yarn-hadoop-nodemanager-hadoop1.out
[hadoop@hadoop4 ~]$
查看HDFS系统根目录
[hadoop@hadoop1 ~]$ hadoop fs -ls /
Found items
drwxr-xr-x - hadoop supergroup -- : /test
drwx------ - hadoop supergroup -- : /tmp
[hadoop@hadoop1 ~]$
创建文件夹
[hadoop@hadoop1 ~]$ hadoop fs -mkdir /a
[hadoop@hadoop1 ~]$ hadoop fs -ls /
Found items
drwxr-xr-x - hadoop supergroup -- : /a
drwxr-xr-x - hadoop supergroup -- : /test
drwx------ - hadoop supergroup -- : /tmp
[hadoop@hadoop1 ~]$
级联创建文件夹
[hadoop@hadoop1 ~]$ hadoop fs -mkdir -p /aa/bb/cc
[hadoop@hadoop1 ~]$
查看hsdf系统根目录下的所有文件包括子文件夹里面的文件
[hadoop@hadoop1 ~]$ hadoop fs -ls -R /aa
drwxr-xr-x - hadoop supergroup 0 2018-03-08 11:12 /aa/bb
drwxr-xr-x - hadoop supergroup 0 2018-03-08 11:12 /aa/bb/cc
[hadoop@hadoop1 ~]$
上传文件
[hadoop@hadoop1 ~]$ ls
apps data words.txt
[hadoop@hadoop1 ~]$ hadoop fs -put words.txt /aa
[hadoop@hadoop1 ~]$ hadoop fs -copyFromLocal words.txt /aa/bb
[hadoop@hadoop1 ~]$
下载文件
[hadoop@hadoop1 ~]$ hadoop fs -get /aa/words.txt ~/newwords.txt
[hadoop@hadoop1 ~]$ ls
apps data newwords.txt words.txt
[hadoop@hadoop1 ~]$ hadoop fs -copyToLocal /aa/words.txt ~/newwords1.txt
[hadoop@hadoop1 ~]$ ls
apps data newwords1.txt newwords.txt words.txt
[hadoop@hadoop1 ~]$
合并下载
[hadoop@hadoop1 ~]$ hadoop fs -getmerge /aa/words.txt /aa/bb/words.txt ~/2words.txt
[hadoop@hadoop1 ~]$ ll
总用量
-rw-r--r--. hadoop hadoop 3月 : 2words.txt
drwxrwxr-x. hadoop hadoop 3月 : apps
drwxrwxr-x. hadoop hadoop 3月 : data
-rw-r--r--. hadoop hadoop 3月 : newwords1.txt
-rw-r--r--. hadoop hadoop 3月 : newwords.txt
-rw-rw-r--. hadoop hadoop 3月 : words.txt
[hadoop@hadoop1 ~]$
复制
从HDFS一个路径拷贝到HDFS另一个路径
[hadoop@hadoop1 ~]$ hadoop fs -ls /a
[hadoop@hadoop1 ~]$ hadoop fs -cp /aa/words.txt /a
[hadoop@hadoop1 ~]$ hadoop fs -ls /a
Found items
-rw-r--r-- hadoop supergroup -- : /a/words.txt
[hadoop@hadoop1 ~]$
移动
在HDFS目录中移动文件
[hadoop@hadoop1 ~]$ hadoop fs -ls /aa/bb/cc
[hadoop@hadoop1 ~]$ hadoop fs -mv /a/words.txt /aa/bb/cc
[hadoop@hadoop1 ~]$ hadoop fs -ls /aa/bb/cc
Found items
-rw-r--r-- hadoop supergroup -- : /aa/bb/cc/words.txt
[hadoop@hadoop1 ~]$
删除
删除文件或文件夹
[hadoop@hadoop1 ~]$ hadoop fs -rm /aa/bb/cc/words.txt
// :: INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = minutes, Emptier interval = minutes.
Deleted /aa/bb/cc/words.txt
[hadoop@hadoop1 ~]$ hadoop fs -ls /aa/bb/cc
[hadoop@hadoop1 ~]$
删除空目录
[hadoop@hadoop1 ~]$ hadoop fs -rmdir /aa/bb/cc/
[hadoop@hadoop1 ~]$ hadoop fs -ls /aa/bb/
Found items
-rw-r--r-- hadoop supergroup -- : /aa/bb/words.txt
[hadoop@hadoop1 ~]$
强制删除
[hadoop@hadoop1 ~]$ hadoop fs -rm /aa/bb/
rm: `/aa/bb': Is a directory
[hadoop@hadoop1 ~]$ hadoop fs -rm -r /aa/bb/
// :: INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = minutes, Emptier interval = minutes.
Deleted /aa/bb
[hadoop@hadoop1 ~]$ hadoop fs -ls /aa
Found items
-rw-r--r-- hadoop supergroup -- : /aa/words.txt
[hadoop@hadoop1 ~]$
从本地剪切文件到HDFS上
[hadoop@hadoop1 ~]$ ls
apps data hello.txt
[hadoop@hadoop1 ~]$ hadoop fs -moveFromLocal ~/hello.txt /aa
[hadoop@hadoop1 ~]$ ls
apps data
[hadoop@hadoop1 ~]$
追加文件
追加之前hello.txt到words.txt之前
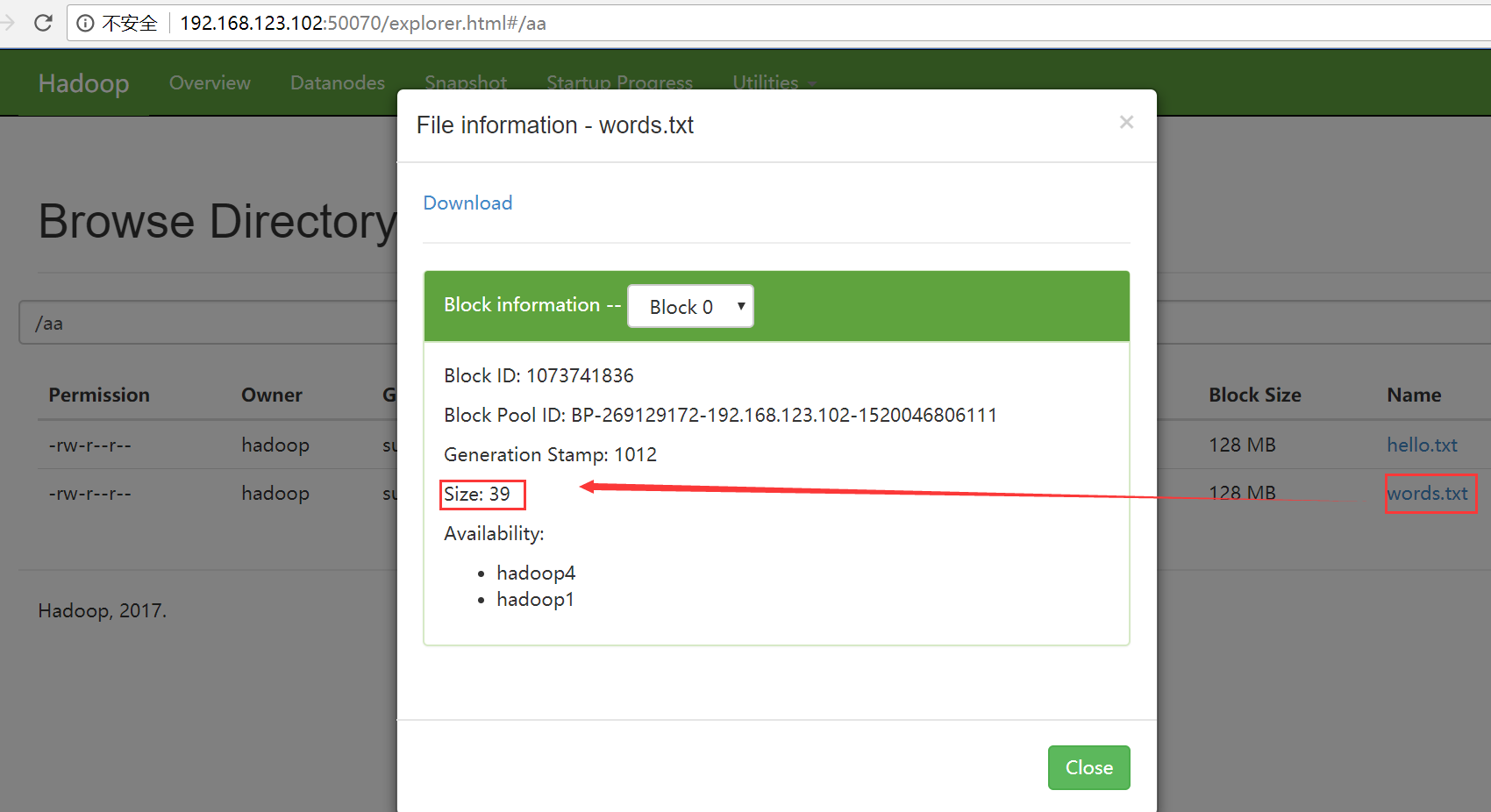
[hadoop@hadoop1 ~]$ hadoop fs -appendToFile ~/hello.txt /aa/words.txt
[hadoop@hadoop1 ~]$
追加之前hello.txt到words.txt之后
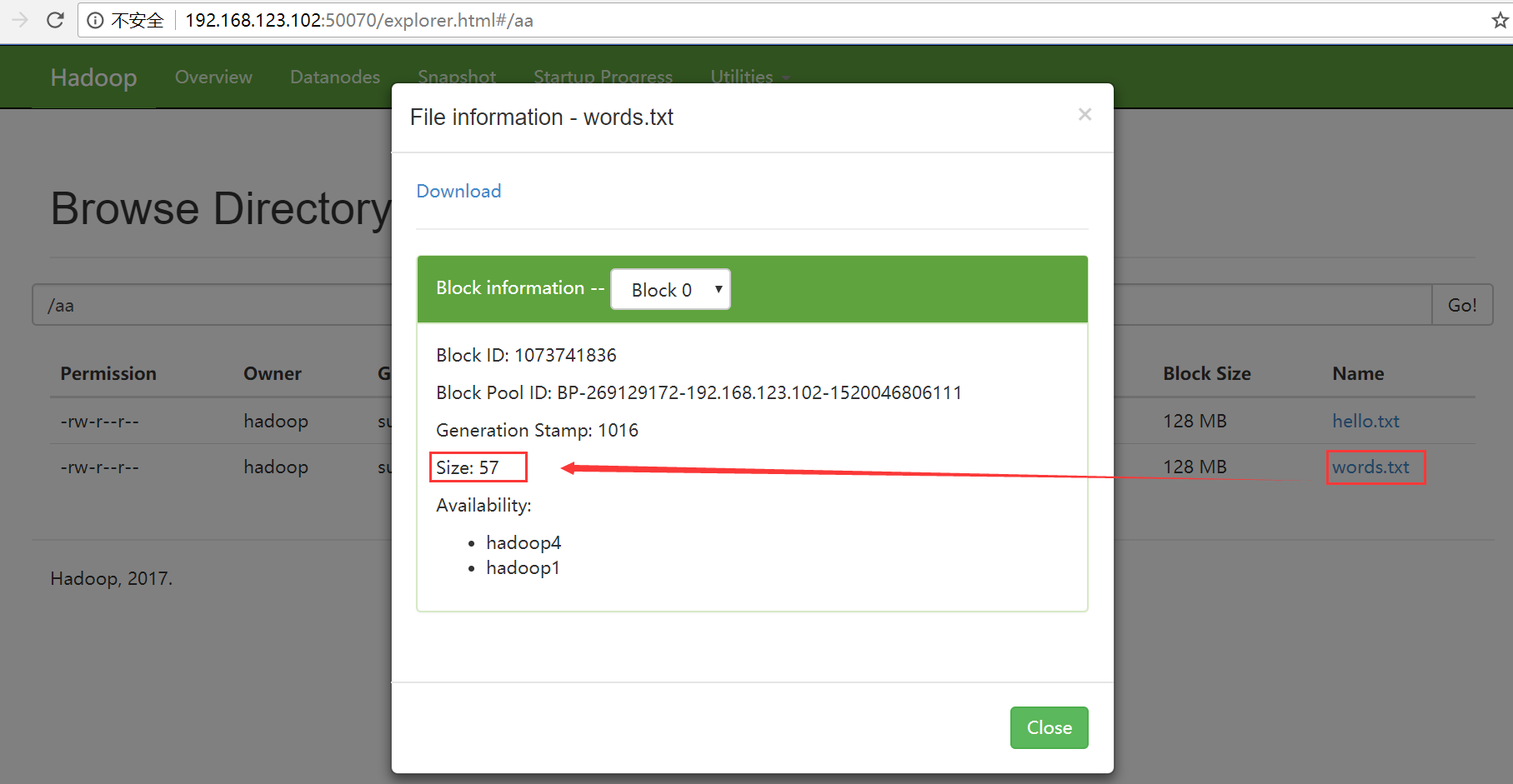
查看文件内容
[hadoop@hadoop1 ~]$ hadoop fs -cat /aa/hello.txt
hello
hello
hello
[hadoop@hadoop1 ~]$
chgrp
使用方法:hadoop fs -chgrp [-R] GROUP URI [URI …] Change group association of files. With -R, make the change recursively through the directory structure. The user must be the owner of files, or else a super-user. Additional information is in the Permissions User Guide. -->
改变文件所属的组。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。更多的信息请参见HDFS权限用户指南。
chmod
使用方法:hadoop fs -chmod [-R] <MODE[,MODE]... | OCTALMODE> URI [URI …]
改变文件的权限。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。更多的信息请参见HDFS权限用户指南。
chown
使用方法:hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
改变文件的拥有者。使用-R将使改变在目录结构下递归进行。命令的使用者必须是超级用户。更多的信息请参见HDFS权限用户指南。
du
使用方法:hadoop fs -du URI [URI …]
显示目录中所有文件的大小,或者当只指定一个文件时,显示此文件的大小。
示例:
hadoop fs -du /user/hadoop/dir1 /user/hadoop/file1 hdfs://host:port/user/hadoop/dir1
返回值:
成功返回0,失败返回-1。
dus
使用方法:hadoop fs -dus <args>
显示文件的大小。
expunge
使用方法:hadoop fs -expunge
清空回收站。请参考HDFS设计文档以获取更多关于回收站特性的信息。
setrep
使用方法:hadoop fs -setrep [-R] <path>
改变一个文件的副本系数。-R选项用于递归改变目录下所有文件的副本系数。
示例:
- hadoop fs -setrep -w 3 -R /user/hadoop/dir1
返回值:
成功返回0,失败返回-1。
tail
使用方法:hadoop fs -tail [-f] URI
将文件尾部1K字节的内容输出到stdout。支持-f选项,行为和Unix中一致。
示例:
- hadoop fs -tail pathname
返回值:
成功返回0,失败返回-1。
test
使用方法:hadoop fs -test -[ezd] URI
选项:
-e 检查文件是否存在。如果存在则返回0。
-z 检查文件是否是0字节。如果是则返回0。
-d 如果路径是个目录,则返回1,否则返回0。
示例:
- hadoop fs -test -e filename
查看集群的工作状态
[hadoop@hadoop1 ~]$ hdfs dfsadmin -report
Configured Capacity: (68.68 GB)
Present Capacity: (49.16 GB)
DFS Remaining: (49.16 GB)
DFS Used: ( KB)
DFS Used%: 0.00%
Under replicated blocks:
Blocks with corrupt replicas:
Missing blocks:
Missing blocks (with replication factor ): -------------------------------------------------
Live datanodes (): Name: 192.168.123.102: (hadoop1)
Hostname: hadoop1
Decommission Status : Normal
Configured Capacity: (17.17 GB)
DFS Used: ( KB)
Non DFS Used: (4.00 GB)
DFS Remaining: (12.29 GB)
DFS Used%: 0.00%
DFS Remaining%: 71.57%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Thu Mar :: CST Name: 192.168.123.105: (hadoop4)
Hostname: hadoop4
Decommission Status : Normal
Configured Capacity: (17.17 GB)
DFS Used: ( KB)
Non DFS Used: (4.00 GB)
DFS Remaining: (12.29 GB)
DFS Used%: 0.00%
DFS Remaining%: 71.58%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Thu Mar :: CST Name: 192.168.123.103: (hadoop2)
Hostname: hadoop2
Decommission Status : Normal
Configured Capacity: (17.17 GB)
DFS Used: ( KB)
Non DFS Used: (4.00 GB)
DFS Remaining: (12.29 GB)
DFS Used%: 0.00%
DFS Remaining%: 71.58%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Thu Mar :: CST Name: 192.168.123.104: (hadoop3)
Hostname: hadoop3
Decommission Status : Normal
Configured Capacity: (17.17 GB)
DFS Used: ( KB)
Non DFS Used: (4.00 GB)
DFS Remaining: (12.29 GB)
DFS Used%: 0.00%
DFS Remaining%: 71.57%
Configured Cache Capacity: ( B)
Cache Used: ( B)
Cache Remaining: ( B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers:
Last contact: Thu Mar :: CST [hadoop@hadoop1 ~]$
Hadoop学习之路(七)Hadoop集群shell常用命令的更多相关文章
- ES集群检查常用命令
一.集群检查常用命令 查询集群状态命令: curl -XGET "http://ip:port/_cluster/health?pretty" 查询Es全局状态: curl -XG ...
- Hadoop学习记录(5)|集群搭建|节点动态添加删除
集群概念 计算机集群是一种计算机系统,通过一组松散继承的计算机软件或硬件连接连接起来高度紧密地协作完成计算工作. 集群系统中的单个计算机通常称为节点,通过局域网连接. 集群特点: 1.效率高,通过多态 ...
- 【整理学习Hadoop】Hadoop学习基础之一:服务器集群技术
服务器集群就是指将很多服务器集中起来一起进行同一种服务,在客户端看来就像是只有一个服务器.集群可以利用多个计算机进行并行计算从而获得很高的计算速度,也可以用多个计算机做备份,从而使得任 ...
- hadoop集群操作常用命令
一.HDFS相关 1.启动NameNode sbin/hadoop-daemon.sh start namenode 2.启动DataNode sbin/hadoop-<span style=& ...
- kubernetes集群管理常用命令一
系列目录 我们把集群管理命令分为两个部分,第一部分介绍一些简单的,但是可能是非常常用的命令以及一些平时可能没有碰到的技巧.第二部分将综合前面介绍的工具通过示例来讲解一些更为复杂的命令. 列出集群中所有 ...
- 【Kubernetes】容器集群管理常用命令笔记
一.集群部署-查询集群状态 ①查询k8s master各组件健康状态: kubectl get componentstatus ②查询k8s node健康状态: kubectl get node 二. ...
- 使用kubectl管理Kubernetes(k8s)集群:常用命令,查看负载,命名空间namespace管理
目录 一.系统环境 二.前言 三.kubectl 3.1 kubectl语法 3.2 kubectl格式化输出 四.kubectl常用命令 五.查看kubernetes集群node节点和pod负载 5 ...
- MongoDB集群管理常用命令
1.以admin身份登录yqtrack_gather01库: mongo 127.0.0.1:27017/yqtrack_gather01 -u username -p password --auth ...
- 测开之路七十五:linux常用命令
常用命令: ls:列出文件或目录 pwd:展示当前所在的目录 mkdir:创建目录 mkdir -p :创建连续的目录 cd:切换目录 vi:编辑内容,点i开始编辑,输入::wq保存 cat 显示文件 ...
随机推荐
- Linux下的mysql默认大小写敏感
在Linux下: 1.数据库名与表名是严格区分大小写的: 2.表的别名是严格区分大小写的: 3.列名与列的别名在所有的情况下均是忽略大小写的: 4.变量名也是严格区分大小写的: 在Windows下: ...
- 深入理解java虚拟机---java内存区域与内存溢出异常---1内存结构
本文来源于翁舒航的博客,点击即可跳转原文观看!!!(被转载或者拷贝走的内容可能缺失图片.视频等原文的内容) 若网站将链接屏蔽,可直接拷贝原文链接到地址栏跳转观看,原文链接:https://www.cn ...
- js遇到的问题
一些开发前台时遇到的小问题: ----------------------------------------- 一眼看出页面使用html还是html5: html有三种声明方式:<!DOCTY ...
- Review——JS的异步与同步
一.概念 同步(synchronous):指在js的主线程上,所有任务被依次执行: 异步(asynchronous):指任务不进入主线程,进入任务队列(task):当“任务队列”通知主线程,异步任务才 ...
- css-图文案例
效果如下: 附上代码: <html> <head> <title>World</title> <style type="text/css ...
- PHPCMS v9上传图片提示"undefined"的解决办法
把phpcms\modules\attachment\attachments.php中将 if(empty($this->userid)){改成 if(empty($_POST['userid' ...
- 新浪微博开放平台账号申请(基于dcloud开发)
注意事项: 1.新浪微博不仅需要appkey和appsecret,而且还需要回调的url,这个链接是可以随便写的,但是需要和在开放平台申请的一致. 2. Android签名包信息部分 (1.)首先安卓 ...
- ios 为什么拖拽的控件为weak 手写的strong
ib拖拽的控件自动声明为weak 而平时自己手写的为strong 在ios中,对象默认都是强引用,不是强引用赋值后会立即释放 ib声明weak 不立即被释放 简单说就是 1.声明的弱引用指向强引用 ...
- 使用servicestack连接redis
引言:作为少有的.net架构下的大型网站,stackoverflow曾发表了一篇文章,介绍了其技术体系,原文链接http://highscalability.com/blog/2011/3/3/sta ...
- Flutter隐藏控件方法
new Offstage( offstage: true, //这里控制 child: Container(color: Colors.blue,height: 100.0,), ),