Kafka 0.10 Coordinator概述
由Kafka内置实现了失败检测和Rebalance(ZKRebalancerListener),但是它存在羊群效应和脑裂的问题,客户端代码实现低级API也不能解决这个问题。如果将失败探测和Rebalance的逻辑放到一个高可用的中心Coordinator,这两个问题即可解决。同时还可大大减少Zookeeper的负载,有利于Kafka Broker的扩展(Broker也会作为协调节点的角色存在)。
有几种类型:
- GroupCoordinator: GroupCoordinator handles general group membership and offset management. Each Kafka server instantiates a coordinator which is responsible for a set of groups. Groups are assigned to coordinators based on their group names.
- WorkerCoordinator:This class manages the coordination process with the Kafka group coordinator on the broker for managing assignments to workers.
- ConsumerCoordinator:This class manages the coordination process with the consumer coordinator.
中文:
- GroupCoordinator:broker端的,每个kafka server都有一个实例,管理部分的consumer group和它们的offset
- WorkerCoordinator:broker端的,管理GroupCoordinator程序,主要管理workers的分配。
- ConsumerCoordinator:consumer端的,管理ConsumerCoordinator程序。
1.Broker端的Coordinator
Kafka的group management protocol包括以下的动作序列:
- Group Registration:Group的成员需要向cooridnator注册自己,并且提供关于成员自身的元数据(比如,这个消费成员想要消费的topic)
- Group/Leader Selection:cooridnator确定这个group包括哪些成员,并且选择其中的一个作为leader。
- State Assignment: leader收集所有成员的metadata,并且给它们分配状态(state,可以理解为资源,或者任务)。
- Group Stabilization: 每个成员收到leader分配的状态,并且开始处理。
这里边有三个角色:coordinator, group memeber, group leader.
有这么几个情况:
- 所有的consumer线程要先向coordinator注册,由coordinator选出leader, 然后由leader来分配state。 从group memeber里选出来一个做为leader,由leader来执行性能开销大的协调任务, 这样把负载分配到client端,可以减轻broker的压力,支持更多数量的消费组。
- 所有group member(指的是consumer线程)都需要发心跳给coordinator,这样coordinator才能确定group的成员。
- 对于Kafka consumer,它的实际上必须跟coordinator保持连接,因为它还需要提交offset给coordinator。所以coordinator实际上负责commit offset,那么,即使leader来确定状态的分配,但是每个partition的消费起始点,还需要coordinator来确定。
问题:这就带来了一问题,每个partition的消费开始的offset是由leader向coordinator请求,然后做为state分配,还是leader只分配partition,而follower去coordinator处请求开始消费的offset?
回答:我从合理性来思考,coordinator向leader发送了topic-partition的Offset消费情况,leader分配好partition后,回传给leader。所有的follower同步这个状态。
2.客户端的ConsumerCoordinator
这张图展示了Server和Client端的关系。

ConsumerCoordinator是KafkaConsumer的一个成员变量,所以每个消费者都要自己的ConsumerCoordinator,消费者的ConsumerCoordintor只是和服务端的GroupCoordinator通信的介质。
下文中提到的协调者一般指的是服务端的GroupCoordinator。
每个KafkaServer都有一个GroupCoordinator实例,服务端的GroupCoordinator管理消费组成员和offset,它可以管理多个消费组(因为Broker本身即使存储一个topic的消息,也可以被不同的消费组订阅)。注意:组成员的状态管理(比如GroupMetadata)是在服务端的GroupCoordinator完成的,而不是由消费组的ConsumerCoordinator完成(因为消费者只能看到自己的,无法看到和自己同组的其他成员)。
3.Consumer消费者的工作过程:
- 在consumer启动时或者coordinator节点故障转移时,consumer发送ConsumerMetadataRequest给任意一个brokers。在ConsumerMetadataResponse中,它接收对应的Consumer Group所属的Coordinator的位置信息。
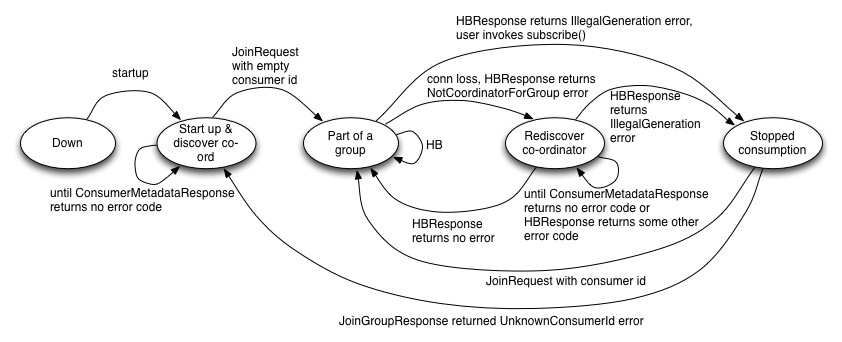
- Consumer连接Coordinator节点,并发送HeartbeatRequest。如果返回的HeartbeatResponse中返回IllegalGeneration错误码,说明协调节点已经在初始化平衡。消费者就会停止抓取数据,提交offsets,发送JoinGroupRequest给协调节点。在JoinGroupResponse,它接收消费者应该拥有的topic-partitions列表以及当前Consumer Group的新的generation编号。这个时候Consumer Group管理已经完成,Consumer就可以开始fetch数据,并为它拥有的partitions提交offsets。
- 如果HeartbeatResponse没有错误返回,Consumer会从它上次拥有的partitions列表继续抓取数据,这个过程是不会被中断的。

4. Coordinator协调节点的工作过程
- 在稳定状态下,Coordinator节点通过故障检测协议跟踪每个Consumer Group中每个Consumer的健康状况。
- 在选举和启动时,Coordinator节点读取它管理的Consumer Group列表,以及从ZK中读取每个消费组的成员信息。如果之前没有成员信息,它不会做任何动作。只有在同一个消费组的第一个消费者注册进来时,Coordinator节点才开始工作(即开始加载Group的Consumer成员信息)。
- 当Coordinator节点完全加载完它所负责的Consumer Group列表的所有组成员之前,它会在以下几种请求的响应中返回CoordinatorStartupNotComplete错误码:HeartbeatRequest,OffsetCommitRequest,JoinGroupRequest。这样消费者就会过段时间重试(直到完全加载,没有错误码返回为止)。
- 在选举或启动时,Coordinator节点会对消费组中的所有消费者进行故障检测。根据故障检测协议被协调节点标记为Dead的消费者会从消费组中移除,这个时候协调节点会为Dead的消费者所属的消费组触发一个Rebalance操作(消费者Dead之后,这个消费者拥有的partition需要平衡给其他消费者)。
- 当HeartbeatResponse返回IllegalGeneration错误码,就会触发平衡操作。一旦所有存活的Consumer通过JoinGroupRequests重新注册到Coordinator节点,Coordinator节点会将最新的partition所有权信息在JoinGroupResponse的每个消费者之间通信(同步),然后就完成了Rebalance操作。
- Coordinator节点会跟踪任何一个Consumer已经注册的topics的topic-partition的变更。如果它检测到某个topic新增的partition,就会触发Rebalance操作。当创建一个新的topics也会触发Rebalance操作,因为消费者可以在topic被创建之前就注册它感兴趣的topics。
Consumer状态机
Coordinator状态机
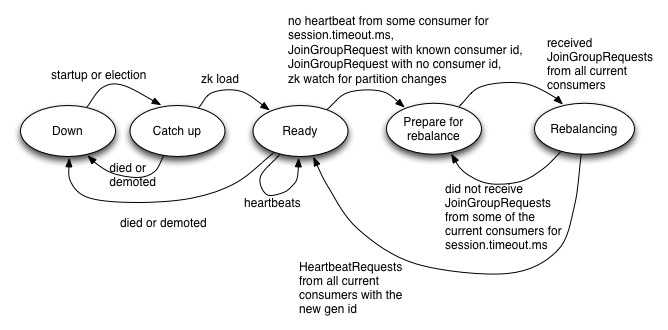
当Coordinator发生故障时,Consumer发现new Coordinator的顺序可能发生在新的协调者完成故障处理(包括从zk中加载消费组元数据等)之前或之后。如果在完成故障处理之后才发现new Coordinator,new Coordinator就会像之前一样接收消费者的心跳请求。而如果是在之前,新的协调者则会拒绝消费者的心跳请求,会导致消费者重新发现协调者,并重新连接协调者。如果消费者太晚连接新的协调者,协调者可能会标记消费者挂掉了,消费者再次加入时,会认为这是一个新的消费者,并触发rebalance。
消费者发现新的协调者(co-ordinator re-discovery),包括两个步骤,首先确定新的协调者,然后消费者连接协调者。如果新的协调者确定了,并且消费者成功连接上新协调者,这样消费者发送的心跳请求就会被新的协调者正常接收。但是如果新协调者已经确定,而消费者并没有连接上新的协调者,消费者发送的心跳请求并不会被接收:因为连接都还没有建立!
5.Coordinator存储的信息有什么
对于每个Consumer Group,Coordinator会存储以下信息:
1) 对每个存在的topic,可以有多个消费组group订阅同一个topic(对应消息系统中的广播)
2) 对每个Consumer Group,元数据如下:
- 订阅的topics列表
- Consumer Group配置信息,包括session timeout等
- 组中每个Consumer的元数据。包括主机名,consumer id
- 每个正在消费的topic partition的当前offsets
- Partition的ownership元数据,包括consumer消费的partitions映射关系
没看完,这里还有更多的细节, 博文
Kafka 0.10 Coordinator概述的更多相关文章
- Kafka 0.10问题点滴
15.如何消费内部topic: __consumer_offsets 主要是要让它来格式化:GroupMetadataManager.OffsetsMessageFormatter 最后用看了它的源码 ...
- Kafka 0.10.1版本源码 Idea编译
Kafka 0.10.1版本源码 Idea编译 1.环境准备 Jdk 1.8 Scala 2.11.12:下载scala-2.11.12.msi并配置环境变量 Gradle 5.6.4: 下载Grad ...
- Kafka 0.10 KafkaConsumer流程简述
ConsumerConfig.scala 储存Consumer的配置 按照我的理解,0.10的Kafka没有专门的SimpleConsumer,仍然是沿用0.8版本的. 1.从poll开始 消费的规则 ...
- kafka 0.10.2 消息消费者
package cn.xiaojf.kafka.consumer; import org.apache.kafka.clients.consumer.ConsumerConfig; import or ...
- kafka 0.10.2 cetos6.5 集群部署
安装 zookeeper http://www.cnblogs.com/xiaojf/p/6572351.html安装 scala http://www.cnblogs.com/xiaojf/p/65 ...
- Kafka 0.10.0
2.1 Producer API We encourage all new development to use the new Java producer. This client is produ ...
- Kafka 0.10.1.1 特点
1.Consumer优化:心跳线程可作为后台线程,提交offset,剥离出poll函数 问题:0.10新设计的consumer是单线程的,提交offset是在poll中.本次的poll调用,提交上次p ...
- kafka 0.10.2 消息生产者(producer)
package cn.xiaojf.kafka.producer; import org.apache.kafka.clients.producer.*; import org.apache.kafk ...
- kafka 0.10.2 消息生产者
package cn.xiaojf.kafka.producer; import org.apache.kafka.clients.producer.KafkaProducer; import org ...
随机推荐
- <面向对象程序设计>课程作业一
Github链接 在看完这次的作业要求后我整个人是混乱的,因为作业要求把不同的函数放在一个main函数中:我们之前也是进行了函数分离,但是是放在了不同的文件中.如果要改的话相当于重写(而且这两种形式其 ...
- Flask-论坛开发-5-memcached缓存系统
对Flask感兴趣的,可以看下这个视频教程:http://study.163.com/course/courseLearn.htm?courseId=1004091002 ### 介绍:哪些情况下适合 ...
- [2017BUAA软件工程]第0次作业
第一部分:结缘计算机 1. 你为什么选择计算机专业?你认为你的条件如何?和这些博主比呢?(必答) 选择计算机专业的一个重要原因是因为计算机专业的就业前景好,由于计算机本身具有的各种优点,现在几乎所有的 ...
- PAT 1033 旧键盘打字
https://pintia.cn/problem-sets/994805260223102976/problems/994805288530460672 旧键盘上坏了几个键,于是在敲一段文字的时候, ...
- QQ的小秘密
http://ssl.ptlogin2.qq.com/test http://ping.huatuo.qq.com/ http://localhost.ptlogin2.qq.com:4300/mc_ ...
- ECSHOP后台登陆后一段时间不操作就超时的解决方法
ECSHOP后台登陆后一段时间不操作就超时的解决方法 ECSHOP教程/ ecshop教程网(www.ecshop119.com) 2012-05-27 客户生意比较好,因此比较忙,常常不在电脑前 ...
- mysql理论结合实际篇(一)
最近两天做需求,是要将退款和退货报表里使用的临时表改用固定表, 自己建表时,如(只是举例): CREATE TABLE tasks ( task_id INT UNSIGNED NOT NULL AU ...
- Bootstrap洼地
前面的话 这是一个轻量.灵活的组件,它能延伸至整个浏览器视口来展示网站上的关键内容.本文将详细介绍Bootstrap洼地 概述 洼地(Well)样式的效果和巨幕jumbotron样式类似,不同点是we ...
- BZOJ5361[Lydsy1805月赛]对称数——主席树+随机化
题目链接:https://www.lydsy.com/JudgeOnline/problem.php?id=5361 好神的一道题啊! 容易看出来是要用维护权值的数据结构,因此树链剖分首先pass掉. ...
- BZOJ1041 HAOI2008圆上的整点(数论)
求x2+y2=r2的整数解个数,显然要化化式子.考虑求正整数解. y2=r2-x2→y2=(r-x)(r+x)→(r-x)(r+x)为完全平方数→(r-x)(r+x)/d2为完全平方数,d=gcd(r ...