scala操作HBase2.0
在前面:
scala:2.12
hbase:2.0.2
开发工具:IDEA
准备工作:
1、将生产上的hbase中的conf/hbase-site.xml文件拷贝到idea中的src/resources目录下
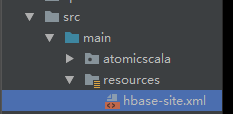
2、将生产环境中hbase中的$HBASE_HOME/lib下的*.jar文件加载到IDEA中

3、点击libraries->中间的"+" ->java
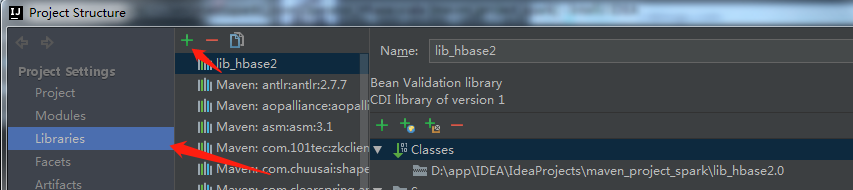
4、选择jar包所放的位置,点击OK
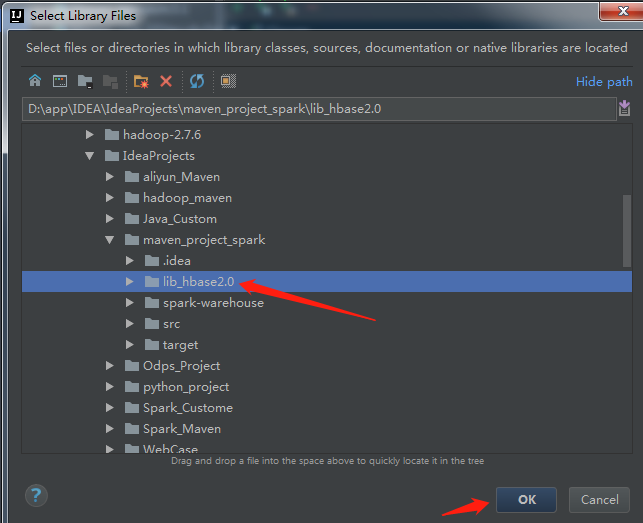
5、继续点击ok即可
6、进行连接代码编写:
package spark._core import java.io.IOException
import java.util.UUID import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase._
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter
import org.apache.hadoop.hbase.filter.SubstringComparator
import org.apache.hadoop.hbase.util.Bytes
import parquet.org.slf4j.LoggerFactory /**
* Author Mr. Guo
* Create 2018/11/5 - 19:08
*/
object Operator_Hbase { def LOG = LoggerFactory.getLogger(getClass) def getHbaseConf: Configuration = {
val conf: Configuration = HBaseConfiguration.create
conf.addResource(".\\main\\resources\\hbase-site.xml")
conf.set("hbase.zookeeper.property.clientPort","2181")
/*conf.set("spark.executor.memory","3000m")
conf.set("hbase.zookeeper.quorum","master,slave1,slave2")
conf.set("hbase.master","master:60000")
conf.set("hbase.rootdir","Contant.HBASE_ROOTDIR")*/
conf
} //创建一张表
@throws(classOf[MasterNotRunningException])
@throws(classOf[ZooKeeperConnectionException])
@throws(classOf[IOException])
def createTable(hbaseconn: Connection, tableName: String, columnFamilys: Array[String]) = {
//建立一个数据库操作对象
var admin: Admin = hbaseconn.getAdmin;
var myTableName: TableName = TableName.valueOf(tableName)
if (admin.tableExists(myTableName)) {
LOG.info(tableName + "Table exists!")
} else {
val tableDesc: HTableDescriptor = new HTableDescriptor(myTableName)
tableDesc.addCoprocessor("org.apache.hadoop.hbase.coprocessor.AggregateImplementation")
for (columnFamily <- columnFamilys) {
val columnDesc: HColumnDescriptor = new HColumnDescriptor(columnFamily)
tableDesc.addFamily(columnDesc)
}
admin.createTable(tableDesc)
LOG.info(tableName + "create table success!")
}
admin.close()
} //载入数据
def addRow(table: Table, rowKey: String, columnFamily: String, quorm: String, value: String) = {
val rowPut: Put = new Put(Bytes.toBytes(rowKey))
if (value == null) {
rowPut.addColumn(columnFamily.getBytes, quorm.getBytes, "".getBytes())
} else {
rowPut.addColumn(columnFamily.getBytes, quorm.getBytes, value.getBytes)
}
table.put(rowPut)
} //获取数据
def getRow(table: Table, rowKey: String): Result = {
val get: Get = new Get(Bytes.toBytes(rowKey))
val result: Result = table.get(get)
for (rowKv <- result.rawCells()) {
println("Famiily:" + new String(rowKv.getFamilyArray, rowKv.getFamilyOffset, rowKv.getFamilyLength, "UTF-8"))
println("Qualifier:" + new String(rowKv.getQualifierArray, rowKv.getQualifierOffset, rowKv.getQualifierLength, "UTF-8"))
println("TimeStamp:" + rowKv.getTimestamp)
println("rowkey:" + new String(rowKv.getRowArray, rowKv.getRowOffset, rowKv.getRowLength, "UTF-8"))
println("Value:" + new String(rowKv.getValueArray, rowKv.getValueOffset, rowKv.getValueLength, "UTF-8"))
}
return result
} //批量添加数据
def addDataBatch(table: Table, list: java.util.List[Put]) = {
try {
table.put(list)
} catch {
case e: RetriesExhaustedWithDetailsException => {
LOG.error(e.getMessage)
}
case e: IOException => {
LOG.error(e.getMessage)
}
}
} //查询全部
def queryAll(table: Table): ResultScanner = {
val scan: Scan = new Scan
try {
val s = new Scan()
val result: ResultScanner = table.getScanner(s)
return result
} catch {
case e: IOException => {
LOG.error(e.toString)
}
}
return null
} //查询条记录
def queryBySingleColumn(table: Table, queryColumn: String, value: String, columns: Array[String]): ResultScanner = {
if (columns == null || queryColumn == null || value == null) {
return null
}
try {
val filter: SingleColumnValueFilter = new SingleColumnValueFilter(Bytes.toBytes(queryColumn),
Bytes.toBytes(queryColumn),CompareOp.EQUAL,new SubstringComparator(value))
val scan: Scan = new Scan()
for (columnName <- columns) {
scan.addColumn(Bytes.toBytes(columnName), Bytes.toBytes(columnName))
}
scan.setFilter(filter)
return table.getScanner(scan)
} catch {
case e: Exception => {
LOG.error(e.toString)
}
}
return null
} //删除表
def dropTable(hbaseconn: Connection, tableName: String) = {
try {
val admin: HBaseAdmin = hbaseconn.getAdmin.asInstanceOf[HBaseAdmin]
admin.disableTable(TableName.valueOf(tableName))
admin.deleteTable(TableName.valueOf(tableName))
} catch {
case e: MasterNotRunningException => {
LOG.error(e.toString)
}
case e: ZooKeeperConnectionException => {
LOG.error(e.toString)
}
case e: IOException => {
LOG.error(e.toString)
}
} } def main(args: Array[String]): Unit = {
val conf: Configuration = getHbaseConf
val conn = ConnectionFactory.createConnection(conf)
//定义表名称
val table:Table = conn.getTable(TableName.valueOf("test"))
try {
//列族fam1,fam2
val familyColumn:Array[String] = Array[String]("info1","info2")
//建表
// createTable(conn,"test",familyColumn) val uuid:UUID = UUID.randomUUID()
val s_uuid:String = uuid.toString //载入数据
// addRow(table,s_uuid,"info","column1A",s_uuid+"_1A") //获取表中所有数据
// getRow(table,"9ec78ac4-6042-4c34-8862-f5aca3e")
//删除表
// dropTable(conn,"test")
}catch{
case e:Exception => {
if (e.getClass == classOf[MasterNotRunningException]){
System.out.println("MasterNotRunningException")
}
if (e.getClass == classOf[ZooKeeperConnectionException]){
System.out.println("ZooKeeperConnectionException")
}
if (e.getClass == classOf[IOException]){
System.out.println("IOException")
}
e.printStackTrace()
}
}finally{
if (null != table){
table.close()
}
}
}
}
7、实际操作的过程中可能会遇到如下问题:

解决方案:
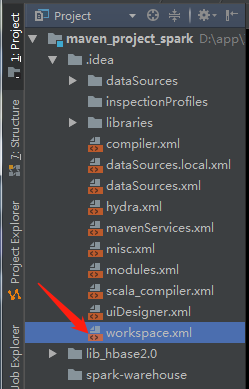
双击打开该文件,找到标签 <component name="PropertiesComponent"> , 在标签里加一行 <property name="dynamic.classpath" value="true" />

保存即可
scala操作HBase2.0的更多相关文章
- Scala操作Hbase空指针异常java.lang.NullPointerException处理
Hbase版本:Hortonworks Hbase 1.1.2 问题描述:使用Scala操作Hbase时,发生空指针异常(java.lang.RuntimeException: java.lang.N ...
- HBase2.0中的Benchmark工具 — PerformanceEvaluation
简介 在项目开发过程中,我们经常需要一些benchmark工具来对系统进行压测,以获得系统的性能参数,极限吞吐等等指标. 而在HBase中,就自带了一个benchmark工具—PerformanceE ...
- HBase2.0新特性解析
作者 | 个推大数据运维工程师 行者 升级背景 个推作为专业的数据智能服务商,在业务开展过程中存在海量的数据存储与查询的需求,为此个推选用了高可靠.高性能.面向列.可伸缩的分布式数据存储系统--HBa ...
- geotrellis使用(五)使用scala操作Accumulo
要想搞明白Geotrellis的数据处理情况,首先要弄清楚数据的存放,Geotrellis将数据存放在Accumulo中. Accumulo是一个分布式的Key Value型NOSQL数据库,官网为( ...
- Hbase-2.0.0_01_安装部署
该文章是基于 Hadoop2.7.6_01_部署 进行的 1. 主机规划 主机名称 IP信息 内网IP 操作系统 安装软件 备注:运行程序 mini01 10.0.0.11 172.16.1.11 C ...
- 基于Hadoop2.6.5(HA)的HBase2.0.5配置
1.配置 在CentOS7Three上配置,注意:一定要安装bin包,不能安装src包 /usr/local/hbase/hbase-2.0.5/conf 编辑hbase-env.sh,替换成如下配置 ...
- hbase2.0.0-安装部署
依赖hadoop 环境,我这边的版本是hadoop-2.6.5 选择hbase2.0.0版本的时候,去官网查看支持的hadoop版本 1.伪分布式安装 下载:http://mirror.bit.edu ...
- Scala操作MongoDB
Scala操作MongoDB // Maven <dependencies> <dependency> <groupId>org.mongodb</group ...
- [转] Scala 2.10.0 新特性之字符串插值
[From] https://unmi.cc/scala-2-10-0-feature-string-interpolation/ Scala 2.10.0 新特性之字符串插值 2013-01-20 ...
随机推荐
- pytorch 中的重要模块化接口nn.Module
torch.nn 是专门为神经网络设计的模块化接口,nn构建于autgrad之上,可以用来定义和运行神经网络 nn.Module 是nn中重要的类,包含网络各层的定义,以及forward方法 对于自己 ...
- git diff 结果分析
git diff 的5个使用场景: 1.staging area和working area的文件 (无其他参数时) git diff 2.master分支和working area的文件 (用ma ...
- js--单选按钮赋值
var sex='${userInfo.sex}'; if(sex=="女"){ $("input[name=sex][value='女']").attr(&q ...
- you-get模块
You-Get是一个基于 Python 3 的下载工具.使用 You-Get 可以很轻松的下载到网络上的视频.图片及音乐. 转载https://www.cnblogs.com/wangchuanyan ...
- (转)git 忽略规则
对于经常使用Git的朋友来说,.gitignore配置一定不会陌生.废话不说多了,接下来就来说说这个.gitignore的使用. 首先要强调一点,这个文件的完整文件名就是".gitignor ...
- aws cloudwatch监控怎么通过钉钉机器人报警
最近在完善海外业务在aws服务的CloudWatchh监控,发现CloudWatch报警通知要通过aws的sns服务,直接支持的通道有短信和邮件,但是我们想推到钉钉群里面的群机器人里面这个就要借助aw ...
- 【LeetCode每天一题】Maximum Subarray(最大子数组)
Given an integer array nums, find the contiguous subarray (containing at least one number) which has ...
- oracle 新建用户后赋予的权限语句
grant create session,resource to itsys; grant create table to itsys;grant resource to itsys;grant cr ...
- docker从容器中怎么访问宿主机
docker从容器中怎么访问宿主机 我来答 浏览 3160 次 2个回答 #热议# 2019年全国两会召开,哪些提案和政策值得关注? 好程序员 知道合伙人 推荐于2017-11-22 dock ...
- 200. Number of Islands(DFS)
Given a 2d grid map of '1's (land) and '0's (water), count the number of islands. An island is surro ...