Apache kylin进阶——元数据篇
一、Apache kylin元数据的存储
Apache kylin的元数据包括 立方体描述(cube description),立方体实例(cube instances)项目(project)、作业(job)、表(table)、字典(dictionary),参见: Apache kylin 核心概念。在kylin集群中至关重要,假如元数据丢失,kylin集群将无法工作。
在kylin 的设计中,元数据存储的类图如下:
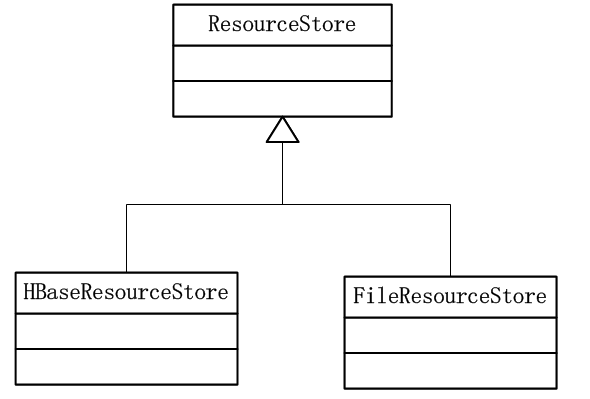
可见kylin提供了两种方式存储元数据,一般而言,集群模式的元数据都选择在hbase中存储。在${KYLIN_HOME}/conf/kylin.properties中,元数据的默认配置如下:
kylin.metadata.url=kylin_metadata@hbase
kylin_metadata@hbase表示,元数据存储在hbase中的kylin_metadata表中。HBaseResourceStore#HBaseResourceStore的参考代码如下:
public HBaseResourceStore(KylinConfig kylinConfig) throws IOException {
super(kylinConfig); String metadataUrl = kylinConfig.getMetadataUrl();
// split TABLE@HBASE_URL
int cut = metadataUrl.indexOf('@');
tableNameBase = cut < 0 ? DEFAULT_TABLE_NAME : metadataUrl.substring(0, cut);
hbaseUrl = cut < 0 ? metadataUrl : metadataUrl.substring(cut + 1); createHTableIfNeeded(getAllInOneTableName());
}
如若存储kylin元数据在本地文件系统中,需将kylin.metadata.url 指向本地文件系统的一个绝对路径, 如:可在${KYLIN_HOME}/conf/kylin.properties中配置如下:
kylin.metadata.url=/home/${username}/${kylin_home}/kylin_metada
注意,一定要是绝对路径,否则会出现错误。
当选择元数据存储在hbase中时,并非所有的数据都在hbase中,当待存储的记录(通常是key-value pairs)的value大于一个最大值kvSizeLimit时,数据将被保存在HDFS中,默认路径为:/kylin/kylin_metadata/,相关配置项在${KYLIN_HOME}/conf/kylin.properties中,如下:
- kylin.hdfs.working.dir=/kylin
- kylin.metadata.url=kylin_metadata@hbase
HBaseResourceStore#buildPut的参考代码如下:
private Put buildPut(String resPath, long ts, byte[] row, byte[] content, HTableInterface table) throws IOException {
int kvSizeLimit = this.kylinConfig.getHBaseKeyValueSize();
if (content.length > kvSizeLimit) {
writeLargeCellToHdfs(resPath, content, table);
content = BytesUtil.EMPTY_BYTE_ARRAY;
} Put put = new Put(row);
put.add(B_FAMILY, B_COLUMN, content);
put.add(B_FAMILY, B_COLUMN_TS, Bytes.toBytes(ts)); return put;
}
kvSizeLimit 的获取代码如下:
public int getHBaseKeyValueSize() {
return Integer.parseInt(this.getOptional("kylin.hbase.client.keyvalue.maxsize", "10485760"));
}
默认值为10M,可在在${KYLIN_HOME}/conf/kylin.properties中配置:
kylin.hbase.client.keyvalue.maxsize=10485760
注意,该值的大小十分重要,因为kylin为了提高整体性能将hbase中的元数据缓存在hbase内存中,如下图:

随着每天 cube的增量build,该表会越来越大。假如不及时清理历史数据,将会使hbase的进程发生 OutOfMemoryError错误!这里kvSizeLimit需在性能和内存大小之间做一个权衡。
二、Apache kylin元数据的运维
当前kylin的元数据只提供了冷备份的方式。
可利用crontab 在${KYLIN_HOME}下,每天定时执行./bin/metastore.sh backup命令,kylin会将元数据信息保存如下目录:
${KYLIN_HOME}/meta_backups/meta_year_month_day_hour_minute_second
当kylin元数据损坏或不一致,可采用如下命令恢复:
- cd ${KYLIN_HOME}
- sh ./bin/metastore.sh reset
- sh ./bin/metastore.sh restore ./meta_backups/meta_xxxx_xx_xx_xx_xx_xx
参考文档:
[1].http://kylin.apache.org/docs15/howto/howto_backup_metadata.html
Apache kylin进阶——元数据篇的更多相关文章
- 《基于Apache Kylin构建大数据分析平台》
Kyligence联合创始人兼CEO,Apache Kylin项目管理委员会主席(PMC Chair)韩卿 武汉市云升科技发展有限公司董事长,<智慧城市-大数据.物联网和云计算之应用>作者 ...
- Apache Kylin高级部分之使用Hive视图
本章节我们将介绍为什么须要在Kylin创建Cube过程中使用Hive视图.而假设使用Hive视图.能够带来什么优点.解决什么样的问题.以及须要学会怎样使用视图.使用视图有什么限制等等. 1. ...
- Apache kylin 入门
本篇文章就概念.工作机制.数据备份.优势与不足4个方面详细介绍了Apache Kylin. Apache Kylin 简介 1. Apache kylin 是一个开源的海量数据分布式预处理引擎.它通过 ...
- 【转】Apache Kylin 2.0为大数据带来交互式的BI
本文转载自:[技术帖]Apache Kylin 2.0为大数据带来交互式的BI 编者注:Kyligence的联合创始人兼CEO Luke Han在上做题为“”的演讲. 基于Hadoop的SQL一直在被 ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- Apache kylin的基础环境
一.Apache kylin的基础环境 由于Apache kylin上的OLAP(wiki:OLAP)是构建在hadoop生态环境上的,所以hadoop环境的稳定性和健壮性对kylin的稳定运行至关重 ...
- 分布式大数据多维分析(OLAP)引擎Apache Kylin安装配置及使用示例【转】
Kylin 麒麟官网:http://kylin.apache.org/cn/download/ 关键字:olap.Kylin Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的 ...
- APACHE KYLIN™ 概览
APACHE KYLIN™ 概览 Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发 ...
- APACHE KYLIN™ 概览(分布式分析引擎)
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区.它能 ...
随机推荐
- sql 索引笔记--索引组织结构
非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点: 基础表的数据行不按非聚集键的顺序排序和存储. 非聚集索引的叶层是由索引页而不是由数据页组成. 既可以使用聚集索引来为表或视 ...
- [原创]Robo 3T 1.2.1 工具使用介绍
[原创]Robo 3T 1.2.1 工具使用介绍 1 Robo 3T 1.2.1 简介 robo 3t 是一款MongoDB的辅助插件,可以帮助您在管理数据库内容以及数据库代码编辑方面提供一定的开发 ...
- C#多线程技术提高RabbitMQ消费吞吐率
一.课程介绍 本次分享课程属于<C#高级编程实战技能开发宝典课程系列>中的第二部分,阿笨后续会计划将实际项目中的一些比较实用的关于C#高级编程的技巧分享出来给大家进行学习,不断的收集.整理 ...
- xinetd服务
xinetd(eXtended InterNET services daemon) 一.xinetd的功能介绍: xinetd提供类似于inetd+tcp_wrapper的功能,但是更加强大和安全.它 ...
- .Net转Java.05.为啥MySQL没有nolock
今天忽然想到一个问题,原来为了提高SQL Server性能,公司规定查询语句一般都要加 WITH (NOLOCK)的 现在转Java了,用了MySQL为啥不提这个事情了? 先在MySQL里写了一个查询 ...
- 对Unity的Resources目录进行改名
项目用的是Unity5.5版本,开发的时候将相关的图集.预制对象资源都放在 Resources 目录下,而真机使用的是 StreamingAssets 目录下的资源. Resources(不分层级)在 ...
- Lua MD5加密字符串
function md5_sumhexa(k) local md5_core = require "md5.core" k = md5_core.sum(k) return (st ...
- wget整站抓取、网站抓取功能;下载整个网站;下载网站到本地
wget -r -p -np -k -E http://www.xxx.com 抓取整站 wget -l 1 -p -np -k http://www.xxx.com 抓取第一级 - ...
- 分布式架构探索 - 2. WebService RPC框架之Apache CXF
Apache CXF是一个开源的WebService RPC框架. 例子: 1. 新建一个maven web项目, 添加pom 如下: <?xml version="1.0" ...
- VS Code 插件
https://blog.fundebug.com/2018/07/24/vs-extensions/