Apache kylin进阶——元数据篇
一、Apache kylin元数据的存储
Apache kylin的元数据包括 立方体描述(cube description),立方体实例(cube instances)项目(project)、作业(job)、表(table)、字典(dictionary),参见: Apache kylin 核心概念。在kylin集群中至关重要,假如元数据丢失,kylin集群将无法工作。
在kylin 的设计中,元数据存储的类图如下:
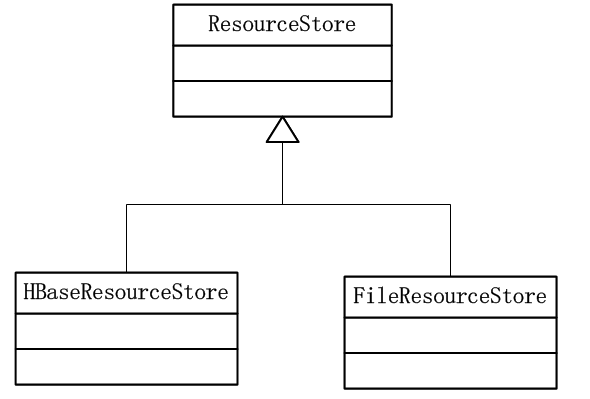
可见kylin提供了两种方式存储元数据,一般而言,集群模式的元数据都选择在hbase中存储。在${KYLIN_HOME}/conf/kylin.properties中,元数据的默认配置如下:
kylin.metadata.url=kylin_metadata@hbase
kylin_metadata@hbase表示,元数据存储在hbase中的kylin_metadata表中。HBaseResourceStore#HBaseResourceStore的参考代码如下:
public HBaseResourceStore(KylinConfig kylinConfig) throws IOException {
super(kylinConfig); String metadataUrl = kylinConfig.getMetadataUrl();
// split TABLE@HBASE_URL
int cut = metadataUrl.indexOf('@');
tableNameBase = cut < 0 ? DEFAULT_TABLE_NAME : metadataUrl.substring(0, cut);
hbaseUrl = cut < 0 ? metadataUrl : metadataUrl.substring(cut + 1); createHTableIfNeeded(getAllInOneTableName());
}
如若存储kylin元数据在本地文件系统中,需将kylin.metadata.url 指向本地文件系统的一个绝对路径, 如:可在${KYLIN_HOME}/conf/kylin.properties中配置如下:
kylin.metadata.url=/home/${username}/${kylin_home}/kylin_metada
注意,一定要是绝对路径,否则会出现错误。
当选择元数据存储在hbase中时,并非所有的数据都在hbase中,当待存储的记录(通常是key-value pairs)的value大于一个最大值kvSizeLimit时,数据将被保存在HDFS中,默认路径为:/kylin/kylin_metadata/,相关配置项在${KYLIN_HOME}/conf/kylin.properties中,如下:
- kylin.hdfs.working.dir=/kylin
- kylin.metadata.url=kylin_metadata@hbase
HBaseResourceStore#buildPut的参考代码如下:
private Put buildPut(String resPath, long ts, byte[] row, byte[] content, HTableInterface table) throws IOException {
int kvSizeLimit = this.kylinConfig.getHBaseKeyValueSize();
if (content.length > kvSizeLimit) {
writeLargeCellToHdfs(resPath, content, table);
content = BytesUtil.EMPTY_BYTE_ARRAY;
} Put put = new Put(row);
put.add(B_FAMILY, B_COLUMN, content);
put.add(B_FAMILY, B_COLUMN_TS, Bytes.toBytes(ts)); return put;
}
kvSizeLimit 的获取代码如下:
public int getHBaseKeyValueSize() {
return Integer.parseInt(this.getOptional("kylin.hbase.client.keyvalue.maxsize", "10485760"));
}
默认值为10M,可在在${KYLIN_HOME}/conf/kylin.properties中配置:
kylin.hbase.client.keyvalue.maxsize=10485760
注意,该值的大小十分重要,因为kylin为了提高整体性能将hbase中的元数据缓存在hbase内存中,如下图:

随着每天 cube的增量build,该表会越来越大。假如不及时清理历史数据,将会使hbase的进程发生 OutOfMemoryError错误!这里kvSizeLimit需在性能和内存大小之间做一个权衡。
二、Apache kylin元数据的运维
当前kylin的元数据只提供了冷备份的方式。
可利用crontab 在${KYLIN_HOME}下,每天定时执行./bin/metastore.sh backup命令,kylin会将元数据信息保存如下目录:
${KYLIN_HOME}/meta_backups/meta_year_month_day_hour_minute_second
当kylin元数据损坏或不一致,可采用如下命令恢复:
- cd ${KYLIN_HOME}
- sh ./bin/metastore.sh reset
- sh ./bin/metastore.sh restore ./meta_backups/meta_xxxx_xx_xx_xx_xx_xx
参考文档:
[1].http://kylin.apache.org/docs15/howto/howto_backup_metadata.html
Apache kylin进阶——元数据篇的更多相关文章
- 《基于Apache Kylin构建大数据分析平台》
Kyligence联合创始人兼CEO,Apache Kylin项目管理委员会主席(PMC Chair)韩卿 武汉市云升科技发展有限公司董事长,<智慧城市-大数据.物联网和云计算之应用>作者 ...
- Apache Kylin高级部分之使用Hive视图
本章节我们将介绍为什么须要在Kylin创建Cube过程中使用Hive视图.而假设使用Hive视图.能够带来什么优点.解决什么样的问题.以及须要学会怎样使用视图.使用视图有什么限制等等. 1. ...
- Apache kylin 入门
本篇文章就概念.工作机制.数据备份.优势与不足4个方面详细介绍了Apache Kylin. Apache Kylin 简介 1. Apache kylin 是一个开源的海量数据分布式预处理引擎.它通过 ...
- 【转】Apache Kylin 2.0为大数据带来交互式的BI
本文转载自:[技术帖]Apache Kylin 2.0为大数据带来交互式的BI 编者注:Kyligence的联合创始人兼CEO Luke Han在上做题为“”的演讲. 基于Hadoop的SQL一直在被 ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- Apache kylin的基础环境
一.Apache kylin的基础环境 由于Apache kylin上的OLAP(wiki:OLAP)是构建在hadoop生态环境上的,所以hadoop环境的稳定性和健壮性对kylin的稳定运行至关重 ...
- 分布式大数据多维分析(OLAP)引擎Apache Kylin安装配置及使用示例【转】
Kylin 麒麟官网:http://kylin.apache.org/cn/download/ 关键字:olap.Kylin Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的 ...
- APACHE KYLIN™ 概览
APACHE KYLIN™ 概览 Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发 ...
- APACHE KYLIN™ 概览(分布式分析引擎)
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区.它能 ...
随机推荐
- 【树形dp入门】没有上司的舞会 @洛谷P1352
传送门 题目描述 某大学有N个职员,编号为1~N.他们之间有从属关系,也就是说他们的关系就像一棵以校长为根的树,父结点就是子结点的直接上司.现在有个周年庆宴会,宴会每邀请来一个职员都会增加一定的快乐指 ...
- html的文字样式、下行线、删除线、上标、下标等实现方式
先看效果如下: 代码如下: <del>del标签删除线</del><br/> <strike>strike标签删除线</strike>< ...
- 【】tensorflow学习笔记
一.看懂了Tensor("mul_1:0", shape=(), dtype=int32)中的shape https://blog.csdn.net/u013378306/arti ...
- Office Web Apps 2013 修改Excel在线查看文件大小限制
前言 最近搭建了一个OWA 2013环境,帮客户实现在线查看Excel文档,不过,使用过程中出现了错误,文件大小超过10MB就无法预览了,查了好久,发现需要使用PowerShell命令进行修改. 1. ...
- How do I remove a particular element from an array in JavaScript?
9090down voteaccepted Find the index of the array element you want to remove, then remove that index ...
- [Vuex] Perform Async Updates using Vuex Actions with TypeScript
Mutations perform synchronous modifications to the state, but when it comes to make an asynchronous ...
- 在Ubuntu18.04下配置hadoop集群
服务器准备 启动hadoop最小集群的典型配置是3台服务器, 一台作为Master, NameNode, 两台作为Slave, DataNode. 操作系统使用的Ubuntu18.04 Server, ...
- SQL SERVER 批量生成编号
开始: 在testing中,为了模拟orders,有个要求给数据库dba,如何通过后台数据库脚本快速批量生成orders. 分析 站在数据库角度,批量生成orders,也就是批量生成表中的行数据. s ...
- 【20171123】【GITC精华演讲】贝业新兄弟李济宏:如何做到企业信息化建设的加减乘除
导读 11月23日智慧物流论坛上,贝业新兄弟李济宏分享了<如何做到企业信息化建设的加减乘除>演讲,介绍了如何更好的构建企业信息化系统. 30秒get演讲干货 为什么用户总说系统难用?为什么 ...
- AspectF写法
AspectF.Define .ProgressBar(caption) .Do(() => { if (!SpecialMenuClick(midForm, tag)) { DockBarSh ...