python数据分析及展示(三)
一、Pandas库入门
1. Pandas库的介绍
Pandas是Python第三方库,提供高性能易用数据类型和分析工具
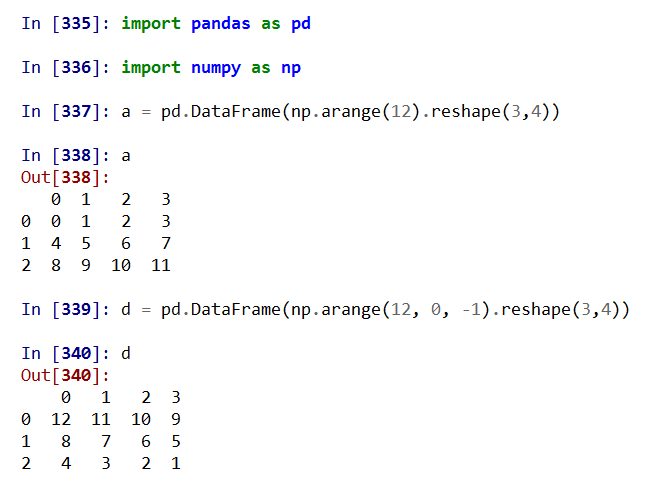
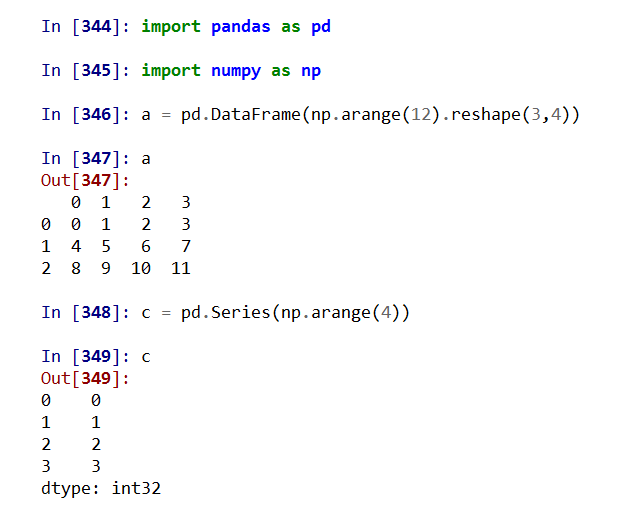
import pandas as pd
Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用
两个数据类型:Series, DataFrame
基于上述数据类型的各类操作:基本操作、运算操作、特征类操作、关联类操作
NumPy Pandas
基础数据类型 扩展数据类型
关注数据的结构表达 关注数据的应用表达
维度:数据间关系 数据与索引间关系
2. Pandas的Series类型
Series类型由一组数据及与之相关的数据索引组成
数据 索引
index_0 data_a
index_1 data_b
index_2 data_c
index_3 data_d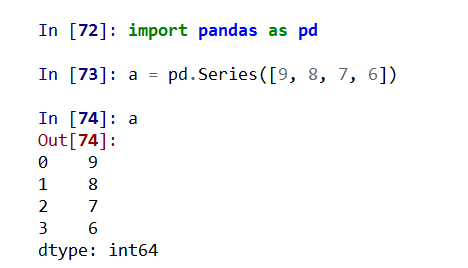
自定义索引,作为第二个参数,可以省略index=

Series类型可以由如下类型创建:
• Python列表
• 标量值
• Python字典
• ndarray
• 其他函数
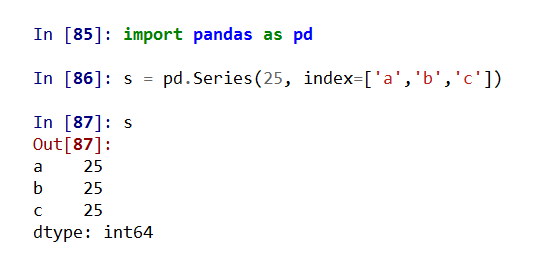
(1)从标量值创建,不能省略index
(2)从字典类型创建,还可以从字典中进行选择操作


(3)从ndarray类型创建


Series类型可以由如下类型创建:
• Python列表,index与列表元素个数一致
• 标量值,index表达Series类型的尺寸
• Python字典,键值对中的“键”是索引,index从字典中进行选择操作
• ndarray,索引和数据都可以通过ndarray类型创建
• 其他函数,range()函数等
Series类型的基本操作
Series类型包括index和values两部分
Series类型的操作类似ndarray类型
Series类型的操作类似Python字典类型


自动索引和自定义索引并存,但不能混用。
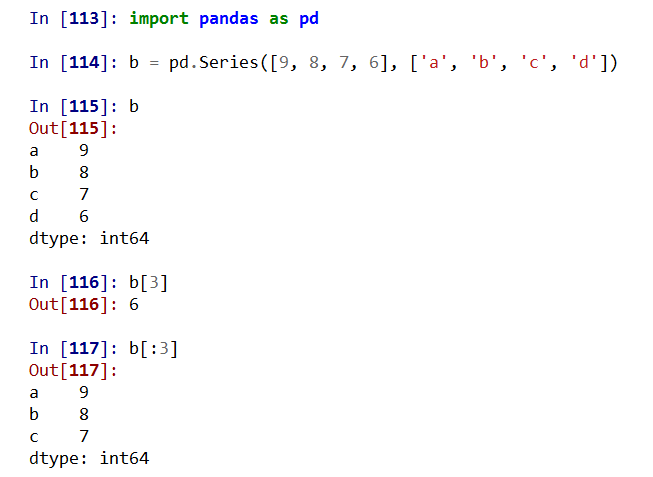
Series类型的操作类似ndarray类型:
• 索引方法相同,采用[]
• NumPy中运算和操作可用于Series类型
• 可以通过自定义索引的列表进行切片
• 可以通过自动索引进行切片,如果存在自定义索引,则一同被切片

Series类型的操作类似Python字典类型:
• 通过自定义索引访问
• 保留字in操作,对索引进行操作
• 使用.get()方法,取某个索引的值,如果没有,则赋给定的值。

Series类型在运算中会自动对齐不同索引的数据,如果对应不上,则为空。

Series对象和索引都可以有一个名字,存储在属性.name中

Series对象可以随时修改并即刻生效


Series是一维带“标签”数组
index_0 → data_a
Series基本操作类似ndarray和字典,根据索引对齐
3. Pandas库的DataFrame类型
DataFrame类型由共用相同索引的一组列组成
索引 多列数据
index_0 → data_a data_1 ... data_w
index_1 → data_b data_2 ... data_y
index_2 → data_c data_3 ... data_x
index_3 → data_d data_4 ... data_z
index axis=0
column axis=1
DataFrame是一个表格型的数据类型,每列值类型可以不同
DataFrame既有行索引、也有列索引
DataFrame常用于表达二维数据,但可以表达多维数据
DataFrame类型可以由如下类型创建:
• 二维ndarray对象
• 由一维ndarray、列表、字典、元组或Series构成的字典
• Series类型
• 其他的DataFrame类型
(1)从二维ndarray对象创建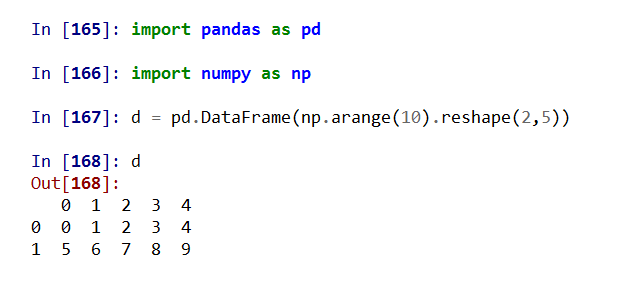
(2)从一维ndarray对象字典创建
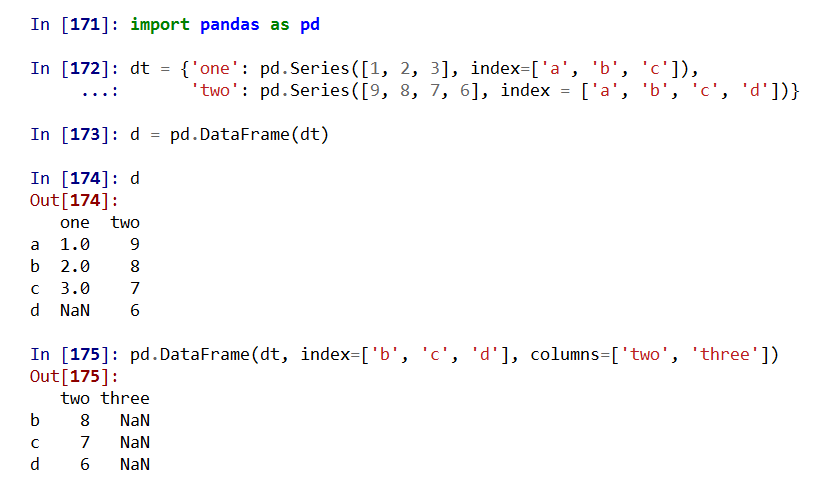
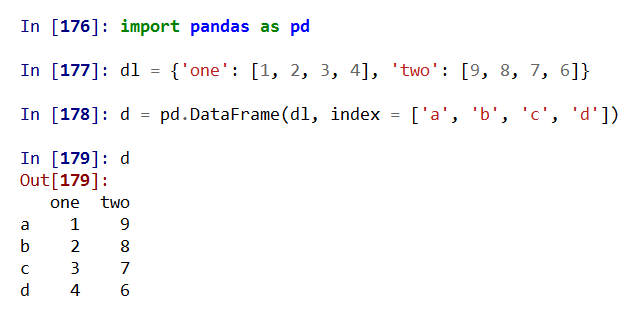
(3)从列表类型的字典创建
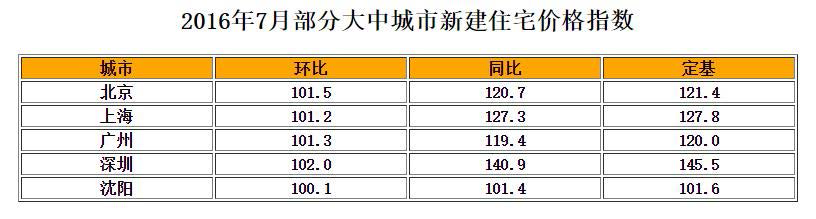
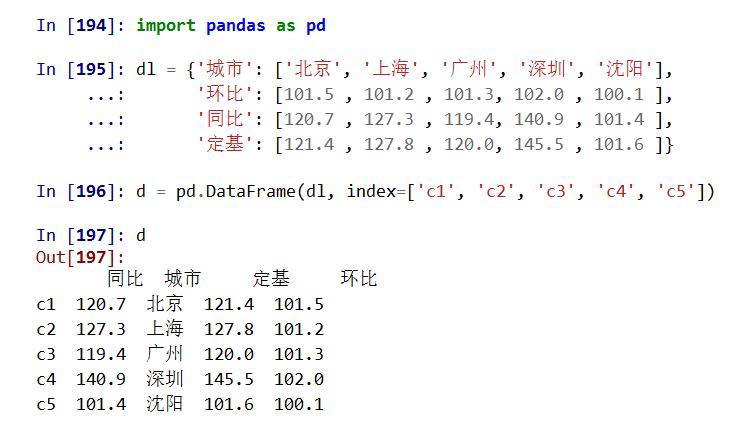


DataFrame是二维带“标签”数组,DataFrame基本操作类似Series,依据行列索引
4. Pandas库的数据类型操作
如何改变Series和DataFrame对象?
增加或重排:重新索引
删除:drop
.reindex()能够改变或重排Series和DataFrame索引
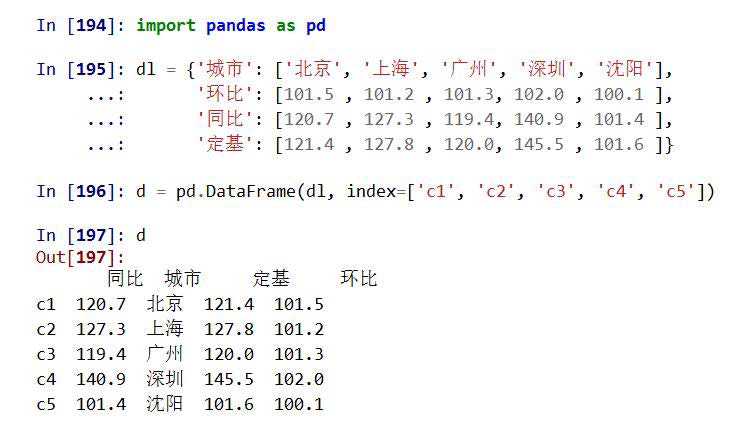

.reindex(index=None, columns=None, …)的参数
参数 说明
index, columns 新的行列自定义索引
fill_value 重新索引中,用于填充缺失位置的值
method 填充方法, ffill当前值向前填充,bfill向后填充
limit 最大填充量
copy 默认True,生成新的对象,False时,新旧相等不复制



Series和DataFrame的索引是Index类型,Index对象是不可修改类型
索引类型的常用方法
方法 说明
.append(idx) 连接另一个Index对象,产生新的Index对象
.diff(idx) 计算差集,产生新的Index对象
.intersection(idx) 计算交集
.union(idx) 计算并集
.delete(loc) 删除loc位置处的元素
.insert(loc,e) 在loc位置增加一个元素e
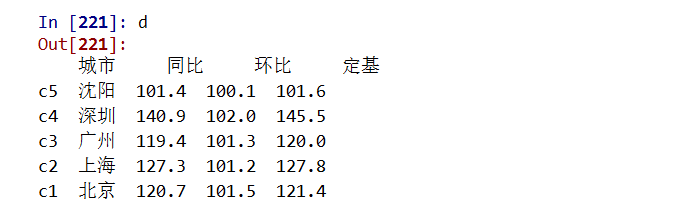

.drop()能够删除Series和DataFrame指定行或列索引


5. Pandas库的数据类型运算
(1)算术运算法则:
算术运算根据行列索引,补齐后运算,运算默认产生浮点数
补齐时缺项填充NaN (空值)
二维和一维、一维和零维间为广播运算
采用+ ‐ * /符号进行的二元运算产生新的对象


方法形式的运算
方法 说明
.add(d, **argws) 类型间加法运算,可选参数
.sub(d, **argws) 类型间减法运算,可选参数
.mul(d, **argws) 类型间乘法运算,可选参数
.div(d, **argws) 类型间除法运算,可选参数


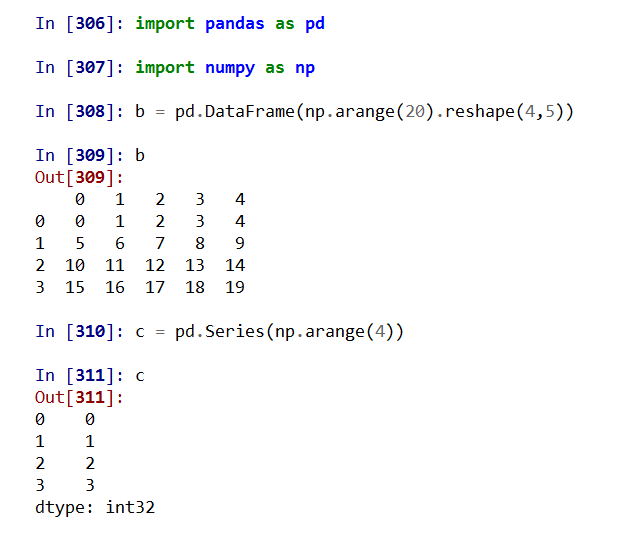

使用运算方法可以令一维Series参与轴0运算
(2)比较运算法则
比较运算只能比较相同索引的元素,不进行补齐
二维和一维、一维和零维间为广播运算
采用> < >= <= == !=等符号进行的二元运算产生布尔对象
同维度运算,尺寸一致:

不同维度,广播运算,默认在1轴

二、Pandas数据特征分析
1. 数据的排序
一组数据表达一个或多个含义
摘要(数据形成有损特征的过程)
基本统计(含排序)
分布/累计统计
数据特征
相关性、周期性等
数据挖掘(形成知识)
.sort_index()方法在指定轴上根据索引进行排序,默认升序
.sort_index(axis=0, ascending=True)


.sort_index(axis=0, ascending=True)


.sort_values()方法在指定轴上根据数值进行排序,默认升序
Series.sort_values(axis=0, ascending=True)
DataFrame.sort_values(by, axis=0, ascending=True)
by : axis轴上的某个索引或索引列表


NaN统一放到排序末尾


2. 数据的基本统计分析
基本的统计分析函数:适用于Series和DataFrame类型
方法 说明
.sum() 计算数据的总和,按0轴计算,下同
.count() 非NaN值的数量
.mean() .median() 计算数据的算术平均值、算术中位数
.var() .std() 计算数据的方差、标准差
.min() .max() 计算数据的最小值、最大值
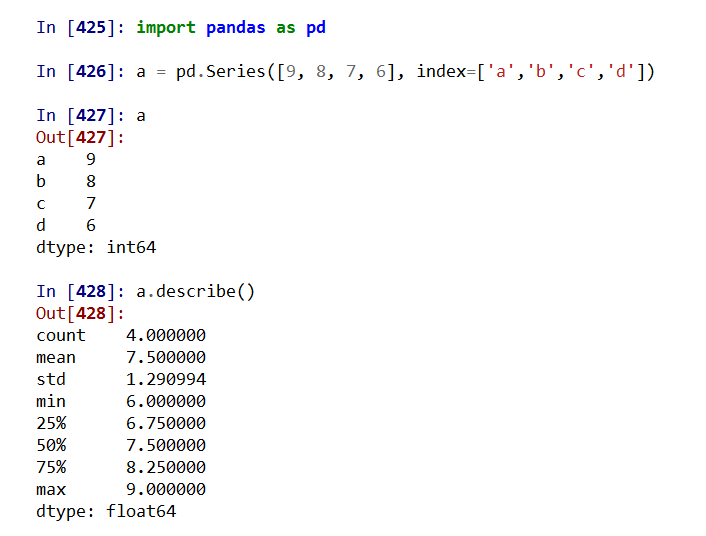
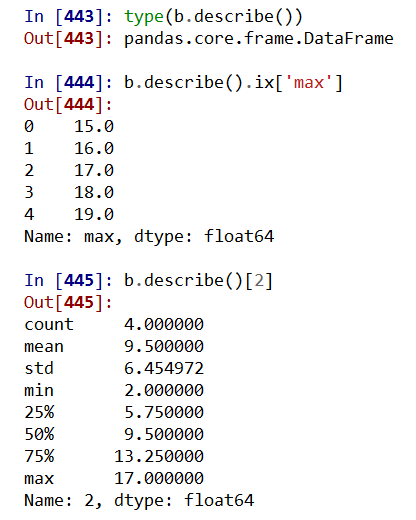
.describe() 针对0轴(各列)的统计汇总
适用于Series类型
方法 说明
.argmin() .argmax() 计算数据最大值、最小值所在位置的索引位置(自动索引)
.idxmin() .idxmax() 计算数据最大值、最小值所在位置的索引(自定义索引)


3. 累计统计分析函数
适用于Series和DataFrame类型,累计计算
方法 说明
.cumsum() 依次给出前1、2、…、n个数的和
.cumprod() 依次给出前1、2、…、n个数的积
.cummax() 依次给出前1、2、…、n个数的最大值
.cummin() 依次给出前1、2、…、n个数的最小值




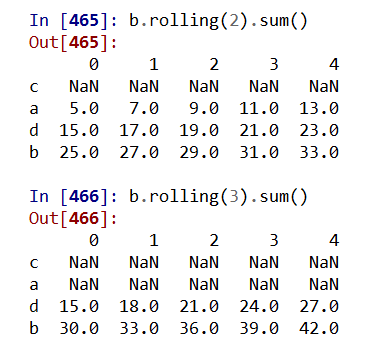
适用于Series和DataFrame类型,滚动计算(窗口计算)
方法 说明
.rolling(w).sum() 依次计算相邻w个元素的和
.rolling(w).mean() 依次计算相邻w个元素的算术平均值
.rolling(w).var() 依次计算相邻w个元素的方差
.rolling(w).std() 依次计算相邻w个元素的标准差
.rolling(w).min() .max() 依次计算相邻w个元素的最小值和最大值
4. 数据的相关分析
两个事物,表示为X和Y,如何判断它们之间的存在相关性?
相关性
• X增大,Y增大,两个变量正相关
• X增大,Y减小,两个变量负相关
• X增大,Y无视,两个变量不相关
(1)协相关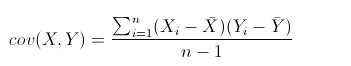
• 协方差>0, X和Y正相关
• 协方差<0, X和Y负相关
• 协方差=0, X和Y独立无关
(2)Pearson相关系数
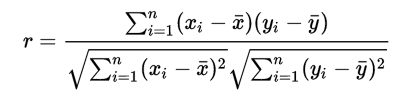
r取值范围[‐1,1]
• 0.8‐1.0 极强相关
• 0.6‐0.8 强相关
• 0.4‐0.6 中等程度相关
• 0.2‐0.4 弱相关
• 0.0‐0.2 极弱相关或无相关
适用于Series和DataFrame类型
方法说明
.cov() 计算协方差矩阵
.corr() 计算相关系数矩阵, Pearson、Spearman、Kendall等系数

python数据分析及展示(三)的更多相关文章
- Python数据分析--Pandas知识点(三)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘. Python数据分析--Pandas知识点(一) Python数据分析--Pandas知识点(二) 下面将是在知识点一, ...
- 【学习笔记】PYTHON数据分析与展示(北理工 嵩天)
0 数据分析之前奏 课程主要内容:常用IDE:本课程主要使用:Anaconda Anaconda:一个集合,包括conda.某版本Python.一批第三方库等 -支持近800个第三方库 -适合科学计算 ...
- Python数据分析与展示[第三周](pandas简介与数据创建)
第三周的课程pandas 分析数据 http://pandas.pydata.org import pandas as pd 常与numpy matplotlib 一块定义 d=pd.Series(r ...
- Python数据分析与展示[第三周](pandas数据类型操作)
数据类型操作 如何改变Series/ DataFrame 对象 增加或重排:重新索引 删除:drop 重新索引 .reindex() reindex() 能够改变或重排Series和DataFrame ...
- Python数据分析与展示[第三周](pandas数据特征分析单元8)
数据理解 基本统计 分布/累计统计 数据特征 数据挖掘 数据排序 操作索引的排序 .sort_index() 在指定轴上排序,默认升序 参数 axis=0 column ascending=True ...
- python数据分析及展示(一)
一.IDE选择 Anaconda软件:开源免费,https://www.anaconda.com下载,根据系统进行安装.由于下载速度慢,可以去清华大学开源软件镜像站下载. Spyder软件设置:Too ...
- Python数据分析与展示(1)-数据分析之表示(1)-NumPy库入门
Numpy库入门 从一个数据到一组数据 维度:一组数据的组织形式 一维数据:由对等关系的有序或无序数据构成,采用线性方式组织. 可用类型:对应列表.数组和集合 不同点: 列表:数据类型可以不同 数组: ...
- Python数据分析与展示(1)-数据分析之表示(2)-NumPy数据存取与函数
NumPy数据存取与函数 数据的CSV文件存取 CSV文件 CSV(Comma-Separated Value,逗号分隔值) CSV是一种常见的文件格式,用来存储批量数据. 将数据写入CSV文件 np ...
- Python数据分析与展示[第二周]
matplotlib 有各种可视化的类构成 一般调用 matplotlib.pypolt 这个命令字库 相当于快捷方式 plt.plot(a) 只有一个一维列表 x轴充当列表索引 plt.ylabel ...
随机推荐
- Codeforces Round #443 (Div. 1) D. Magic Breeding 位运算
D. Magic Breeding link http://codeforces.com/contest/878/problem/D description Nikita and Sasha play ...
- vue要点记录(待更新)
Vue实例 每个 Vue 实例都会代理其 data 对象里所有的属性:vm.a===data.a //true 注意只有这些被代理的属性是响应的. 如果在实例创建之后添加新的属性到实例上,它不会触发视 ...
- python之进程和线程3
1 multiprocessing模块 (1.)直接导入 from multiprocessing import Process import os import time def info(name ...
- elastic-job详解(二):作业的调度
JobScheduler是elastic-job作业调度的关键类,也是起始类,在包com.dangdang.ddframe.job.lite.api下.调度任务的执行需要包含两大步骤:任务的配置和任务 ...
- JDK提供的几种线程池比较
JDK提供的几种线程池 newFixedThreadPool创建一个指定工作线程数量的线程池.每当提交一个任务就创建一个工作线程,如果工作线程数量达到线程池初始的最大数,则将提交的任务存入到池队列中. ...
- Nancy的基本用法
在前面的文章轻量级的Web框架——Nancy中简单的介绍了一下Nancy的特点,今天这里就介绍下它的基本用法,由于2.0的版本还是预览状态,我这里用的是1.4版本,和最小的版本API还是有些差异的. ...
- datasnap isapi程序iis设置
datasnap isapi程序iis设置 添加ISAPI和CGI限制: 处理程序映射---添加模块映射: IIS应用程序池要如下设置: 停止ISAPI部署服务
- 【springboot】【redis】springboot+redis实现发布订阅功能,实现redis的消息队列的功能
springboot+redis实现发布订阅功能,实现redis的消息队列的功能 参考:https://www.cnblogs.com/cx987514451/p/9529611.html 思考一个问 ...
- 罗技Setpoint控制酷狗等第三方播放器
手里有个淘过来的二手戴尔蓝牙键盘,虽然是戴尔的,但是确实罗技代工的,因此可以使用罗技的Setpoint,用这个软件后可以集中管理罗技的键盘鼠标进行一些个性化设置,如下图所示.不过郁闷的是如果不装Set ...
- spring boot使用TestRestTemplate集成测试 RESTful 接口
这篇文章没什么技术含量,只是单纯的记录一下如何用TestRestTemplate访问受security保护的api,供以后查阅. @Slf4j @RunWith(SpringRunner.class) ...