Mysql优化-大数据量下的分页策略
一。前言
通常,我们分页时怎么实现呢?
|
1
|
SELECT * FROM table ORDER BY id LIMIT 1000, 10; |
但是,数据量猛增以后呢?
|
1
|
SELECT * FROM table ORDER BY id LIMIT 1000000, 10; |
如上第二条查询时很慢的,直接拖死。
最关键的原因mysql查询机制的问题:
不是先跳过,后查询;
而是先查询,后跳过。(解释如下)
什么意思?比如limit 100000,10,在找到需要的那10条时,先会轮询经过前10W条数据,先回行查询出前100000条的字段数据,然后发现没用舍弃掉,直到最后找到需要的10条。
二。分析
limit offset,N, 当offset非常大时,效率极低,
原因是mysql并不是跳过offset行,然后单取N行,
而是取offset+N行,返回放弃前offset行,返回N行【同前边说的先查询,后跳过】.
效率较低,当offset越大时,效率越低
三。3条优化建议
1:从业务上去解决
办法:不允许翻过100页
以百度为例,一般翻页到70页左右.
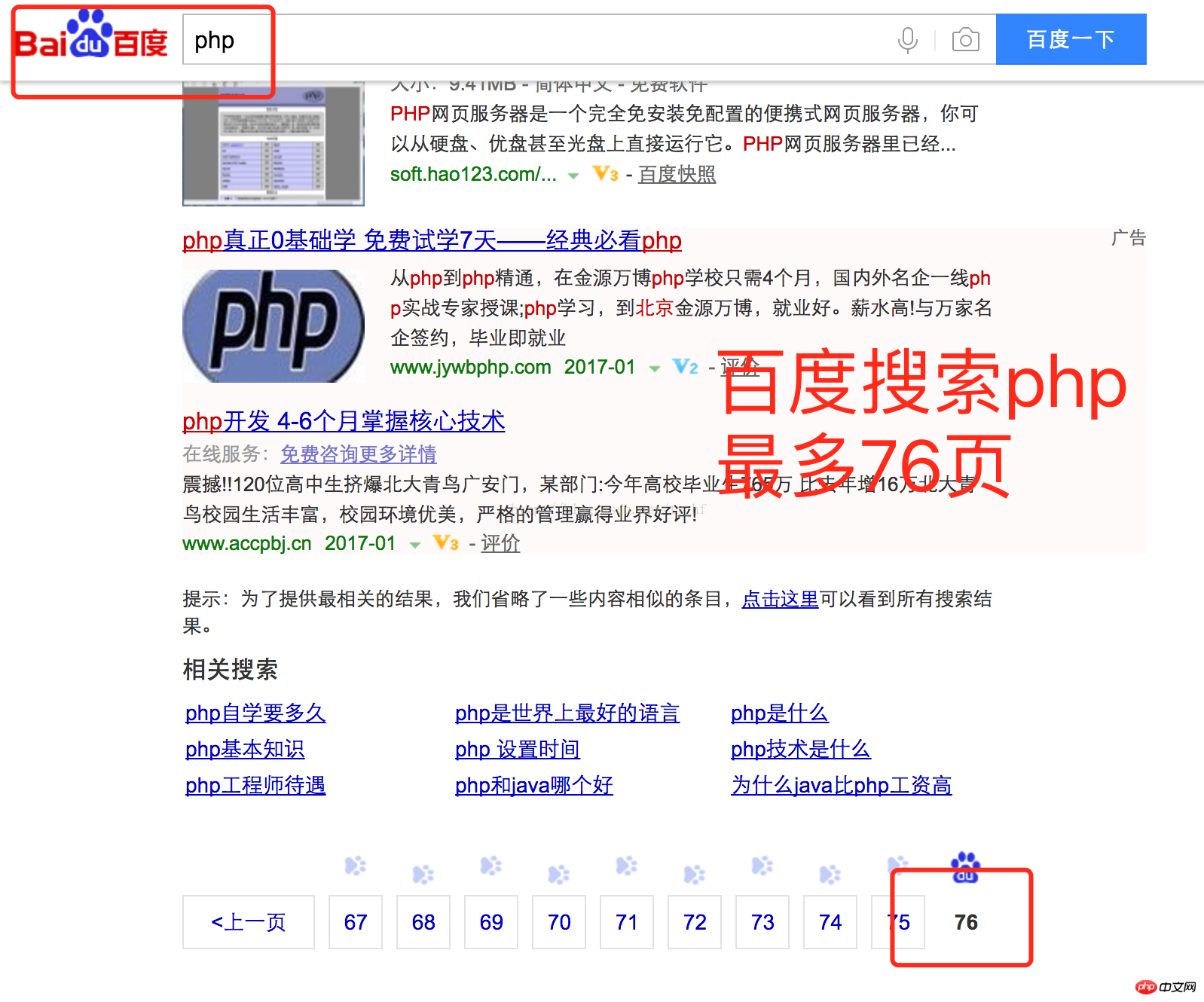
2:不用offset,用条件查询.
例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
mysql> select id, from lx_com limit 5000000,10;+---------+--------------------------------------------+| id | name |+---------+--------------------------------------------+| 5554609 |温泉县人民政府供暖中心 |..................| 5554618 |温泉县邮政鸿盛公司 |+---------+--------------------------------------------+10 rows in set (5.33 sec) mysql> select id,name from lx_com where id>5000000 limit 10;+---------+--------------------------------------------------------+| id | name |+---------+--------------------------------------------------------+| 5000001 |南宁市嘉氏百货有限责任公司 |.................| 5000002 |南宁市友达电线电缆有限公司 |+---------+--------------------------------------------------------+10 rows in set (0.00 sec) |
现象:从5.3秒到不到100毫秒,查询速度大大加快;但是数据结果却不一样
优点:利用where条件来避免掉先查询后跳过的问题,而是条件缩小范围,从而直接跳过。
存在问题: 有时有会发现用此方法与limitM,N,两次的结果不一致[如上边实例所展示]
原因:数据被物理删除过,有空洞.
解决:数据不进行物理删除(可以逻辑删除).
最终在页面上显示数据时,逻辑删除的条目不显示即可.
(一般来说,大网站的数据都是不物理删除的,只做逻辑删除 ,比如 is_delete=1)
3:延迟索引.
非要物理删除,还要用offset精确查询,还不限制用户分页,怎么办?
优化思路:
利用索引覆盖,快速查询出满足条件的主键id;然后凭借主键id作为where条件,达到快速查询。
(速度快在哪里?利用索引覆盖不需要回行就可以快速查询出满足条件的id,时间节约在这里了)
我们现在必须要查,则只查索引,不查数据,得到id.再用id去查具体条目. 这种技巧就是延迟索引.
慢原因:
查询100W条数据的id,name,m每次查询回行抛弃,跨过100W后取到真正要的数据。【就是我们刚刚说的,先查询,后跳过】
优化后快原理:
a.利用索引覆盖先查询出主键id,在索引上就拿到信息了,避免回行
b.找到主键后,根据已知的目标主键在查询,避免跨大数据行去寻找,而是直接定位哪几条数据直接查询。
本方法即延迟索引查询。
|
1
2
3
4
5
6
7
8
9
|
mysql> select id,name from lx_com inner join (select id from lx_com limit 5000000,10) as tmp using(id);+---------+-----------------------------------------------+| id | name |+---------+-----------------------------------------------+| 5050425 | 陇县河北乡大谈湾小学 |........| 5050434 | 陇县堎底下镇水管站 |+---------+-----------------------------------------------+10 rows in set (1.35 sec) |
四。总结:
从方案上来说,肯定是方法一优先,从业务上去满足是否要翻那么多页。
如果业务要求,则用id>n limit m的方式来代替limit n,m,但缺点是不能有物理删除
如果非有物理删除有空缺不能用方法二,则用延迟索引法,本质是利用索引覆盖先快速取出索引值,根据锁定的目标的索引值。一次性去回行取值,效果很明显。
Mysql优化-大数据量下的分页策略的更多相关文章
- mysql大数据量下的分页
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- 大数据量下,分页的解决办法,bubuko.com分享,快乐人生
大数据量,比如10万以上的数据,数据库在5G以上,单表5G以上等.大数据分页时需要考虑的问题更多. 比如信息表,单表数据100W以上. 分页如果在1秒以上,在页面上的体验将是很糟糕的. 优化思路: 1 ...
- mysql处理大数据量的查询速度究竟有多快和能优化到什么程度
mysql处理大数据量的查询速度究竟有多快和能优化到什么程度 深圳-ftx(1433725026) 18:10:49 mysql有没有排名函数啊 横瓜(601069289) 18:13:06 无 ...
- c#中@标志的作用 C#通过序列化实现深表复制 细说并发编程-TPL 大数据量下DataTable To List效率对比 【转载】C#工具类:实现文件操作File的工具类 异步多线程 Async .net 多线程 Thread ThreadPool Task .Net 反射学习
c#中@标志的作用 参考微软官方文档-特殊字符@,地址 https://docs.microsoft.com/zh-cn/dotnet/csharp/language-reference/toke ...
- mysql的大数据量的查询
mysql的大数据量查询分页应该用where 条件进行分页,limit 100000,100,mysql先查询100100数据量,查询完以后,将 这些100000数据量屏蔽去掉,用100的量,但是如果 ...
- 大数据量下的SQL Server数据库自身优化
原文: http://www.d1net.com/bigdata/news/284983.html 1.1:增加次数据文件 从SQL SERVER 2005开始,数据库不默认生成NDF数据文件,一般情 ...
- SQL优化-大数据量分页优化
百万数据量SQL,在进行分页查询时会出现性能问题,例如我们使用PageHelper时,由于分页查询时,PageHelper会拦截查询的语句会进行两个步骤 1.添加 select count(*)fro ...
- mysql百万级别重排主键id(网上的删除重建id在大数据量下会出错)
网上教程: 先删除旧的主键 再新建主键 :数据量少时没问题,不会出现主键自增空缺间隔的情况(如:1,2,3,5):但是大数据量时会出现如上所述问题(可能是内部mysql多进程或多线程同时操作引起问题) ...
- tomcat优化---大数据量提交tomcat时,tomcat无法接收导致页面无反应
关于tomcat的一个优化问题: 有时候保存大数据量的数据时.tomcat不优化的话,页面会没反应.tomcat后台并不报错,仅仅是提示以下内容: 警告: More than the maximum ...
随机推荐
- Android应用程序结构
综述:Android应用程序包含哪些部分? assets 可以出发一些随程序打包的文件,应用程序运行时可以动态读取到这些文件的内容. 如果使用到webview加载本地网页的功能,所有网页相关的文件都存 ...
- js中使用将json数组 转换为json将一个包含对象的数组用以创建一个包含新重新格式化对象的新数组
1.使用reduce: let arr = [{ "code": "badge", "priceList": [{ "amount ...
- 2017.08.15【NOIP提高组】模拟赛B组
Summary 今天比赛很差很差,掉到谷底.第一题快排打错了,漏了递归,变成一个while循环.最后一题k忘记减一,答案一直是无穷大,所以没交.第三题没时间调DP就打了个递归,第二题状态想歪了.四道题 ...
- springboot的常见问题错误
一: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 2 ...
- NHibernate查询优化的相关资料
一.http://www.cnblogs.com/dddd218/archive/2009/09/01/1557640.html 1.立即加载(lazy=false)并不能在所有情况下都会减少SQL语 ...
- mvc中使用Pagination,对其进行再封装
对其进行再次封装: (function($) { $["fn"]["easyPaging"] = function(o) { if (!o.pageSelect ...
- 【组合数】微信群 @upcexam6016
时间限制: 1 Sec 内存限制: 128 MB 题目描述 众所周知,一个有着6个人的宿舍可以有7个微信群(^_^,别问我我也不知道为什么),然而事实上这个数字可以更大,因为每3个或者是更多的人都可以 ...
- Unity中InitializeOnLoad属性的妙用
InitializeOnLoad 属性应用的对象是 静态构造函数,它可以保证在编辑器启动的时候调用此函数.根据这个特性,可以在编辑器中设置定期的回调(帧更新),来实现类似watchFile的功能.这里 ...
- js实现图片旋转
1.以下代码适用ie9版本 js代码如下: function rotate(o,p){ var img = document.getElementById(o); if(!img || !p) ret ...
- [canvas]空战游戏1.18
空战游戏到今天可以玩了,玩法还是方向键(或AWSD)控制飞机位置,空格键开炮,吃五星升级,被敌机打中降级直到击落,与敌机相撞则GG. 点此下载程序1.16版,用CHrome打开index.html试玩 ...