Apache Spark 2.2中基于成本的优化器(CBO)(转载)
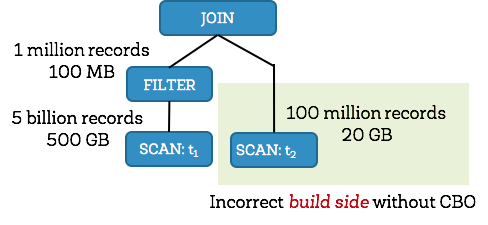
一个启发性的例子
统计信息收集框架
ANALYZE TABLE 命令
ANALYZE TABLE table_name COMPUTE STATISTICS
上面的 SQL 语句可以收集表级的统计信息,例如记录数、表大小(单位是byte)。这里需要注意的是ANALYZE, COMPUTE, and STATISTICS都是保留的关键字,他们已特定的列名为入参,在metastore中保存表级的统计信息。
ANALYZE TABLE table_name COMPUTE STATISTICS FOR COLUMNS column-name1, column-name2, ….
需要注意的是在ANALYZE 语句中没必要指定表的每个列-只要指定那些在过滤/join条件或group by等中涉及的列
统计信息类型

过滤选择
- 对于逻辑表达式AND,他的过滤选择是左条件的选择乘以右条件选择,例如fs(a AND b) = fs(a) * fs (b)。
- 对于逻辑表达式OR,他的过滤选择是左条件的选择加上右条件选择并减去左条件中逻辑表达式AND的选择,例如 fs (a OR b) = fs (a) + fs (b) - fs (a AND b) = fs (a) + fs (b) – (fs (a) * fs (b))
- 对于逻辑表达式NOT,他的过滤因子是1.0 减去原表达式的选择,例如 fs (NOT a) = 1.0 - fs (a)
- 等于操作符 (=) :我们检查条件中的字符串常量值是否落在列的当前最小值和最大值的区间内 。这步是必要的,因为如果先使用之前的条件可能会导致区间改变。如果常量值落在区间外,那么过滤选择就是 0.0。否则,就是去重后值的反转(注意:不包含额外的柱状图信息,我们仅仅估计列值的统一分布)。后面发布的版本将会均衡柱状图来优化估计的准确性。
- 小于操作符 (<) :检查条件中的字符串常量值落在哪个区间。如果比当前列值的最小值还小,那么过滤选择就是 0.0(如果大于最大值,选择即为1.0)。否则,我们基于可用的信息计算过滤因子。如果没有柱状图,就传播并把过滤选择设置为: (常量值– 最小值) / (最大值 – 最小值)。另外,如果有柱状图,在计算过滤选择时就会加上在当前列最小值和常量值之间的柱状图桶密度 。同时,注意在条件右边的常量值此时变成了该列的最大值。
Join基数
- 左外连接(Left-Outer Join): num(A LOJ B) = max(num(A IJ B),num(A)) 是指内连接输出基和左外连接端A的基之间较大的值。这是因为我们需要把外端的每条纪录计入,虽然他们没有出现在join输出纪录内。
- Right-Outer Join: num(A ROJ B) = max(num(A IJ B),num(B))
- Full-Outer Join: num(A FOJ B) = num(A LOJ B) + num(A ROJ B) - num(A IJ B)
最优计划选择
查询的性能测试和分析
配置及方法学
SELECT
i_item_id,
i_item_desc,
s_store_id,
s_store_name,
sum(ss_net_profit) AS store_sales_profit,
sum(sr_net_loss) AS store_returns_loss,
sum(cs_net_profit) AS catalog_sales_profit
FROM
store_sales, store_returns, catalog_sales, date_dim d1, date_dim d2, date_dim d3,
store, item
WHERE
d1.d_moy = 4
AND d1.d_year = 2001
AND d1.d_date_sk = ss_sold_date_sk
AND i_item_sk = ss_item_sk
AND s_store_sk = ss_store_sk
AND ss_customer_sk = sr_customer_sk
AND ss_item_sk = sr_item_sk
AND ss_ticket_number = sr_ticket_number
AND sr_returned_date_sk = d2.d_date_sk
AND d2.d_moy BETWEEN 4 AND 10
AND d2.d_year = 2001
AND sr_customer_sk = cs_bill_customer_sk
AND sr_item_sk = cs_item_sk
AND cs_sold_date_sk = d3.d_date_sk
AND d3.d_moy BETWEEN 4 AND 10
AND d3.d_year = 2001
GROUP BY
i_item_id, i_item_desc, s_store_id, s_store_name
ORDER BY
i_item_id, i_item_desc, s_store_id, s_store_name
LIMIT 100
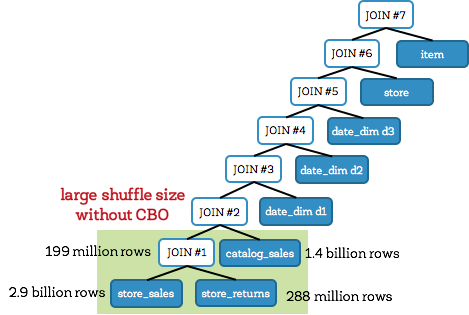
没使用CBO的Q25
使用了CBO的Q25

TPC-DS 查询性能


结论
延伸阅读
- 原理就是较小的关系更容易放到内存
- <=> 表示‘安全的空值相等’ ,如果两边的结果都是null就返回true,如果只有一边是null就返回false
- P. Griffiths Selinger, M. M. Astrahan, D. D. Chamberlin, R. A. Lorie, T. G. Price, “Access Path Selection in a Relational Database Management System”, Proceedings of ACM SIGMOD conference, 1979
- weight(权值)是调优参数,可以通过配置 spark.sql.cbo.joinReorder.card.weight (默认是0.7)
转载自 http://www.aboutyun.com/thread-22746-1-1.html
英文博客地址 https://databricks.com/blog/2017/08/31/cost-based-optimizer-in-apache-spark-2-2.html
Apache Spark 2.2中基于成本的优化器(CBO)(转载)的更多相关文章
- CBO 基于成本的优化器[基础]
转载:CBO基于成本的优化器 ----------------------------------2013/10/02 CBO基于成本的优化器:让oracle获取所有执行计划的相关信息,通过对这些信息 ...
- 如果Apache Spark集群中没有分布式系统,则会?
若当连接到Spark的master之后,若集群中没有分布式文件系统,Spark会在集群中每一台机器上加载数据,所以要确保Spark集群中每个节点上都有完整数据. 通常可以选择把数据放到HDFS.S3或 ...
- Introducing Apache Spark Datasets(中英双语)
文章标题 Introducing Apache Spark Datasets 作者介绍 Michael Armbrust, Wenchen Fan, Reynold Xin and Matei Zah ...
- Apache Spark on K8s的安全性和性能优化
前言 Apache Spark是目前最为流行的大数据计算框架,与Hadoop相比,它是替换MapReduce组件的不二选择,越来越多的企业正在从传统的MapReduce作业调度迁移到Spark上来,S ...
- MySQL 并行复制演进及 MySQL 8.0 中基于 WriteSet 的优化
MySQL 8.0 可以说是MySQL发展历史上里程碑式的一个版本,包括了多个重大更新,目前 Generally Available 版本已经已经发布,正式版本即将发布,在此将介绍8.0版本中引入的一 ...
- Apache Spark 2.2.0 中文文档
Apache Spark 2.2.0 中文文档 - 快速入门 | ApacheCN Geekhoo 关注 2017.09.20 13:55* 字数 2062 阅读 13评论 0喜欢 1 快速入门 使用 ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets(中英双语)
文章标题 A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets 且谈Apache Spark的API三剑客:RDD.Dat ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
随机推荐
- Universal-ImageLoader,Picasso,Fresco,Glide对比
Universal-ImageLoader:(估计由于HttpClient被Google放弃,作者就放弃维护这个框架)优点:1.支持下载进度监听2.可以在 View 滚动中暂停图片加载,通过 Paus ...
- SpringMVC的启动
Spring MVC中的Servlet Spring MVC中Servlet一共有三个层次,分别是HttpServletBean.FrameworkServlet和DispatcherServlet. ...
- 【Java入门提高篇】Day22 Java容器类详解(五)HashMap源码分析(上)
准备了很长时间,终于理清了思路,鼓起勇气,开始介绍本篇的主角——HashMap.说实话,这家伙能说的内容太多了,要是像前面ArrayList那样翻译一下源码,稍微说说重点,肯定会让很多人摸不着头脑,不 ...
- 操作过程-CentOS7下添加新硬盘扩充已经存在的逻辑卷分区的存储空间
Linux添加硬盘扩充已有分区存储空间方式 总体步骤 磁盘初始化分区 创建物理卷 扩展卷组 扩展逻辑卷 通知文件系统生效 磁盘初始化分区 [root@oracledb ~]# fdisk -l 磁 ...
- 【redis专题(6)】命令语法介绍之hash
可以把hash看做一个数组hset array key1 value2;,该数据类型特别适用于存储 增 hset key field value 作用: 把key中filed域的值设为value 注: ...
- openldap系列
openldap系列 阅读视图 系列介绍 openldap系列目录 1. 系列介绍 本系列文档大部分来自于郭大勇老师的<OpenLDAP实战指南>,少部分来自于互联网.所有文档均已经过本人 ...
- linux上文件内容去重的问题uniq/awk
1.uniq:只会对相邻的行进行判断是否重复,不能全文本进行搜索是否重复,所以往往跟sort结合使用. 例子1: [root@aaa01 ~]# cat a.txt 12 34 56 12 [root ...
- Java概述和项目演示
Java概述和项目演示 1. 软件开发学习方法 多敲 多思考 解决问题 技术文档阅读(中文,英文) 项目文档 多阅读源码 2. 计算机 简称电脑,执行一系列指令的电子设备 3. 硬件组成 输入设备:键 ...
- Elasticsearch一些常用操作和一些基础概念
1.查看集群健康状态 [root@ELK-chaofeng01 ~]#curl -XGET http://172.16.0.51:9200/_cat/health?v epoch timestamp ...
- elasticsearch版本控制及mapping映射属性介绍
学习elasticsearch不仅只会操作,基本的运行原理我们还是需要进行了解,以下内容我讲对elasticsearch中的基本知识原理进行梳理,希望对大家有所帮助! 一.ES版本控制 1.Elast ...