Spark SQL 之 Join 实现
Join作为SQL中一个重要语法特性,几乎所有稍微复杂一点的数据分析场景都离不开Join,如今Spark SQL(Dataset/DataFrame)已经成为Spark应用程序开发的主流,作为开发者,我们有必要了解Join在Spark中是如何组织运行的。
SparkSQL总体流程介绍
在阐述Join实现之前,我们首先简单介绍SparkSQL的总体流程,一般地,我们有两种方式使用SparkSQL,一种是直接写sql语句,这个需要有元数据库支持,例如Hive等,另一种是通过Dataset/DataFrame编写Spark应用程序。如下图所示,sql语句被语法解析(SQL AST)成查询计划,或者我们通过Dataset/DataFrame提供的APIs组织成查询计划,查询计划分为两大类:逻辑计划和物理计划,这个阶段通常叫做逻辑计划,经过语法分析(Analyzer)、一系列查询优化(Optimizer)后得到优化后的逻辑计划,最后被映射成物理计划,转换成RDD执行。
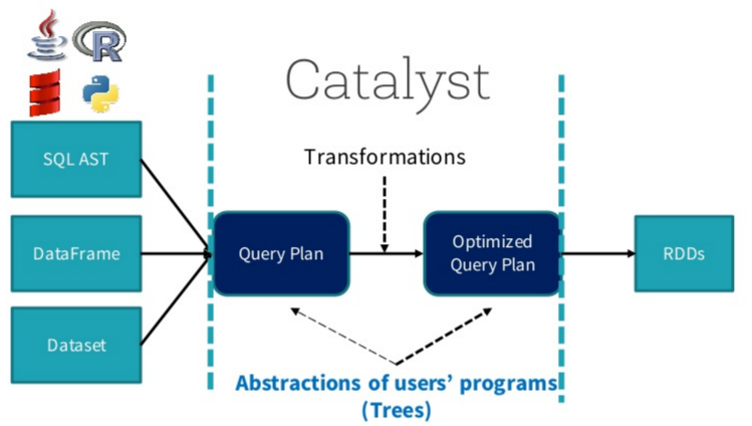
更多关于SparkSQL的解析与执行请参考文章【sql的解析与执行】。对于语法解析、语法分析以及查询优化,本文不做详细阐述,本文重点介绍Join的物理执行过程。
Join基本要素
如下图所示,Join大致包括三个要素:Join方式、Join条件以及过滤条件。其中过滤条件也可以通过AND语句放在Join条件中。
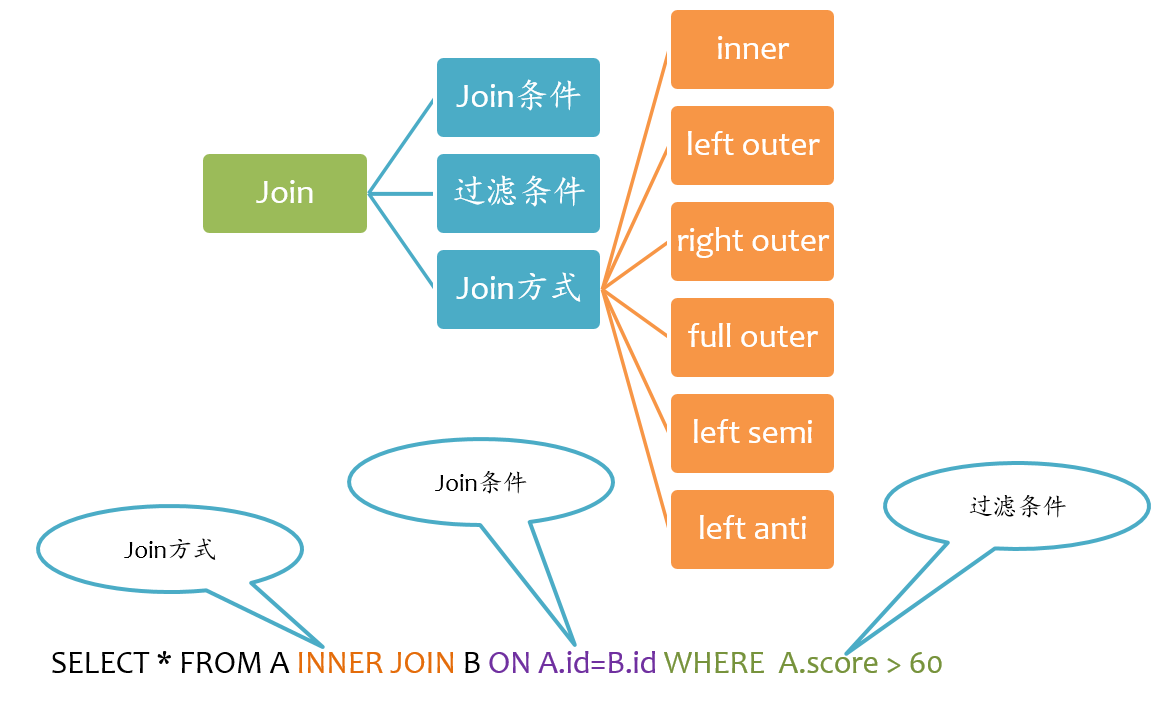
Spark支持所有类型的Join,包括:
- inner join
- left outer join
- right outer join
- full outer join
- left semi join
- left anti join
下面分别阐述这几种Join的实现。
Join基本实现流程
总体上来说,Join的基本实现流程如下图所示,Spark将参与Join的两张表抽象为流式遍历表(streamIter)和查找表(buildIter),通常streamIter为大表,buildIter为小表,我们不用担心哪个表为streamIter,哪个表为buildIter,这个spark会根据join语句自动帮我们完成。
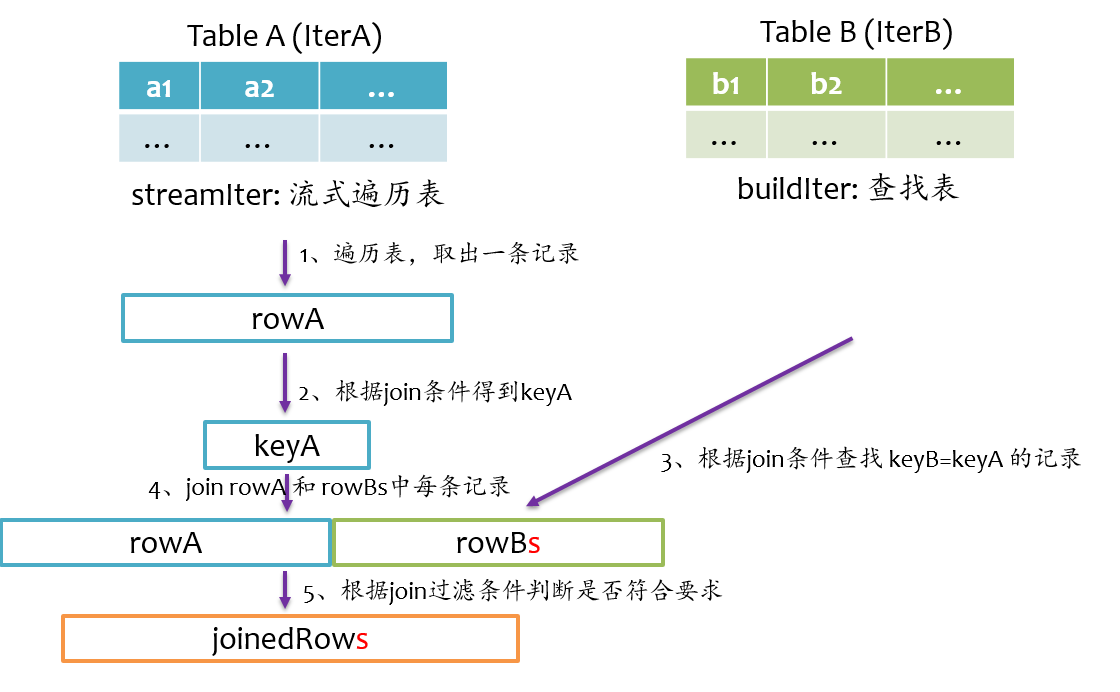
在实际计算时,spark会基于streamIter来遍历,每次取出streamIter中的一条记录rowA,根据Join条件计算keyA,然后根据该keyA去buildIter中查找所有满足Join条件(keyB==keyA)的记录rowBs,并将rowBs中每条记录分别与rowAjoin得到join后的记录,最后根据过滤条件得到最终join的记录。
从上述计算过程中不难发现,对于每条来自streamIter的记录,都要去buildIter中查找匹配的记录,所以buildIter一定要是查找性能较优的数据结构。spark提供了三种join实现:sort merge join、broadcast join以及hash join。
sort merge join实现
要让两条记录能join到一起,首先需要将具有相同key的记录在同一个分区,所以通常来说,需要做一次shuffle,map阶段根据join条件确定每条记录的key,基于该key做shuffle write,将可能join到一起的记录分到同一个分区中,这样在shuffle read阶段就可以将两个表中具有相同key的记录拉到同一个分区处理。前面我们也提到,对于buildIter一定要是查找性能较优的数据结构,通常我们能想到hash表,但是对于一张较大的表来说,不可能将所有记录全部放到hash表中,另外也可以对buildIter先排序,查找时按顺序查找,查找代价也是可以接受的,我们知道,spark shuffle阶段天然就支持排序,这个是非常好实现的,下面是sort merge join示意图。
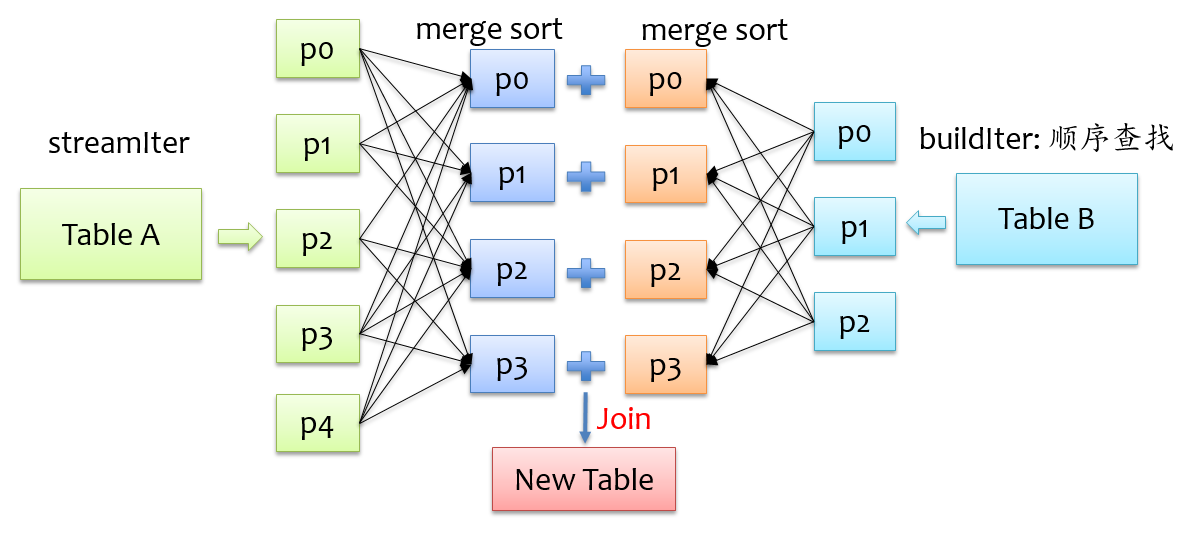
在shuffle read阶段,分别对streamIter和buildIter进行merge sort,在遍历streamIter时,对于每条记录,都采用顺序查找的方式从buildIter查找对应的记录,由于两个表都是排序的,每次处理完streamIter的一条记录后,对于streamIter的下一条记录,只需从buildIter中上一次查找结束的位置开始查找,所以说每次在buildIter中查找不必重头开始,整体上来说,查找性能还是较优的。
broadcast join实现
为了能具有相同key的记录分到同一个分区,我们通常是做shuffle,那么如果buildIter是一个非常小的表,那么其实就没有必要大动干戈做shuffle了,直接将buildIter广播到每个计算节点,然后将buildIter放到hash表中,如下图所示。
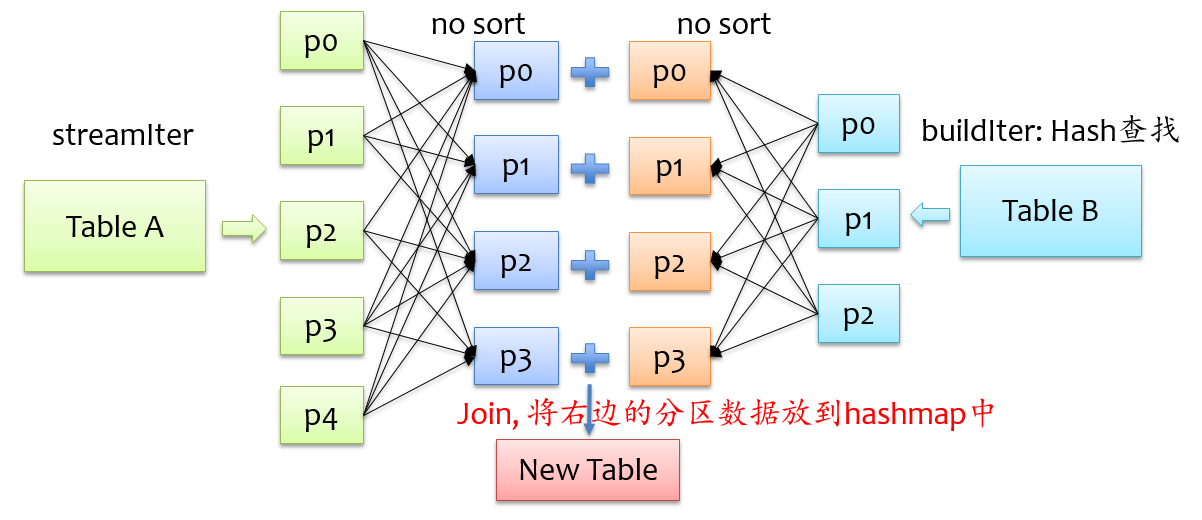
从上图可以看到,不用做shuffle,可以直接在一个map中完成,通常这种join也称之为map join。那么问题来了,什么时候会用broadcast join实现呢?这个不用我们担心,spark sql自动帮我们完成,当buildIter的估计大小不超过参数spark.sql.autoBroadcastJoinThreshold设定的值(默认10M),那么就会自动采用broadcast join,否则采用sort merge join。
hash join实现
除了上面两种join实现方式外,spark还提供了hash join实现方式,在shuffle read阶段不对记录排序,反正来自两格表的具有相同key的记录会在同一个分区,只是在分区内不排序,将来自buildIter的记录放到hash表中,以便查找,如下图所示。
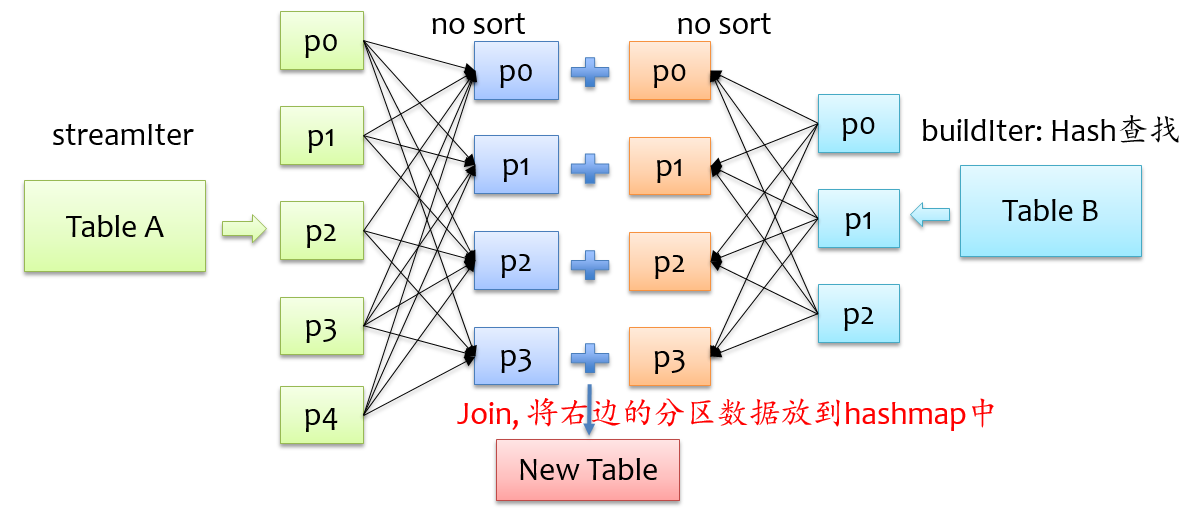
不难发现,要将来自buildIter的记录放到hash表中,那么每个分区来自buildIter的记录不能太大,否则就存不下,默认情况下hash join的实现是关闭状态,如果要使用hash join,必须满足以下四个条件:
- buildIter总体估计大小超过spark.sql.autoBroadcastJoinThreshold设定的值,即不满足broadcast join条件
- 开启尝试使用hash join的开关,spark.sql.join.preferSortMergeJoin=false
- 每个分区的平均大小不超过spark.sql.autoBroadcastJoinThreshold设定的值,即shuffle read阶段每个分区来自buildIter的记录要能放到内存中
- streamIter的大小是buildIter三倍以上
所以说,使用hash join的条件其实是很苛刻的,在大多数实际场景中,即使能使用hash join,但是使用sort merge join也不会比hash join差很多,所以尽量使用hash
下面我们分别阐述不同Join方式的实现流程。
inner join
inner join是一定要找到左右表中满足join条件的记录,我们在写sql语句或者使用DataFrmae时,可以不用关心哪个是左表,哪个是右表,在spark sql查询优化阶段,spark会自动将大表设为左表,即streamIter,将小表设为右表,即buildIter。这样对小表的查找相对更优。其基本实现流程如下图所示,在查找阶段,如果右表不存在满足join条件的记录,则跳过。
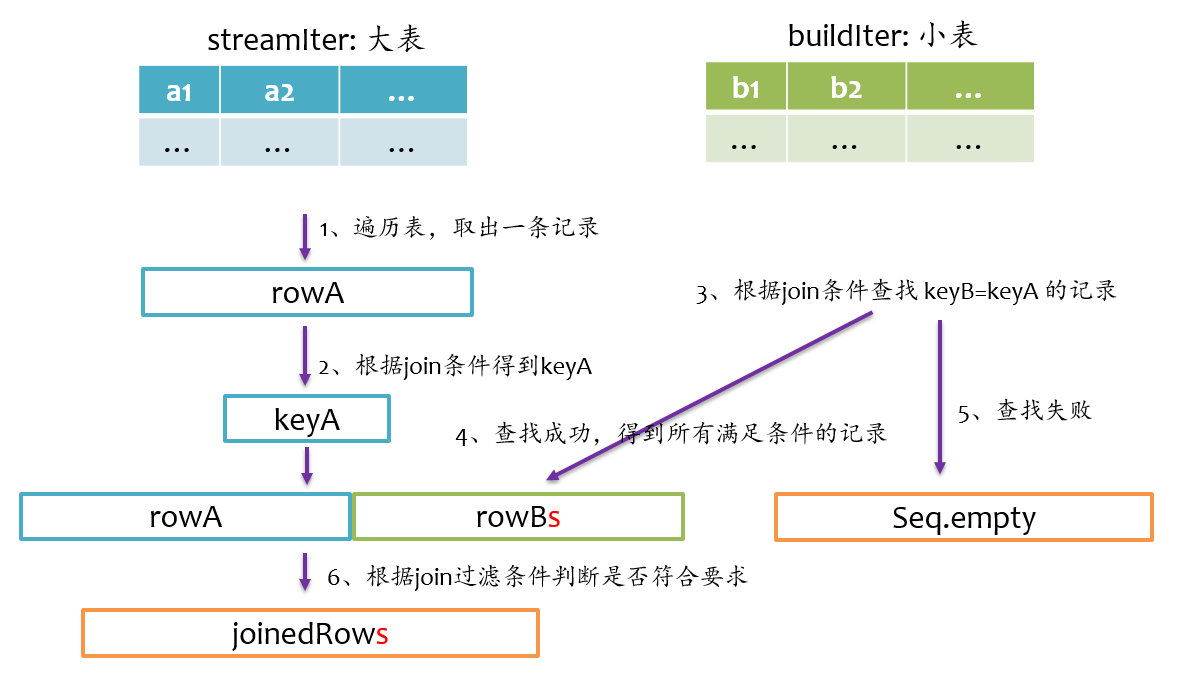
left outer join
left outer join是以左表为准,在右表中查找匹配的记录,如果查找失败,则返回一个所有字段都为null的记录。我们在写sql语句或者使用DataFrmae时,一般让大表在左边,小表在右边。其基本实现流程如下图所示。
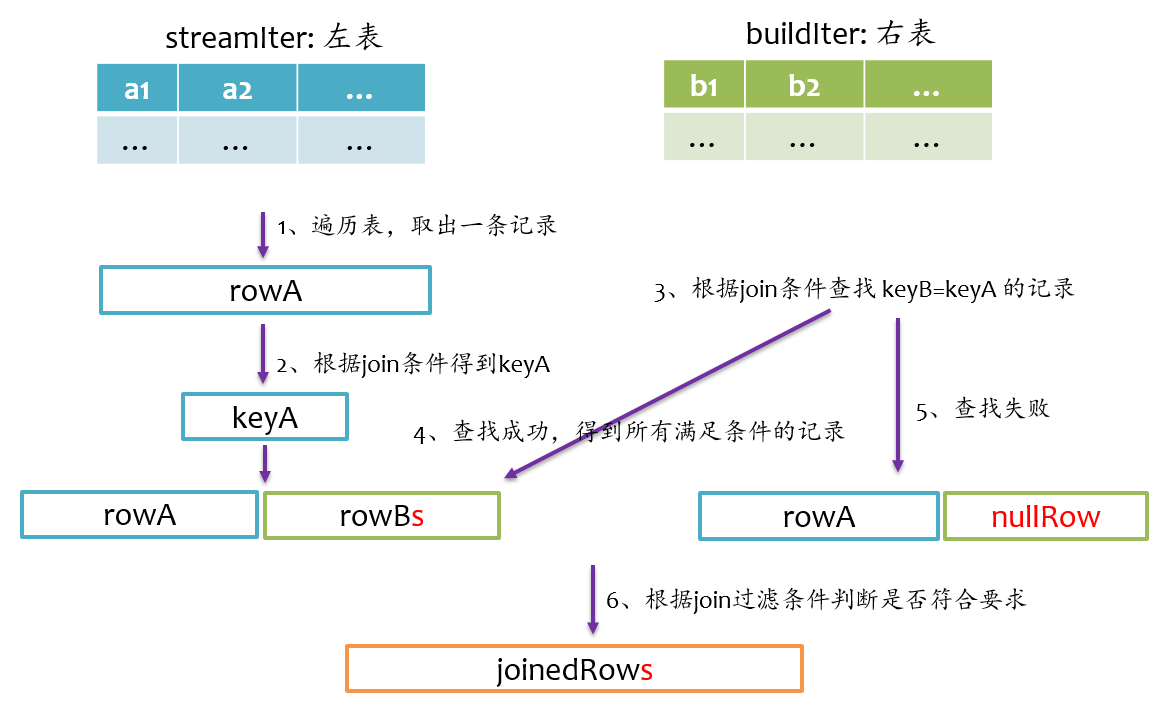
right outer join
right outer join是以右表为准,在左表中查找匹配的记录,如果查找失败,则返回一个所有字段都为null的记录。所以说,右表是streamIter,左表是buildIter,我们在写sql语句或者使用DataFrmae时,一般让大表在右边,小表在左边。其基本实现流程如下图所示。
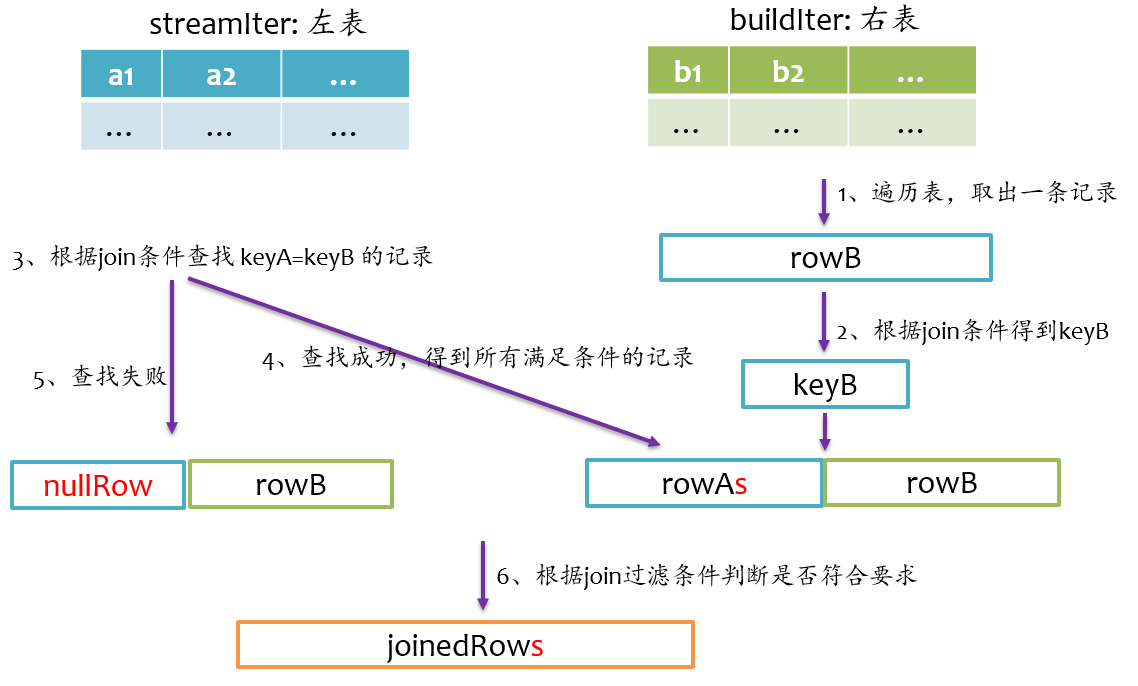
full outer join
full outer join相对来说要复杂一点,总体上来看既要做left outer join,又要做right outer join,但是又不能简单地先left outer join,再right outer join,最后union得到最终结果,因为这样最终结果中就存在两份inner join的结果了。因为既然完成left outer join又要完成right outer join,所以full outer join仅采用sort merge join实现,左边和右表既要作为streamIter,又要作为buildIter,其基本实现流程如下图所示。
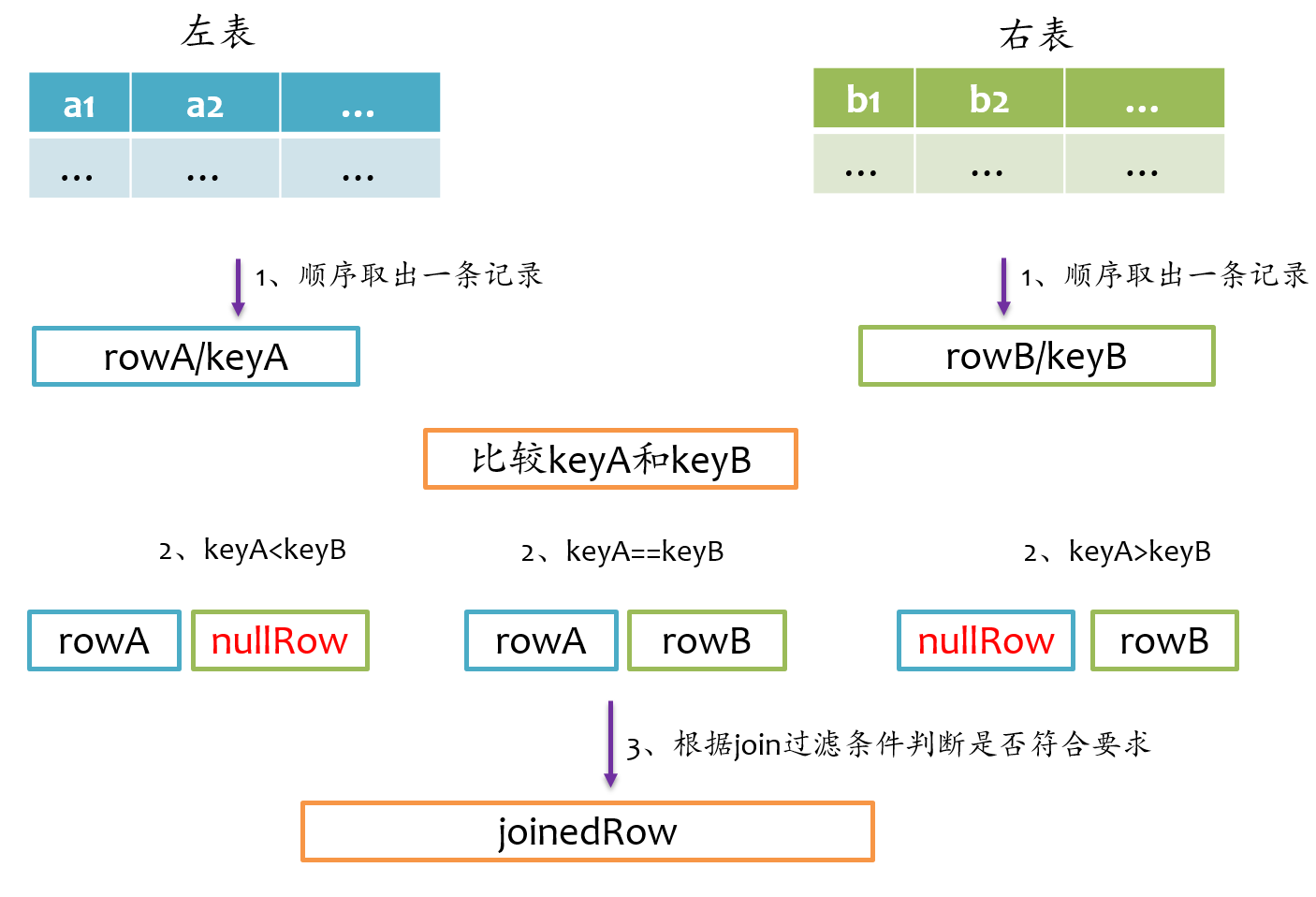
由于左表和右表已经排好序,首先分别顺序取出左表和右表中的一条记录,比较key,如果key相等,则joinrowA和rowB,并将rowA和rowB分别更新到左表和右表的下一条记录;如果keyA<keyB,则说明右表中没有与左表rowA对应的记录,那么joinrowA与nullRow,紧接着,rowA更新到左表的下一条记录;如果keyA>keyB,则说明左表中没有与右表rowB对应的记录,那么joinnullRow与rowB,紧接着,rowB更新到右表的下一条记录。如此循环遍历直到左表和右表的记录全部处理完。
left semi join
left semi join是以左表为准,在右表中查找匹配的记录,如果查找成功,则仅返回左边的记录,否则返回null,其基本实现流程如下图所示。
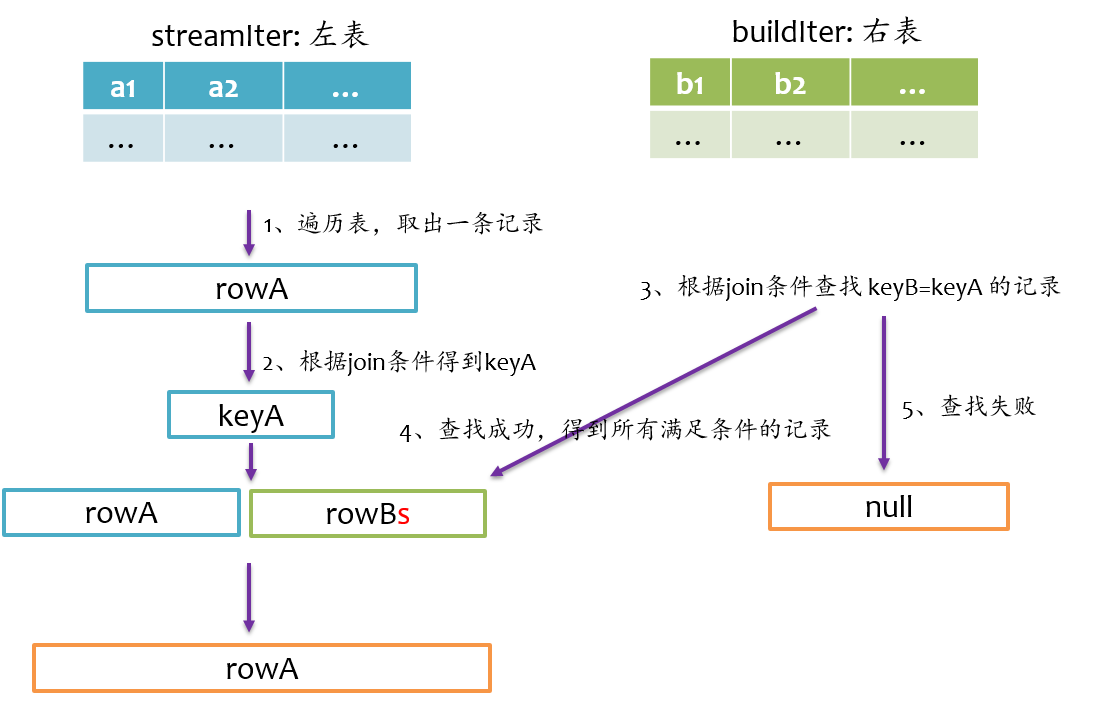
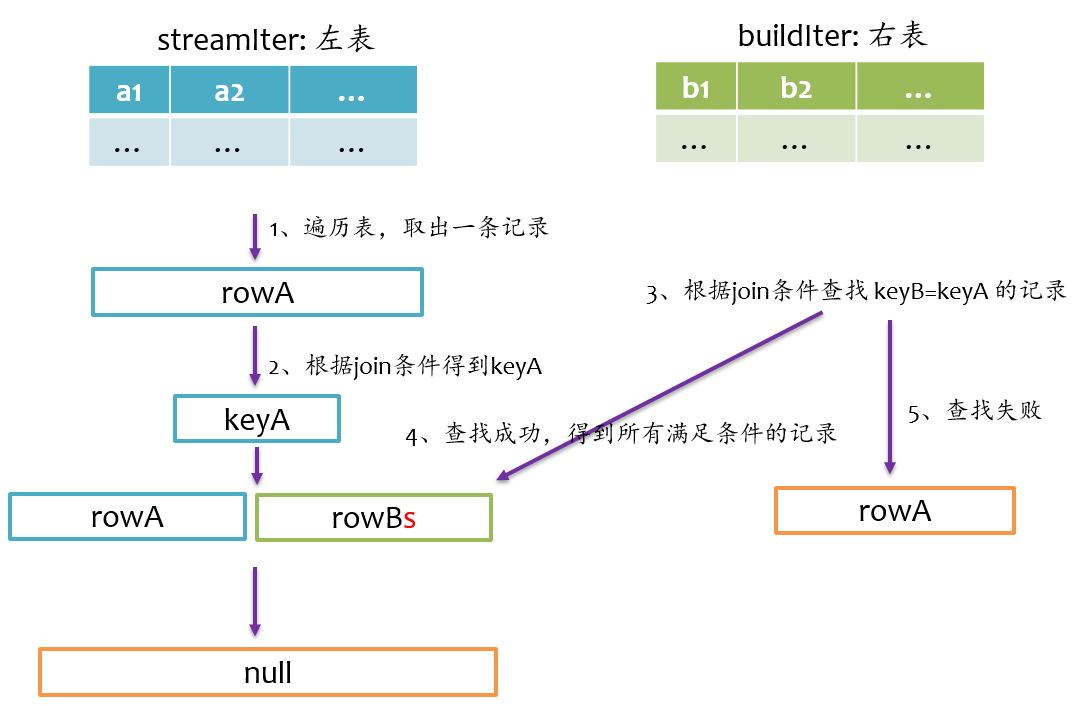
left anti join
left anti join与left semi join相反,是以左表为准,在右表中查找匹配的记录,如果查找成功,则返回null,否则仅返回左边的记录,其基本实现流程如下图所示。
总结
Join是数据库查询中一个非常重要的语法特性,在数据库领域可以说是“得join者的天下”,SparkSQL作为一种分布式数据仓库系统,给我们提供了全面的join支持,并在内部实现上无声无息地做了很多优化,了解join的实现将有助于我们更深刻的了解我们的应用程序的运行轨迹。
原文地址:Spark SQL 之 Join 实现
Spark SQL 之 Join 实现的更多相关文章
- Spark SQL Table Join(Python)
示例 Spark SQL注册“临时表”执行“Join”(Inner Join.Left Outer Join.Right Outer Join.Full Outer Join) 代码 fr ...
- Spark SQL概念学习系列之Spark SQL 优化策略(五)
查询优化是传统数据库中最为重要的一环,这项技术在传统数据库中已经很成熟.除了查询优化, Spark SQL 在存储上也进行了优化,从以下几点查看 Spark SQL 的一些优化策略. (1)内存列式存 ...
- Adaptive Execution如何让Spark SQL更高效更好用
1 背 景 Spark SQL / Catalyst 和 CBO 的优化,从查询本身与目标数据的特点的角度尽可能保证了最终生成的执行计划的高效性.但是 执行计划一旦生成,便不可更改,即使执行过程中发 ...
- spark sql/hive小文件问题
针对hive on mapreduce 1:我们可以通过一些配置项来使Hive在执行结束后对结果文件进行合并: 参数详细内容可参考官网:https://cwiki.apache.org/conflue ...
- Spark SQL中Not in Subquery为何低效以及如何规避
首先看个Not in Subquery的SQL: // test_partition1 和 test_partition2为Hive外部分区表 select * from test_partition ...
- Spark SQL中的几种join
1.小表对大表(broadcast join) 将小表的数据分发到每个节点上,供大表使用.executor存储小表的全部数据,一定程度上牺牲了空间,换取shuffle操作大量的耗时,这在SparkSQ ...
- Spark SQL join的三种实现方式
引言 join是SQL中的常用操作,良好的表结构能够将数据分散到不同的表中,使其符合某种规范(mysql三大范式),可以最大程度的减少数据冗余,更新容错等,而建立表和表之间关系的最佳方式就是join操 ...
- spark关于join后有重复列的问题(org.apache.spark.sql.AnalysisException: Reference '*' is ambiguous)
问题 datafrme提供了强大的JOIN操作,但是在操作的时候,经常发现会碰到重复列的问题.在你不注意的时候,去用相关列做其他操作的时候,就会出现问题! 假如这两个字段同时存在,那么就会报错,如下: ...
- Spark学习之路(十二)—— Spark SQL JOIN操作
一. 数据准备 本文主要介绍Spark SQL的多表连接,需要预先准备测试数据.分别创建员工和部门的Datafame,并注册为临时视图,代码如下: val spark = SparkSession.b ...
随机推荐
- go依赖包下载加速方法及github加速
go依赖包下载加速方法及github加速 对于https://github.com/kubernetes/kubernetes整个仓库大小为近900M,下载起来那个伤心: 方法一:使用码云 这是码云上 ...
- MyBatis(四):mybatis中使用in查询时的注意事项
准备工作 1)创建测试表jobitem CREATE TABLE "jobitem" ( "id" ) NOT NULL AUTO_INCREMENT COMM ...
- 众里寻他千百度?No!这项技术只需走两步就能“看穿”你!
电影<碟中谍5>中阿汤哥带上了面具,顺利通过指纹锁,三重物理等重重关卡,却最终仍旧功亏一篑,正是由于“ 火眼金睛 ”——步态识别 . (图片来源:碟中谍) 中国科学院自动化所的专家日前 ...
- Log4j/Log4j2自定义Appender来实现日志级别计数统计及监控
一.简述 本文主要讲如何基于Log4j2来实现自定义的Appender.一般用途是用于Log4j2自带的Appender不足以满足我们的需求,或者需要我们对日志进行拦截统计等操作时,需要我们自定义Ap ...
- html5使用canvas实现毫秒级画心电图
- CAShapeLayer(UIBezierPath)、CAGradientLayer绘制动态小车
看到一个大神写的代码,引用过来让大家看看! // 1.CAShapeLayer是一种特殊的层,可以在上面渲染图形. // 2.CAShapeLayer继承自CALayer,可使用CALayer的所 ...
- 2、金融之关于BOLL
一.BOLL(1)什么是BOLL线☆ BOLL指标又叫布林线指标(Bolinger Bands),是由约翰·布林格(John Bollinger)根据统计学中的标准差原理设计出来的一种非常简单实用的技 ...
- 使用Node.js的Express框架进行文件上传
我们先创建一个Express项目,要使用文件上传的功能还需要下载multer模块. npm install --save multer 下面我们在public文件夹下创建upload.html,内容如 ...
- [转]Mybatis foreach 批量操作
原文地址:https://blog.csdn.net/jason5186/article/details/40896043 foreach属性属性 描述item 循环体中的具体对象.支持属 ...
- python中的目录递归的创建和目录及其下的文件递归的删除
1,删除目录data下的train及其下的所有文件,相当于linux中的rm -rf import shutil shutil.rmtree('data/train') 2,递归的创建目录data/t ...