Intel P4 CPU
1. P4 CPU 结构
奔4处理器是Intel的经典之作,它是采用乱序执行内核的超标量处理器。P4采用的微架构称为 Net Burst,基本结构如下:
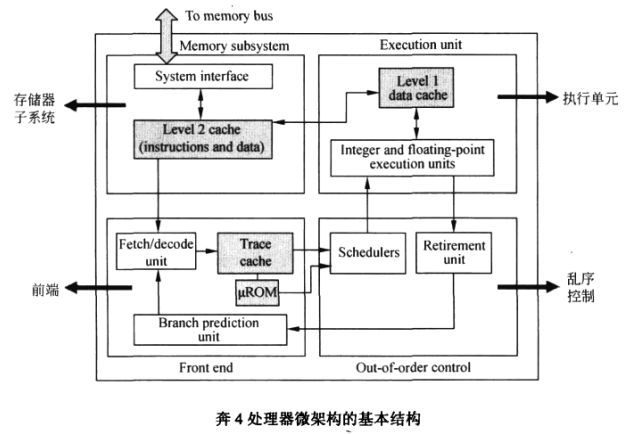
奔4处理器微架构被分成了4大部分:
(1)存储子系统( Memory subsystem)。
(2)前端( Front end)
(3)乱序控制( Out-of-order control)
(4)执行单元( Execution unit)。
存储子系统包含了片内的 Cache,Cache是处理器内部的存储单元,存储指令和数据。Cache也是微架构的重要组成部分,不过相对比较独立,留待下章细说。
指令在处理器内部的执行过程,可以分为前端和后端,前端准备指令,后端执行指令。前端包括取指、译码、分支预测等单元,后端包括执行单元和乱序控制。
执行单元的工作就是傻呼呼的运算,而指令的乱序调度交给了乱序控制部分。
2.译码:
在x86处理器中,译码单元的工作就是将x86指令翻译成类似RIsC的 micro operations(微操作),简称uop。
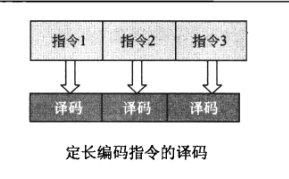
P4是超标量处理器,一次能处理多条指令,自然也要一次对多条指令进行译码。对于定长编码的指令,每条指令的bit数是固定的,多增加几套译码电路就能实现多条指令并行的译码,如下图所示:
不过,x86指令是变长编码的,指令长度从1~15 bytes不等,根本就不知道哪几个bytes是第一条指令的,哪几个 bytes是第二条指令的,也就无从解起。
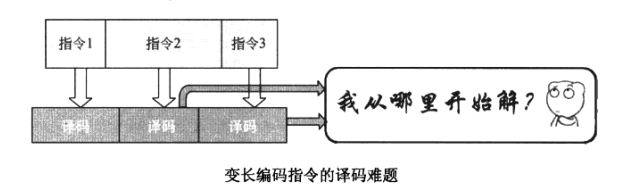
在AMD的处理器中,通常采用预译码( Predecode)的方式来解决这个难题,指令从内存读入到 Cache中时,就开始预解码,得出预译码标识,预译码标识包括指令的起始位置、需要译出的uop数目、操作码等信息。预译码标识连同指令一起存储在指令 Cache中,在正式译码时工作难度就减轻了。
Inte的处理器则采用多级译码流水线的方式来实现译码。第一级先检测出指令的起始和结束位置,第二级将指令解码为uop。
一条x86 CISC指令通常对应多条uop。当一条CISC指令生成的uop数目多于4条时,就将这些CISC指令对应的uop存储在 micro-ROM(uROM)中,解码时使用査表的方式从 micro-ROM中得到,这样就简化了复杂指令的译码过程。
3. Trace cache
在P4处理器中,解码后的uop被存储在 Trace Cache中。这个 Trace Cache和一般的Cache有点不一样,在一般的 Cache中,指令的存储顺序和内存中的指令顺序是一样的,而 Trace Cache中的指令顺序是指令的执行顺序,而不是指令的地址顺序。
下面这个程序中,包含有跳转指令:

指令在普通 Cache上存放的位置根据程序地址决定,指令这样存储:
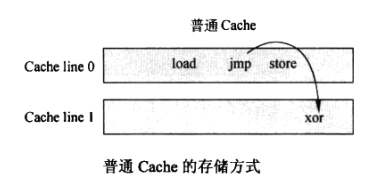
而在Trace Cache中,指令的存储方式如下:

在P4中,一个 Trace Cache line包含6条uop。
Trace Cache与传统 Cache有两点不同:
(1) Trace Cache存储的是译码之后的微操作,而不是x86指令。这样执行循环代码时,就省了指令的译码过程。
(2) Trace Cache存储的微操作是按照执行顺序存储的,而不是指令顺序。在超标量处理器中一次取多条指令时,减少了 Cache line的访问。
4.前端流水线
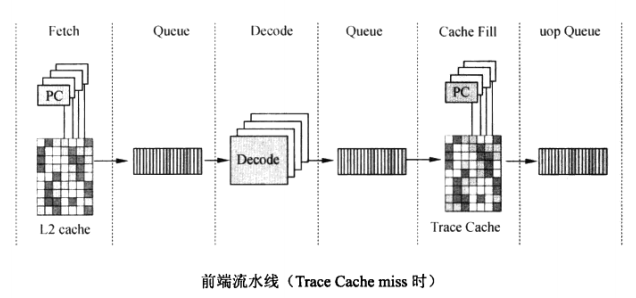
一开始,前端从L2 Cache中读指令,一次读64bit,取好的指令放在一个队列( Queue)中,也即Buffer中,前面我们有谈到Buer的作用,它隔离了前后两个步骤,并对速度进行了平滑。Decode单元从队列中取指令进行译码,译码后的指令也放在一个队列中,然后
再按照uop的执行顺序放在 Trace Cache中,然后再从 Trace Cache中取出uop放在 uop Queue中, uop queue为连接前端和后端的桥梁。
当uop已经在 Trace Cache中时,就不需要再从L2中取指令了,直接从Trace Cache中取uop即可。所需的指令在 Trace Cache中时,称为 Trace Cache hit(命中),所需的指令不在Trace Cache中时,称为 Trace Cache miss(未命中)。 Trace Cache hit时的前端流水线就简化为:
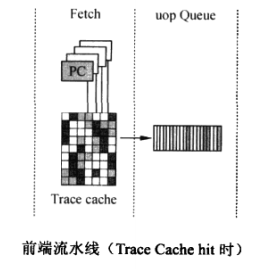
除了这些基本的模块之外,处理器在根据地址取指令时,需要进行虚地址、实地址转换,使用到TLB( Translation Lookaside Buffer);P4处理器中,有两个分支预测单元,一个用于预测指令的执行路径;另一个用于预测uop的执行路径。
5. 后端流水线
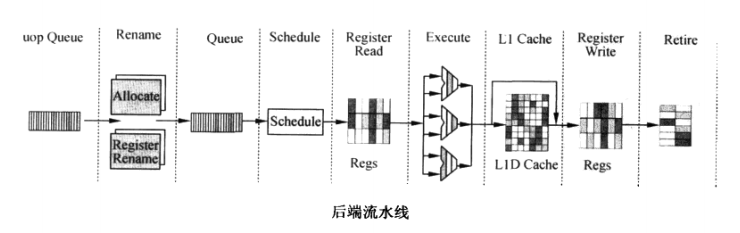
后端和前端的桥梁就是 uop Queue,当uop进入后端时,首先要进行资源的分配( Allocate),处理器内部拥有大量的 Buffer用于调度,每条进来的uoop要占一个位置,如它需要在ROB( Re-order Buffer)中有一个位置,逻辑寄存器需要使用到物理寄存器,内存操作需要使用到Load/ Store Buffer等,如果资源不可用,Allocate就处于等待。然后uop会被寄存器重命名,在p4处理器中,8个通用寄存器能使用128个物理寄存器,逻辑寄存器和物理寄存器之间的映射关系被保存在RAT( Register Alias Table)中。
指令的调度(Schedule)是乱序执行内核的核心,调度器根据uop操作数的准备情况和执行单元的准备情况决定uop什么时候开始执行。内存的访问和ALU指令的运算分别放在不同的队列中。
调度器连接了4个 Dispatch Ports(分派口),不同类型的指令由不同的 Dispatch Port分派,如下图所示:
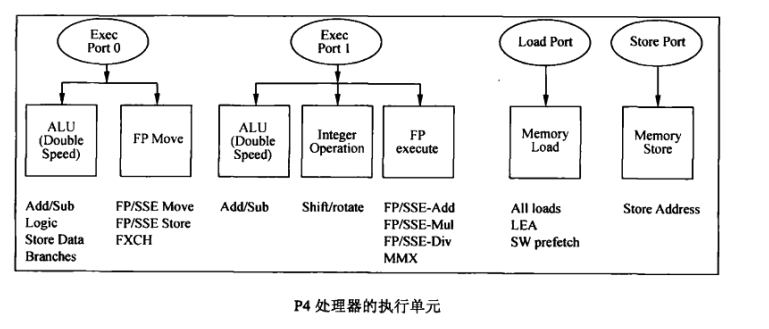
Exec Port0和 Exec Port1用于分派 ALU uop, Load Port用于分派 Load uop, Store Port用于分派 Store uop。ALU( double speed)表示 Exec Port每半个Cycle就能分派1个简单的ALU uop,于是在最理想的情况下, Exec Port0和 Exec Port 11每个 Cycle分别发射两条uoop, Load Port和 Store port每个Cycle分别发射1条uop,所以1个Cyle最多能发射6条uop。不过这只是理论上的情况,实际情况由于指令的依赖性,远远达不到6条uoop并行。实时上,处理器流水线每个阶段能并行处理的最大指令数都不一样,如 Trace Cache一个 Cycle输出3条uop,因此 Intel处理器几乎在每个阶段都有 Buffer来隔离它们之间的速率偏差。
后面的 Register Read、 Execute、 LI Cache(MEM)、 Register Write和经典的MIPS5级流水线类似。
乱序执行内核的最后一步,就是 Retire(退出),它负责更新IsA寄存器状态,指令按照顺序退出乱序执行内核。 Allocate、 Register Rename、 Schedule、 Retire组成了乱序控制。
P4处理器实际的流水线达到了20级,比上面的介绍要更为复杂。
Intel P4 CPU的更多相关文章
- Intel系列CPU的流水线技术的发展
Intel系列CPU的流水线技术的发展 CPU(Central processing Unit),又称“微处理器(Microprocessor)”,是现代计算机的核心部件.对于PC而言,CPU的规格与 ...
- ARM CPU与Intel x86 CPU性能比较
Qualcomm ARM CPU与Intel x86 CPU性能比较 随着移动互联网时代的到来,Qualcomm(高通).Texas Instruments(德州仪器)等基于ARM架构的CPU受到越来 ...
- AMD和Intel的CPU对比
http://www.lotpc.com/yjzs/5825.html 推荐文章:小白看AMD与intel的cpu架构,AMD慢的原因 CPU核心的发展方向是更低的电压.更低的功耗.更先进的制造工艺. ...
- Intel X86 CPU 系列的寻址方式
Intel X86 CPU 系列的寻址方式 数据总线和地址总线要尽量相同,这个是一个地址就是一个指针.
- intel服务器cpu命名规则
我们以E3.E5.E7系列进行一个详细解析.首先,Intel E3.E5.E7代表了3个不同档次的至强CPU,至强"E系列"的这种命名方式有些类似桌面上的Core i3,i5,i7 ...
- Intel的CPU漏洞:Spectre
最近觉得越来越忙,写博客都没精力了.一定是太沉迷农药和刷即刻了…… 17年年底,18年年初,Intel被爆出了Meltdown(熔断)和Spectre(幽灵)漏洞.等Spectre攻击的POC出来以后 ...
- Intel超低功耗CPU的一些信息
2015年底: Intel Braswell是专门针对超低功耗移动和桌面平台的一个家族,现有赛扬N3000/N3050/N3150.奔腾N3700四款型号,其中N300的热设计功耗只有区区4W,其他三 ...
- 【漏洞预警】Intel爆CPU设计问题,导致win和Linux内核重设计(附测试poc)
目前研究人员正抓紧检查 Linux 内核的安全问题,与此同时,微软也预计将在本月补丁日公开介绍 Windows 操作系统的相关变更. 而 Linux 和 Windows 系统的这些更新势必会对 Int ...
- InfoQ一波文章:菜鸟核心技术/Intel发布CPU新架构3D堆栈法/BDL/PaddlePaddle/百度第三代Spider/Tera
菜鸟智慧新物流核心技术全解析 孟靖 阅读数:63192018 年 12 月 14 日 16:00 2018 年天猫双 11 全球狂欢节已正式落下帷幕,最终成交额定格在 2135 亿元,物流订单 ...
随机推荐
- Linux驱动:内核等待队列
在Linux中, 一个等待队列由一个"等待队列头"来管理,等待队列是双向链表结构. 应用场合:将等待同一资源的进程挂在同一个等待队列中. 数据结构 在include/linux/w ...
- Django--中间件相关
一 什么是中间件 中间件顾名思义,是介于request与response处理之间的一道处理过程,相对比较轻量级,并且在全局上改变django的输入与输出.因为改变的是全局,所以需要谨慎实用,用不好会影 ...
- 大牛是怎么思考设计MySQL优化方案
在进行MySQL的优化之前,必须要了解的就是MySQL的查询过程,很多查询优化工作实际上就是遵循一些原则,让MySQL的优化器能够按照预想的合理方式运行而已. 1.优化的哲学 注:优化有风险,涉足需谨 ...
- Effectively bypassing kptr_restrict on Android
墙外通道:http://bits-please.blogspot.com/2015/08/effectively-bypassing-kptrrestrict-on.html In this blog ...
- 常见HTTP状态码及URL编码表
常见HTTP状态码 1xx: 信息 (用于表示临时响应并需要请求者执行操作才能继续的状态代码) 消息: 描述: 100 Continue 服务器仅接收到部分请求,但是一旦服务器并没有 ...
- webpack打包去除map文件及其他一些配置
一.vue-cli(3.x)搭建的项目,webpack(3.x)打包时,生成的map文件很大,目前又不知道是干嘛用的,所以就直接去掉了. 方法: 修改sourceMap配置成为false. 1:在bu ...
- 部署DTCMS到Jexus遇到的问题及解决思路---Linux环境搭建
最近朋友托我帮忙研究如何把一个DTCMS部署到Linux下,经过1天的研究,部署基本成功,可能有些细节还未注意到,现在把心得分享一下.过程比预期的要简单 身为.Net程序员,这个问题的第一步可能就是如 ...
- 常量(const)和只读变量(readonly)
//const修饰的数据叫做 常量 //常量一旦声明常量的值就不能改变. //常量在声明的时候 必须要赋初始值 //C#编译器在编译的时候 声明常量的那句话不见了. //在使用常量的地方就用常量的值代 ...
- JS 上传图片 + 预览功能(二)
简单粗暴 直接进入主题: Html <script src="../js/jquery-2.1.1.min.js"></script> <style& ...
- 读 《CSharp Coding Guidelines》有感
目录 基本原则 类设计指南 属性成员设计指南 其他设计指南 可维护性指南 命名指南 性能指南 框架指南 文档指南 布局指南 相关链接 C# 编程指南 前不久在 Github 上看见了一位大牛创建一个仓 ...