输入格式--InputFormat和InputSplit
1)InputFormat的类图:
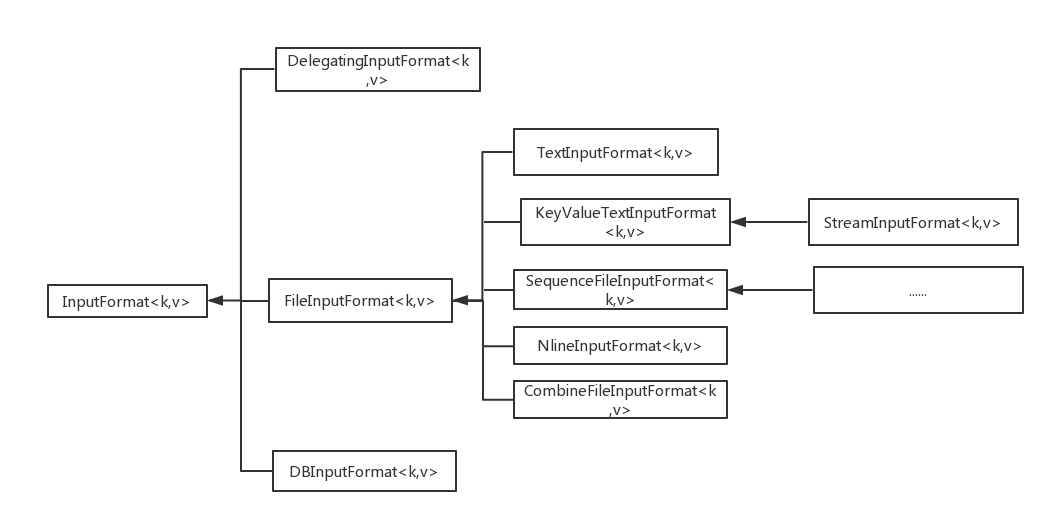
InputFormat 直接子类有三个:DBInputFormat、DelegatingInputFormat和FileInputFormat,分别表示输入文件的来源为从数据库、用于多个输入以及基于文件的输入。对于FileInputFormat,即从文件输入的输入方式,又有五个继承子类:CombineFileInputFormat,KeyValueTextInput,NLineInoutFormat,SequenceFileInputFormat,TextInputFormat。
2)InputSplit的类图
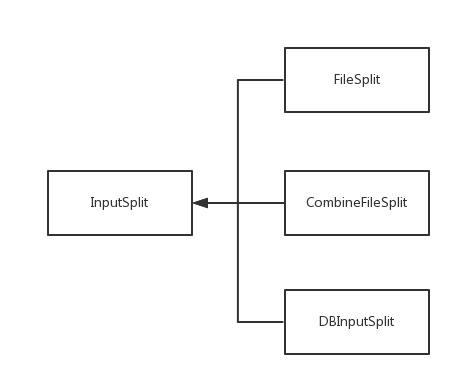
输入分片InputSplit 类有三个子类继承:FileSplit (文件输入分片),CombineFileSplit(多文件输入分片)以及DBInputSplit(数据块输入分片)。
3)InputFormat:
InputFormat有三个作用:
a.验证作业数据的输入形式和格式(要与MR程序中使用的格式相同,比如是TextInputFormat还是DBInputFormat)
b.将输入的数据切分为多个逻辑上的InputSplit,其中每一个InputSplit作为一个MApper的输入。
c.提供一个RecordReader,用于将InputSplit的内容转换为可以作为map输入的<k,v>键值对。
使用代码来指定MR作业数据的输入格式:
job.setInputFormatClass(TextInputFormat.class)
其实,InputFormat是一个抽象类,只是提供了两个抽象方法:
abstract List<InputSplit>getSplits(JobContext context);
abstract RecordReader<K,V> createRecordReader(InputSplit split,TaskAttemptContext context)
只提供两个抽象方法是有原因的,首先不同的格式的文件切片的方法不同(对应于getSplits),同一份文件可能希望读出不同形式的内容(对应createRecordReader)。
getSplits:
InputFormat的直接派生类需要实现此方法,例如FileInputFormat和DBInputFormat。另外,InputSplit的类型在选择了InputFormat的类型就已经确定了的,因为每个InputFormat的派生类都实现了getSplits,在此方法内部已经生成了对应的InputSplit。
createRecordReader:
FileInputFormat的派生类都实现了这个方法。
4)
InputSplit:
任何数据分块儿的实现都继承自抽象基类InputSplit,它位于org.apache.hadoop.mapreduce.InputSplit。此抽象类中有两个抽象方法:
abstract long getLength()
abstract String[] getLocation()
getLength()返回该块儿的大小,单位是字节。getLocation()返回存储该数据块的数据节点的名称,例如:String[0]="Slave1",String[1]="Slave2".
这两个方法也是需要在InputSplit的派生类中实现的。
5)
InputSplit的大小:
一个数据分片的大小由以下三行代码确定:
goalSize=totalSize/(numSplits==0?1:numSplits)
//totalSize是输入数据文件的大小,numSplits是用户设置的map数量,就是按照用户自己
//的意愿,每个分片的大小应该是goalSize
minSize=Math.max(job.getLong("mapred.min.split.size",1),minSplitSize)
//hadoop1.2.1中mapred-default.xml文件中mapred.min.split.size=0,所以job.getLong("mapred.min.split.size",1)=0,而minSplitSize是InputSplit中的一个数据成员,在File//Split中值为1.所以minSize=1,其目的就是得到配置中的最小值。
splitSize=Math.max(minSize,Math.min(goalSize,blockSize))
//真正的分片大小就是取按照用户设置的map数量计算出的goalSize和块大小blockSize中最小值(这是为了是分片不会大于一个块大小,有利于本地化计算),并且又比minSize大的值。
输入格式--InputFormat和InputSplit的更多相关文章
- hadoop输入格式(InputFormat)
InputFormat接口(package org.apache.hadoop.mapreduce包中)里包括两个方法:getSplits()和createRecordReader(),这两个方法分别 ...
- mapreduce的输入格式 --- InputFormat
InputFormat 接口决定了mapreduce如何切分输入文件. InputFormat 由getspilit和createRecordReader组成,getspilit主要是标记分片的初始位 ...
- MapReduce输入格式
文件是 MapReduce 任务数据的初始存储地.正常情况下,输入文件一般是存储在 HDFS 里面.这些文件的格式可以是任意的:我们可以使用基于行的日志文件, 也可以使用二进制格式,多行输入记录或者其 ...
- InputFormat,OutputFormat,InputSplit,RecordRead(一些常见面试题),使用yum安装64位Mysql
列举出hadoop常用的一些InputFormat InputFormat是用来对我们的输入数据进行格式化的.TextInputFormat是默认的. InputFormat有哪些类型? DBInpu ...
- hadoopMR自定义输入格式
输入格式 1.输入分片与记录 2.文件输入 3.文本输入 4.二进制输入 5.多文件输入 6.数据库格式输入 详细的介绍:https://blog.csdn.net/py_123456/ar ...
- MapReduce实战:自定义输入格式实现成绩管理
1. 项目需求 我们取有一份学生五门课程的期末考试成绩数据,现在我们希望统计每个学生的总成绩和平均成绩. 样本数据如下所示,每行数据的数据格式为:学号.姓名.语文成绩.数学成绩.英语成绩.物理成绩.化 ...
- MapReduce的输入格式
1. InputFormat接口 InputFormat接口包含了两个抽象方法:getSplits()和creatRecordReader().InputFormat决定了Hadoop如何对文件进行分 ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
- Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)
推荐 MapReduce分析明星微博数据 http://git.oschina.net/ljc520313/codeexample/tree/master/bigdata/hadoop/mapredu ...
随机推荐
- python Django 学习笔记(四)—— 使用MySQL数据库
1,下载安装MySQLdb类库 http://www.djangoproject.com/r/python-mysql/ 2,修改settings.py 配置数据属性 DATABASES = { 'd ...
- C# 自定义集合
自定义类型 public class Product { public int Id { get; set; } // 自增ID public string Name { get; set; } // ...
- 配置php5.6的运行环境
所需要的原材料:(提供链接) php-5.6.10-Win32-VC11-x86 (zip)(注意php版本分为了IIS版和Apache版) httpd-2.4.12-x86-r2(apache) ( ...
- 11G ORACLE RAC DBCA 无法识别asm磁盘组
ASM磁盘无法识别几种现象: 1) gi家目录或者其子目录权限错误 2)asm磁盘的权限错误 3)asm实例未启动或者asm磁盘组没有mount上 4)asm磁盘组资源没有在线 5)oracle用户的 ...
- bc命令
bc 命令: bc 命令是用于命令行计算器. 它类似基本的计算器. 使用这个计算器可以做基本的数学运算. [tough@localhost *|bc [tough@localhost expr ...
- locate 命令
ac OS X 下的 locate 在便利性上差了一些.主要是一些辅助工具.我在开始用 Mac OS X 下的locate 时,把过去知道的创立数据库的命令尝试了个遍,就是没有可行的.后来搜索网络才找 ...
- 官方的objective - c风格指南。
The official raywenderlich.com Objective-C style guide. This style guide outlines the coding convent ...
- Html5最简单的游戏Demo——Canvas绘图的弹弹球
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <t ...
- Notes of the scrum meeting(11/2)
meeting time:13:00~13:30p.m.,November 2nd,2013 meeting place:3号公寓楼一层 attendees: 顾育豪 ...
- “我爱淘”冲刺阶段Scrum站立会议3
完成任务: 将搜索框的界面已经实现以及部署到整个框架中. 计划任务: 实现搜索功能,通过数据库的链接,实现用户可以查到自己需要的书籍的信息. 遇到问题: 1.数据库的操作,怎么实现查询功能: 2.Ac ...