(二)Luence——代码实现索引及搜索
完成需求:使用Lucene完成对数据库中图书信息的索引和搜索功能。
1. 环境准备及工程搭建
1.1 环境准备
mysql5.5+java8+lucene4.10.3(目前最新7.0.1,这里够用就好)
需要注意:lucene从4.8版本以后,必须使用jdk1.7及以上。
1.2 工程搭建
- Mysql驱动包
- Analysis的包
- Core包
- QueryParser包
- Junit包(非必须)
2. 索引
2.1 采集数据
Book.java(省略get&set方法)
public class Book {
// 图书ID
private Integer id;
// 图书名称
private String name;
// 图书价格
private Float price;
// 图书图片
private String pic;
// 图书描述
private String description;
······
·····
}
BookDaoImpl.java(实现数据库连接和查询)
public class BookDaoImpl implements BookDao {
@Override
public List<Book> queryBooks() {
// 数据库链接
Connection connection = null// 预编译statement
PreparedStatement preparedStatement = null;
// 结果集
ResultSet resultSet = null;
// 图书列表
List<Book> list = new ArrayList<Book>();
try {
// 加载数据库驱动
Class.forName("com.mysql.jdbc.Driver");
// 连接数据库
connection = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/solr", "root", "123");
// SQL语句
String sql = "SELECT * FROM book";
// 创建preparedStatement
preparedStatement = connection.prepareStatement(sql);
// 获取结果集
resultSet = preparedStatement.executeQuery();
// 结果集解析
while (resultSet.next()) {
Book book = new Book();
book.setId(resultSet.getInt("id"));
book.setName(resultSet.getString("name"));
book.setPrice(resultSet.getFloat("price"));
book.setPic(resultSet.getString("pic"));
book.setDescription(resultSet.getString("description"));
list.add(book);
}
} catch (Exception e) {
e.printStackTrace();
}
return list;
}
}
2.2 创建索引
创建索引流程
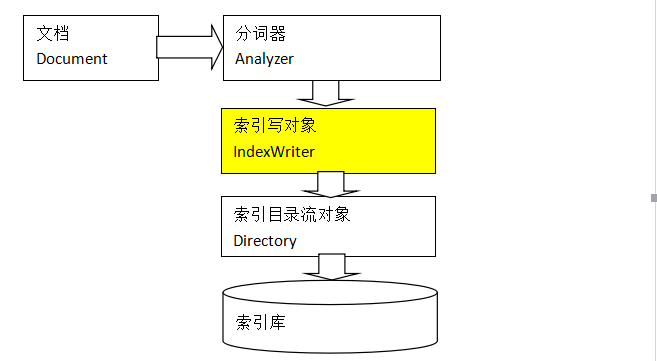
IndexWriter是索引过程的核心组件,通过IndexWriter可以创建新索引、更新索引、删除索引操作。IndexWriter需要通过Directory对索引进行存储操作。
Directory描述了索引的存储位置,底层封装了I/O操作,负责对索引进行存储。它是一个抽象类,它的子类常用的包括FSDirectory(在文件系统存储索引)、RAMDirectory(在内存存储索引)。
@Test
public void createIndex() throws Exception{
//采集数据
BookDao dao = new BookDaoImpl();
List<Book> list = dao.queryBooks(); //将采集到的数据封装到Document对象中
List<Document> docList = new ArrayList<>();
Document document;
for (Book book : list) {
document = new Document();
// store:如果是yes,则说明存储到文档域中
// 图书ID
Field id = new TextField("id", book.getId().toString(), Store.YES);
// 图书名称
Field name = new TextField("name", book.getName(), Store.YES);
// 图书价格
Field price = new TextField("price", book.getPrice().toString(), Store.YES);
// 图书图片地址
Field pic = new TextField("pic", book.getPic(), Store.YES);
// 图书描述
Field description = new TextField("description", book.getDescription(), Store.YES); // 将field域设置到Document对象中
document.add(id);
document.add(name);
document.add(price);
document.add(pic);
document.add(description); docList.add(document);
} // a)创建分词器,标准分词器(分析文档,对文档中的Field域进行分词)
Analyzer analyzer = new StandardAnalyzer(); // b)创建IndexWriterConfig对象
IndexWriterConfig cfg = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
// c)创建索引库目录,指定索引库的地址
File indexFile = new File("D:\\DBIndex\\");
Directory directory = FSDirectory.open(indexFile);
// d)创建IndexWriter对象
IndexWriter writer = new IndexWriter(directory, cfg); // e)通过IndexWriter对象将Document写入到索引库中
for (Document doc : docList) {
writer.addDocument(doc);
}
// f)关闭writer
writer.close();
}
2.3 分词
2.3.1 Lucene中分词主要分为两个步骤:分词、过滤
分词:将field域中的内容一个个的分词。
过滤:将分好的词进行过滤,比如去掉标点符号、大写转小写、词的型还原(复数转单数、过去式转成现在式)、停用词过滤
停用词:单独应用没有特殊意义的词。比如的、啊、等,英文中的this is a the等等。
例:要分词的内容
Lucene is a Java full-text search engine.
经过分词后:
lucene java full text search engine
2.3.2 参考org.apache.lucene.analysis.standard.standardAnalyzer的部分源码了解分词过程
@Override
protected TokenStreamComponents createComponents(final String fieldName, final Reader reader) {
final StandardTokenizer src = new StandardTokenizer(getVersion(), reader);
src.setMaxTokenLength(maxTokenLength);
TokenStream tok = new StandardFilter(getVersion(), src);
tok = new LowerCaseFilter(getVersion(), tok);
tok = new StopFilter(getVersion(), tok, stopwords);
return new TokenStreamComponents(src, tok) {
@Override
protected void setReader(final Reader reader) throws IOException {
src.setMaxTokenLength(StandardAnalyzer.this.maxTokenLength);
super.setReader(reader);
}
};
}
2.3.3 语汇单元的生成过程

从一个Reader字符流开始,创建一个基于Reader的Tokenizer分词器,经过三个TokenFilter生成语汇单元Token。
同一个域中相同的语汇单元(Token)对应同一个Term(词),它记录了语汇单元的内容及所在域的域名等,还包括来该token出现的频率及位置。
- 不同的域中拆分出来的相同的单词对应不同的term。
- 相同的域中拆分出来的相同的单词对应相同的term。
例如:图书信息里面,图书名称中的java和图书描述中的java对应不同的term
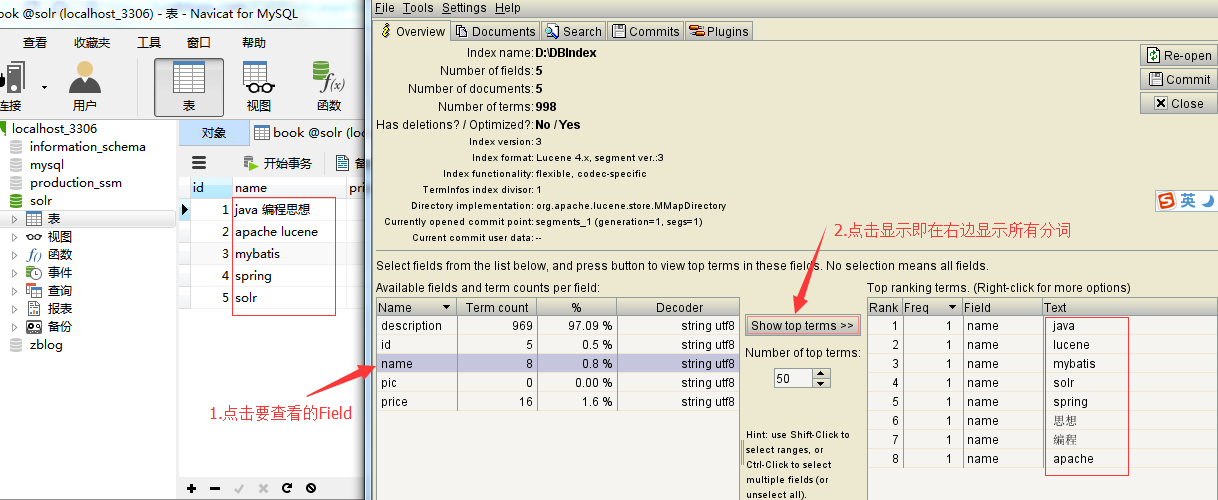
2.4 使用luke工具查看索引
Luke作为Lucene工具包中的一个工具(http://www.getopt.org/luke/),可以通过界面来进行索引文件的查询、修改。
打开Luke方法:
- 命令运行:cmd运行:java -jar lukeall-4.10.3.jar
- 手动执行:双击lukeall-4.10.3.jar
创建索引后,打开Luke,Path选为索引库的地址,确定即能查看到索引

luke应用
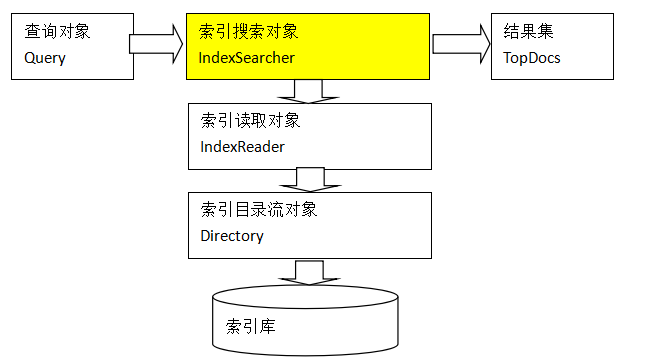
2.5 搜索流程
同数据库的sql一样,lucene全文检索也有固定的语法。 最基本的有比如:AND, OR, NOT 等(需要大写)
举个例子,用户想找一个description中包括java关键字和lucene关键字的文档。
它对应的查询语句:description:java AND lucene
2.5.1 使用luke搜索的例子
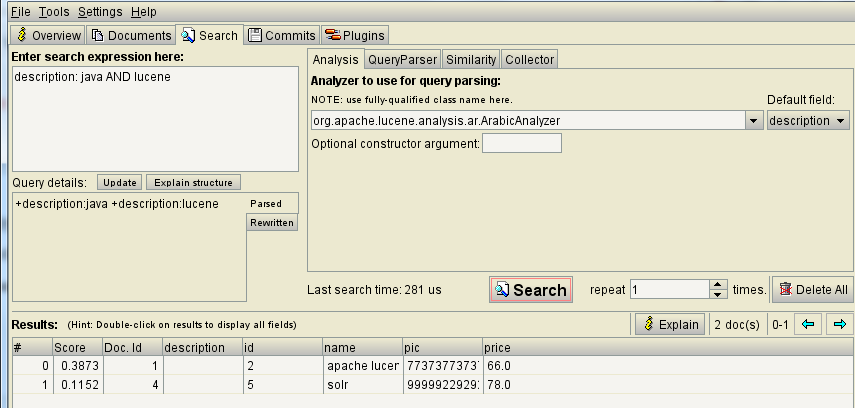
2.5.2 代码实现
@Test
public void indexSearch() throws Exception {
// 创建query对象
// 使用QueryParser搜索时,需要指定分词器,搜索时的分词器要和索引时的分词器一致
// 第一个参数:默认搜索的域的名称
QueryParser parser = new QueryParser("description", new StandardAnalyzer()); // 通过queryparser来创建query对象
// 参数:输入的lucene的查询语句(关键字一定要大写)
Query query = parser.parse("description:java AND lucene"); // 创建IndexSearcher
// 指定索引库的地址
File indexFile = new File("D:\\DBIndex\\");
Directory directory = FSDirectory.open(indexFile);
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader); // 通过searcher来搜索索引库
// 第二个参数:指定需要显示的顶部记录的N条
TopDocs topDocs = searcher.search(query, 10); // 根据查询条件匹配出的记录总数
int count = topDocs.totalHits;
System.out.println("匹配出的记录总数:" + count);
// 根据查询条件匹配出的记录
ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) {
// 获取文档的ID
int docId = scoreDoc.doc; // 通过ID获取文档
Document doc = searcher.doc(docId);
System.out.println("商品ID:" + doc.get("id"));
System.out.println("商品名称:" + doc.get("name"));
System.out.println("商品价格:" + doc.get("price"));
System.out.println("商品图片地址:" + doc.get("pic"));
System.out.println("==========================");
// System.out.println("商品描述:" + doc.get("description"));
}
// 关闭资源
reader.close();
}
(二)Luence——代码实现索引及搜索的更多相关文章
- 《Lucene in Action》(第二版) 第一章节的学习总结 ---- 用最少的代码创建索引和搜索
第一章节是介绍性质,但是通过这一章节的学习,我理解到如下概念: 1.Lucene由两部分组成:索引和搜索.索引是通过对原始数据的解析,形成索引的过程:而搜索则是针对用户输入的查找要求,从索引中找到匹配 ...
- u-boot移植(十二)---代码修改---支持DM9000网卡
一.准备工作 1.1 原理图 CONFIG_DM9000_BASE 片选信号是接在nGCS4引脚,若要确定网卡的基地址,则要根据片选信号的接口去确定. 在三星2440的DATASHEET中memory ...
- Lucene.net 从创建索引到搜索的代码范例
关于Lucene.Net的介绍网上已经很多了在这里就不多介绍Lucene.Net主要分为建立索引,维护索引和搜索索引Field.Store的作用是通过全文检查就能返回对应的内容,而不必再通过id去DB ...
- ElasticSearch入门系列(三)文档,索引,搜索和聚合
一.文档 在实际使用中的对象往往拥有复杂的数据结构 Elasticsearch是面向文档的,这意味着他可以存储整个对象或文档,然而他不仅仅是存储,还会索引每个文档的内容使之可以被搜索,在Elastic ...
- 理解Lucene索引与搜索过程中的核心类
理解索引过程中的核心类 执行简单索引的时候需要用的类有: IndexWriter.Directory.Analyzer.Document.Field 1.IndexWriter IndexWr ...
- 在Hadoop分布式文件系统的索引和搜索
FROM:http://www.drdobbs.com/parallel/indexing-and-searching-on-a-hadoop-distr/226300241?pgno=3 在今天的信 ...
- lucene索引并搜索mysql数据库[转]
由于对lucene比较感兴趣,本人在网上找了点资料,终于成功地用lucene对mysql数据库进行索引创建并成功搜索,先总结如下: 首先介绍一个jdbc工具类,用于得到Connection对象: im ...
- lucene简介 创建索引和搜索初步
lucene简介 创建索引和搜索初步 一.什么是Lucene? Lucene最初是由Doug Cutting开发的,2000年3月,发布第一个版本,是一个全文检索引擎的架构,提供了完整的查询引擎和索引 ...
- mysql进阶(二十六)MySQL 索引类型(初学者必看)
mysql进阶(二十六)MySQL 索引类型(初学者必看) 索引是快速搜索的关键.MySQL 索引的建立对于 MySQL 的高效运行是很重要的.下面介绍几种常见的 MySQL 索引类型. 在数 ...
随机推荐
- bzoj 2137: submultiple
Time Limit: 10 Sec Memory Limit: 259 MB Submit: 23 ...
- [NOIp2016提高组]组合数问题
题目大意: 给定n,m和k,对于所有的0<=i<=n,0<=j<=min(i,m)有多少对(i,j)满足C(j,i)是k的倍数. 思路: 先预处理出组合数,再预处理一下能整除个 ...
- Java学习笔记(8)
static修饰方法(静态的成员方法): 访问方式: 可以使用对象进行访问 对象.静态函数名(): 可以使用类名进行访问 类名. ...
- Spring的Bean生命周期理解
首先,在经历过很多次的面试之后,一直不能很好的叙述关于springbean的生命周期这个概念.今日对于springBean的生命周期进行一个总结. 一.springBean的生命周期: 如下图所示: ...
- [转]currentStyle和getComputedStyle的兼容写法
currentStyle:获取计算后的样式,也叫当前样式.最终样式. 优点:可以获取元素的最终样式,包括浏览器的默认值,而不像style只能获取行间样式,所以更常用到. 注意:不能获取复合样式如bac ...
- 使用 Google Code Prettify 实现代码高亮
今天这篇文章主要讲述使用 google-code-prettify 来实现代码的高亮显示,以前我使用 highlight.js 来实现文章中代码的高亮显示. prettify 非常小巧且配置简单,使用 ...
- NHibernate 集合映射基础(第四篇) - 一对一、 一对多、多对多小示例
映射文件,用于告诉NHibernate数据库里的表.列于.Net程序中的类的关系.因此映射文件的配置非常重要. 一.一对一 NHibernate一对一关系的配置方式使用<one-to-one&g ...
- 最好的拖拽js
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Android Studio导入第三方库的三种方法
叨叨在前 今天在项目中使用一个图片选择器的第三方框架——GalleryFinal,想要导入源码,以便于修改,于是上完查找了一下方法,想到之前用到过其他导入第三方库的方法,现在做个小总结,以防忘记. A ...
- Oracle SQL执行缓慢的原因以及解决方案
以下的文章抓哟是对Oracle SQL执行缓慢的原因的分析,如果Oracle数据库中的某张表的相关数据已是2亿多时,同时此表也创建了相关的4个独立的相关索引.由于业务方面的需要,每天需分两次向此表中 ...