zookeeper3.4.5集群安装
机器配置:
|
机器 |
Hostname |
user |
|
192.168.169.139 |
node139 |
hadoop |
|
192.168.169.140 |
node140 |
hadoop |
|
192.168.169.141 |
node141 |
hadoop |
root用户先新建用户hadoop
useradd hadoop
passwd hadoop
输入密码并确认密码即可
1、安装局部jdk
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

3台机器的hadoop用户中均需要安装并配置环境变量(jdk配置路径保持相同,解压后文件夹名称保持相同)
2、关闭防火墙
依次执行:
chkconfig iptables off(永久关闭,但需重启,所以执行下面语句进行临时关闭)
service iptables stop(临时关闭)
service iptables status(防火墙状态进行查看)
3、修改主机hostname
vi /etc/sysconfig/network(需重启生效)
echo ***(例如:node139)> /proc/sys/kernel/hostname(即时生效,需重新打开一个shell窗口方能看到)
4、配置静态的DNS域名
手动配置三台机器的域名,实现三台机器之间通过域名即可访问。
在node139机器上,使用root账号通过Xshell工具登录系统,修改hosts文件,
输入命令:vi /etc/hosts
增加3台主机的域名配置:
|
192.168.169.139 node139 192.168.169.140 node140 192.168.169.141 node141 |
保存退出即可
以上1-4步骤每台服务器均需操作
5、配置时钟同步ntpd服务
为使集群相关机器所有时间均保持相同,故而进行配置,很重要。
现在将139服务器作为服务端,root用户登录
修改配置:
vim /etc/ntp.conf
取消下面注释
|
server 127.127.1.0 fudge 127.127.1.0 stratum 10 (外部时间服务器不可用时,以本地时间作为时间服务) |
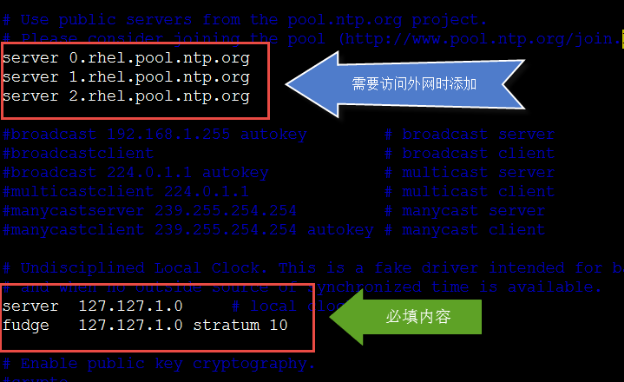
6、同样的root用户在客户端140和141服务器上面修改配置文件
vim /etc/ntp.conf
添加一行服务端的server,并取消下面标注的两行注释
|
server node139 server 127.127.1.0 fudge 127.127.1.0 stratum 10 |
7、启动ntp服务端(node139)上的ntp服务,启动后,一般需要5-10分钟左右的时候才能与外部时间
服务器开始同步时间(因此不急着执行9-11步骤,否则会报20 Mar 23:11:31 ntpdate[61783]: no server
suitable for synchronization found)。
输入命令: service ntpd start
8、输入命令 ps -ef | grep ntp 查看ntpd进程是否启动
9、客户端时间同步,输入命令 ntpdate node139 查看时间服务器同步时间 (node140和node141均执行)
10、输入命令hwclock -w 更新客户端bios时钟(node140和node141均执行)
11、输入命令 crontab -e 将时间同步设置为定时任务(node140和node141执行),添加下面内容
|
0-59/10 * * * * ntpdate node139 && hwclock -w |
注解:增加一个10分钟一次的时间同步任务
12、zookeeper集群安装(node139服务器hadoop用户)
上传zookeeper-3.4.5-cdh5.5.4.tar.gz包至hadoop用户主目录,解压,解压后删除tar包
上传包完毕后依次执行
安装包下载地址
链接:https://pan.baidu.com/s/1V4klTVidPEAkkn8W_f8_Ow
密码:koye
tar -zxvf zookeeper-3.4.5-cdh5.5.4.tar.gz
rm -rf zookeeper-3.4.5-cdh5.5.4.tar.gz
13、进入到zookeeper的安装目录
cd zookeeper-3.4.5-cdh5.5.4/

14、新建data和logs文件夹
mkdir data
mkdir logs
15、复制zoo_sample.cfg文件
cd conf/
cp zoo_sample.cfg zoo.cfg

16、修改zoo.cfg文件
vi zoo.cfg
|
tickTime=2000 initLimit=5 syncLimit=2 dataDir=/home/hadoop/cm/zookeeper-3.4.5-cdh5.5.4/data clientPort=2181 server.1=node139:2888:3888 server.3=node141:2888:3888 maxClientCnxns=60 minSessionTimeout=4000 maxSessionTimeout=300000 |

注释:
tickTime:心跳时间
initLimit:多少个心跳时间内,允许其他server连接并初始化数据
syncLimit:多少个tickTime内,允许follower节点同步
dataDir:存放内存数据文件目录,根据实际环境修改
dataLogDir:存放日志文件目录,根据实际环境修改
clientPort:监听端口,使用默认2181端口
server.x:配置集群主机信息,[hostname]:[通信端口]:[选举端口],根据自己的主机信息修改
maxClientCnxns:最大并发客户端数,用于防止DOS的,设置为0是不加限制
minSessionTimeout:最小的客户端session超时时间(单位是毫秒)
maxSessionTimeout:最大的客户端session超时时间(单位是毫秒)
17、将本机安装目录,通过scp全部拷贝至另外2台机器。
输入命令:
scp -r zookeeper-3.4.5-cdh5.5.4/ hadoop@node140:/home/hadoop/cm/
scp -r zookeeper-3.4.5-cdh5.5.4/ hadoop@node141:/home/hadoop/cm/
输入yes和密码就能完美复制过去
18、在三台服务器的zookeeper安装目录下的data文件夹下面新建文件myid
touch myid
vi myid
分别输入数字1、2、3,对应上面配置文件的server后面的数字


19、Zookeeper的启动停止
分别进入三台服务器的zookeeper安装目录,输入命令bin/zkServer.sh start 启动Zookeeper服务

20、进入节点,执行命令为:
bin/zkCli.sh -server 192.168.169.139:2181 回车
ls / (查看当前 ZooKeeper 中所包含的内容,输入命令quit 退出Zookeeper服务)
21、启动zookeeper服务后可以通过jps命令查看zookeeper进程,进程名为QuorumPeerMain
22、在zookeeper安装目录下输入命令 bin/zkServer.sh status 各个节点的状态
23、如果需要停止zookeeper服务,则在zookeeper安装目录上输入命令 bin/zkServer.sh stop
zookeeper3.4.5集群安装的更多相关文章
- 分布式Apache ZooKeeper-3.4.6集群安装
fesh个人实践,欢迎经验交流!本文Blog地址:http://www.cnblogs.com/fesh/p/3900253.html Apache ZooKeeper是一个为分布式应用所设计的开源协 ...
- (转)ZooKeeper-3.3.4集群安装配置
转载于 千与 的 http://blog.csdn.net/shirdrn/article/details/7183503 ZooKeeper是一个分布式开源框架,提供了协调分布式应用的基本服务,它向 ...
- ZooKeeper-3.3.4集群安装配置(转载)
ZooKeeper是一个分布式开源框架,提供了协调分布式应用的基本服务,它向外部应用暴露一组通用服务——分布式同步(Distributed Synchronization).命名服务(Naming S ...
- zookeeper3.4.13集群安装
环境: Centos7.6 Zookeeper3.4.13 Java1.8 安装前准备 安装java 官网下载jdk-8u201-linux-x64.tar.gz 备用 三台主机:192.168.2. ...
- ZooKeeper3.4.10集群安装配置-Docker
一. 服务器规划 主机 IP 端口 备注 b-mid-24 172.16.0.24 2181, 2888, 3888 2181:对cline端提供服务 3888:选举leader使用 2888:集群内 ...
- 原创zookeeper3.4.6集群安装
tar -zxvf zookeeper-3.4.6.tar.gz -C /home/hadoop/ vi ~/.bash_profile export ZOOKEEPER_HOME=/home/had ...
- ZooKeeper-3.3.4集群安装配置
https://blog.csdn.net/shirdrn/article/details/7183503
- ubuntu12.04+kafka2.9.2+zookeeper3.4.5的伪分布式集群安装和demo(java api)测试
博文作者:迦壹 博客地址:http://idoall.org/home.php?mod=space&uid=1&do=blog&id=547 转载声明:可以转载, 但必须以超链 ...
- Storm-1.0.1+ZooKeeper-3.4.8+Netty-4.1.3 HA集群安装
Storm-1.0.1+ZooKeeper-3.4.8+Netty-4.1.3 HA集群安装 下载Storm-1.0.1 http://mirrors.tuna.tsinghua.edu.cn/apa ...
随机推荐
- Vim 学习笔记二
1. 粘帖 p 光标前 P 2. 撤销对撤销的撤销 Ctrl+r 3. dl:删除一个字符,daw:删除一个单词,dap:删除一个段落 4. 单个c字符并无效果,cc删除整个一行 C:从当前光标出删除 ...
- linux内核开机logo显示调试
要使内核支持开机logo显示需要配置内核 配置如下: make menuconfig: Device Drivers ---> Graphics support ---> ...
- Xcode 调试方法总结
前言:编写代码过程中出现错误.异常是不可避免的.通常我们都需要进行大量的调试去寻找.解决问题.这时,熟练掌握调试技巧将很大程度上的提高工作效率.接下来就说说开发过程中Xcode的调试方法. 1. En ...
- python3颜色输出
遇到一个项目,需求是在python3中,处理结果显示高亮加颜色,然后资料整理如下 ### 格式: \033[显示方式;前景色;背景色m 这里的格式是规定了m后面的输出字符颜色样式 说明: 前景色 背景 ...
- 6:7 题一起MySQL数据库分库备份
企业Shell面试题6:MySQL数据库分表备份 请实现对MySQL数据库进行分表备份,用脚本实现. 解答: [root@db01 scripts]# cat fenbiao.sh #!/bin/ba ...
- Xcode下开发c静态库for ios CPU架构 静态库合并
新建一个Cocoa Touch Static Library工程 1,先在工程左侧删除“工程名Tests”下的文件与文件夹(从内往外删,最后删除"工程名Tests文件夹") :D ...
- 经典sql 语句大全
一.基础 1.说明:创建数据库 CREATE DATABASE database-name 2.说明:删除数据库 drop database dbname 3.说明:备份sql server --- ...
- 第一百四十七节,封装库--JavaScript,滑动导航
JavaScript,封装库--滑动导航 效果图 html <!--滑动导航--> <div id="nav"> <ul class="ab ...
- 最基础的PHP分类查询程序
最初级的PHP分类查询程序 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http ...
- iOS-.pch如何使用
今天我们要说的是.pch这个文件 我相信大家并不陌生,因为如果是新手开发工程师 总会被它搞得总报错误. 那么我们要知道.pch到底是干什么的,说白了就是一个预编译文件,在运行程序之前,要对头文件等一些 ...