python学习笔记:第7天 深浅拷贝
1. 基础数据类型补充
(1)join方法
join方法是把一个列表中的数据进行拼接,拼接成字符串(与split方法相反,split方法是把一个字符串切割成列表)
In [1]: l1 = ['a', 'b', 'c']
In [2]: s1 = ''
In [3]: for i in l1: # 如果不使用join方法需要自己使用循环拼接成字符串
...: s1 += i + '-'
In [4]: s1.strip('-')
Out[4]: 'a-b-c'
In [5]: l1
Out[5]: ['a', 'b', 'c']
In [6]: s2 = '-'.join(l1) # 使用join方法可以直接把字符串拼接
In [7]: s2
Out[7]: 'a-b-c'
(2)列表和字典的删除及类型转换
对于列表和字典的删除,有一个需要注意的地方,我们先来看个例子:
In [10]: l2 = [ 'a', 'b', 'c', 'e', 'f' ]
In [11]: for i in l2:
...: l2.remove(i)
In [12]: l2
Out[12]: ['b', 'e']
In [13]:
上面的例子中是遍历列表l2并循环删除列表中的元素,但是最后打印时还存在2个元素‘b’和‘e’,为什么这两个元素没有被删除,分析如下:
- 首次遍历列表时,i的值为‘a’,然后在列表中把元素删除后,列表中后面的索引位置都往前移动了一位,此时索引为0的位置的值为‘b’
- 第二次次遍历时,取到索引为1的元素是‘c’,也就是在列表中把‘c’删除了,然后后面的索引又往前移动了
- 第三次循环时i的值为‘f’,把元素‘f’删除后,循环结束,于是最后还剩下了2个元素
从上面的分析来看,我们可以得出:在循环遍历列表时,不应该去删除列表的元素,否则后续的程序可能出现意料之外的错误;如果需要删除多个元素可以使用下面这种方法:
In [19]: l2 = [ 'a', 'b', 'c', 'e', 'f' ]
In [20]: del_l2 = []
In [21]: for i in l2: # 遍历列表,把要删除的元素添加到另一个列表中,然后再对列表进行删除
...: del_l2.append(i)
In [22]: for i in del_l2:
...: l2.remove(i)
In [23]: l2
Out[23]: []
In [24]:
然后我们再来看下字典遍历时的问题:
In [24]: d1 = {'a':1, 'b':2}
In [25]: for k in d1:
...: del d1[k]
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-25-a77d5961c011> in <module>
----> 1 for k in d1:
2 del d1[k]
RuntimeError: dictionary changed size during iteration
In [26]:
从上面的结果可以看出,字典在遍历的时候不允许做删除操作(RuntimeError: dictionary changed size during iteration),要删除时跟列表一样,把要删除的元素的key保存在列表中,循环结束后再删除。
(3)字典的fromkey方法及数据类型转换
fromkey方法
dict中的fromkey(),可以帮我们通过list来创建⼀个dict:
In [26]: dict.fromkeys('abc', 100)
Out[26]: {'a': 100, 'b': 100, 'c': 100}
In [27]: dict.fromkeys('abc', [100, 200, 300])
Out[27]: {'a': [100, 200, 300], 'b': [100, 200, 300], 'c': [100, 200, 300]}
In [28]: d2 = dict.fromkeys('abc', 100)
In [29]: d2
Out[29]: {'a': 100, 'b': 100, 'c': 100}
In [30]: d3 = dict.fromkeys('abc', [100, 200, 300])
In [31]: d3
Out[31]: {'a': [100, 200, 300], 'b': [100, 200, 300], 'c': [100, 200, 300]}
fromkey方法接收两个参数,第一个是一个可迭代的数据,迭代出的每个元素作为字典的key,第二个参数作为字典value,但是这里要注意的是,如果第二个参数是一个可变的数据类型,只要修改其中一个值那么其他的值也会被修改:
In [32]: d3['a'].pop()
Out[32]: 300
In [33]: d3
Out[33]: {'a': [100, 200], 'b': [100, 200], 'c': [100, 200]}
数据类型的转换
- 元组 => 列表 list(tuple)
- 列表 => 元组 tuple(list)
- list=>str str.join(list)
- str=>list str.split()
- 转换成False的数据:
- 0,'',None,[],(),{},set() ==> False
- 不为空 ===> True
2. set集合
set中的元素是不重复的.⽆序的,⾥⾯的元素必须是可hash的(int, str, tuple,bool), 我们可以这样来记:set就是dict类型的数据但
是不保存value, 只保存key,set也⽤{}表⽰。
set中的元素是不重复的, 且⽆序的:
In [34]: s1 = {'a', 'a', 'b', 'b', 'c'}
In [35]: s1
Out[35]: {'a', 'b', 'c'}
In [36]: s2 = {1, 2, [11, 22]} # set集合中的元素必须是可hash的,但是set本身是不可hash的
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-36-e5e6f226f8af> in <module>
----> 1 s2 = {1, 2, [11, 22]}
TypeError: unhashable type: 'list'
In [37]:
使用元素唯一性的这个特性,可以对对数据去重处理:
In [39]: l1 = [1, 2, 3, 2, 2, 3]
In [40]: l1
Out[40]: [1, 2, 3, 2, 2, 3]
In [41]: set(l1)
Out[41]: {1, 2, 3}
In [42]:
字典的方法
- add 添加一个元素
- clear 清空元素
- pop 随机删除
- remove 删除指定元素
- update 对集合进行更新
- union 并集运算
- difference 差集运算
- intersection 交集运算
- symmetric_difference 反交集运算
- issubset 子集
- issuperset 超集
3. 深浅拷贝
(1)赋值操作
In [44]: a = [1, 2, 3, 4]
In [45]: b = a
In [46]: a.append(10)
In [47]: a, b
Out[47]: ([1, 2, 3, 4, 10], [1, 2, 3, 4, 10])
In [48]: c = {'a':1, 'b':2}
In [49]: d = c
In [50]: d['c'] = 5
In [51]: d
Out[51]: {'a': 1, 'b': 2, 'c': 5}
In [52]: c
Out[52]: {'a': 1, 'b': 2, 'c': 5}
In [53]:
对于list, set, dict来说, 直接赋值. 其实是把内存地址交给变量. 并不是复制⼀份内容. 所以当列表a变了后列表b也跟着变了,字典也是一样。
(2)浅拷贝
In [53]: l1
Out[53]: [1, 2, 3, 2, 2, 3]
In [54]: l2 = l1.copy()
In [55]: l2
Out[55]: [1, 2, 3, 2, 2, 3]
In [56]: l1.append('SEL')
In [57]: print(l1, l2)
[1, 2, 3, 2, 2, 3, 'SEL'] [1, 2, 3, 2, 2, 3]
In [58]:
从上面的例子可以看出,浅复制(使用copy方法)会把列表l1的内容赋值一份给l2,此时修改l1的内容并不会影响列表l2的内容,下面的图可以看出变量存放再内存的情况:
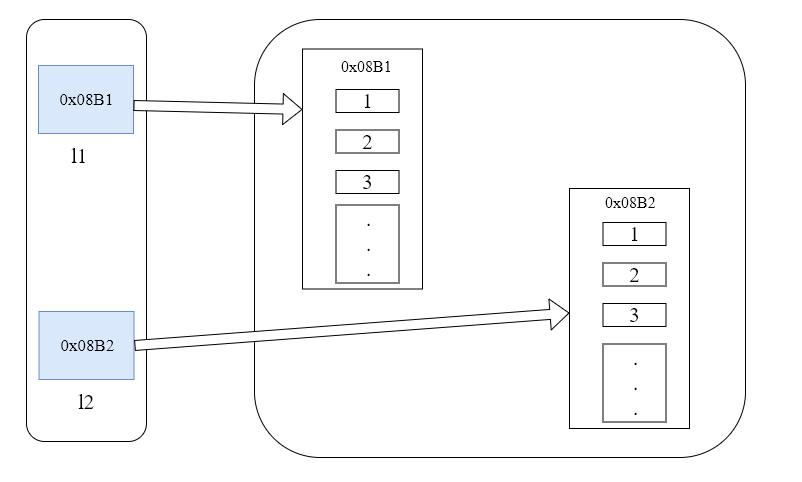
In [61]: l3 = l2.copy()
In [62]: l3
Out[62]: [1, 2, [3, 'SEL']]
In [63]: l2[2].append('hello')
In [64]: l2
Out[64]: [1, 2, [3, 'SEL', 'hello']]
In [65]: l3
Out[65]: [1, 2, [3, 'SEL', 'hello']]
In [66]:
但是此时我们可以看到,使用浅拷贝虽然会复制列表里面的内容,但仅仅是包含第一层,如果列表里面嵌套了列表,内层的列表的内容变话的话,被复制的列表也会变化,如上所示,把l2的值拷贝给l3之后,修改了l2中嵌套的列表,l3中的也会改变,如下图所示:
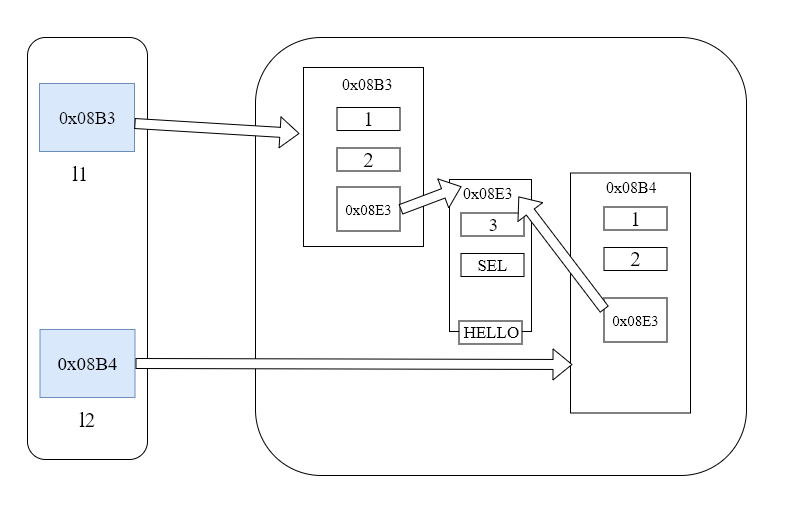
(3)深拷贝
In [66]: import copy # 需要导入copy模块
In [67]: l5 = [1, 2, ['a', 'b', ['aa', 'bb'], 3]]
In [68]: l6 = copy.deepcopy(l5)
In [69]: l5
Out[69]: [1, 2, ['a', 'b', ['aa', 'bb'], 3]]
In [70]: l6
Out[70]: [1, 2, ['a', 'b', ['aa', 'bb'], 3]]
In [71]: l5[2][2].append('cc')
In [72]: l5
Out[72]: [1, 2, ['a', 'b', ['aa', 'bb', 'cc'], 3]]
In [73]: l6
Out[73]: [1, 2, ['a', 'b', ['aa', 'bb'], 3]]
In [74]:
深度拷贝会完全复制整个列表里的内容,再次修改之前的列表时,新列表并不会受影响:
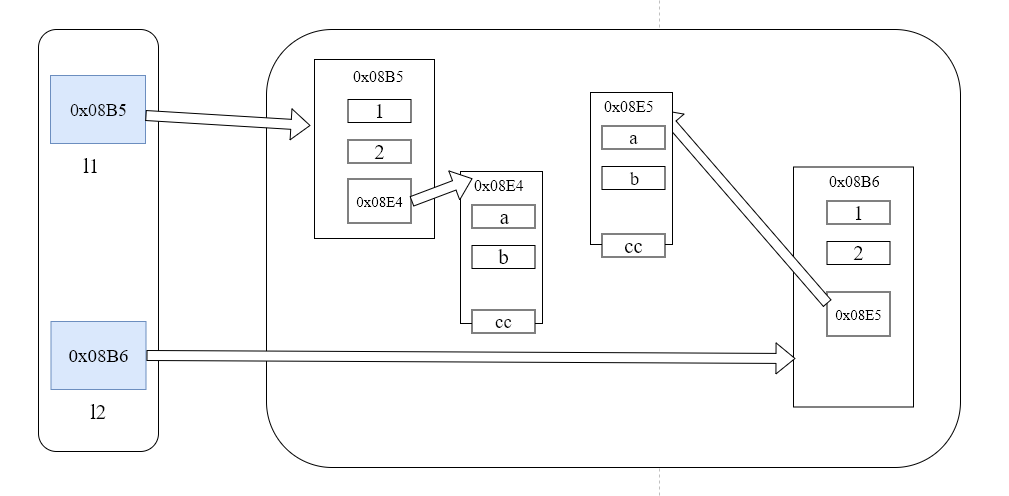
python学习笔记:第7天 深浅拷贝的更多相关文章
- Python学习笔记基础篇——总览
Python初识与简介[开篇] Python学习笔记——基础篇[第一周]——变量与赋值.用户交互.条件判断.循环控制.数据类型.文本操作 Python学习笔记——基础篇[第二周]——解释器.字符串.列 ...
- Python学习笔记(七)
Python学习笔记(七): 深浅拷贝 Set-集合 函数 1. 深浅拷贝 1. 浅拷贝-多层嵌套只拷贝第一层 a = [[1,2],3,4] b = a.copy() print(b) # 结果:[ ...
- Python学习笔记(八)
Python学习笔记(八): 复习回顾 递归函数 内置函数 1. 复习回顾 1. 深浅拷贝 2. 集合 应用: 去重 关系操作:交集,并集,差集,对称差集 操作: 定义 s1 = set('alvin ...
- python学习笔记(五岁以下儿童)深深浅浅的副本复印件,文件和文件夹
python学习笔记(五岁以下儿童) 深拷贝-浅拷贝 浅拷贝就是对引用的拷贝(仅仅拷贝父对象) 深拷贝就是对对象的资源拷贝 普通的复制,仅仅是添加了一个指向同一个地址空间的"标签" ...
- Python学习笔记,day5
Python学习笔记,day5 一.time & datetime模块 import本质为将要导入的模块,先解释一遍 #_*_coding:utf-8_*_ __author__ = 'Ale ...
- python 学习笔记 12 -- 写一个脚本获取城市天气信息
近期在玩树莓派,前面写过一篇在树莓派上使用1602液晶显示屏,那么可以显示后最重要的就是显示什么的问题了. 最easy想到的就是显示时间啊,CPU利用率啊.IP地址之类的.那么我认为呢,假设可以显示当 ...
- Python学习笔记(二)——列表
Python学习笔记(二)--列表 Python中的列表可以存放任何数据类型 >>> list1 = ['Hello','this','is','GUN',123,['I','Lov ...
- python学习笔记整理——字典
python学习笔记整理 数据结构--字典 无序的 {键:值} 对集合 用于查询的方法 len(d) Return the number of items in the dictionary d. 返 ...
- VS2013中Python学习笔记[Django Web的第一个网页]
前言 前面我简单介绍了Python的Hello World.看到有人问我搞搞Python的Web,一时兴起,就来试试看. 第一篇 VS2013中Python学习笔记[环境搭建] 简单介绍Python环 ...
- python学习笔记之module && package
个人总结: import module,module就是文件名,导入那个python文件 import package,package就是一个文件夹,导入的文件夹下有一个__init__.py的文件, ...
随机推荐
- POI读取xls和xlsx
import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import ...
- Day04——Python模块
一.模块简介 模块是实现了某个功能的代码集合,比如几个.py文件可以组成代码集合即模块.其中常见的模块有os模块(系统相关),file模块(文件操作相关) 模块主要分三类: 自定义模块 :所谓自定义模 ...
- laravel5.5 自定义验证规则——手机验证RULE
相信很多小伙伴和我一样烦恼,laravel没有自带手机号的验证,每次验证手机号都要写正则这类的规则,每次都是repeat yourself!违背了编码的一个原则,就是Don't repeat your ...
- php解决高并发设想
1.我突然想到一个解决系统并发的一个方法, 当然不算太友好, 就是并发时候,首先加载系统负载量文件, 如果到达一个值,比如60%,就跳到404页面,或者输出稍后之类的这样 2.静态文件和图片存到cdn ...
- webpack学习(五)配置详解
配置详解 //使用插件html-webpack-plugin打包合并html //使用插件extract-text-webpack-plugin打包独立的css //使用UglifyJsPlugin压 ...
- SAP S/4HANA使用ABAP获得生产订单的状态
在S/4HANA里,我们如何根据一个销售订单的行项目,查看对应的生产订单状态? 双击行项目: 点击Schedule line: 这里就能看到生产订单的ID和状态了. 其中订单的状态存储在表vsaufk ...
- web服务器、app(应用)服务器、DB后端性能瓶颈和分析
性能测试day07_性能瓶颈和分析 https://www.cnblogs.com/leixiaobai/p/9463748.html 其实如果之前都做的很到位的话,那么再加上APM工具(dynaTr ...
- 可变对象(immutable)和不可变对象(mutable)
可变对象(immutable)和不可变对象(mutable) 这个是之前一直忽略的一个知识点,比方说说起String为什么是一个不可变对象,只知道因为它是被final修饰的所以不可变,而没有抓住不可变 ...
- 富文本使用之wangEditor3
一.介绍: wangEditor —— 轻量级 web 富文本编辑器,配置方便,使用简单.支持 IE10+ 浏览器. 二.使用方式: 直接下载:https://github.com/wangfupen ...
- 阿里云linux服务器登录失败,Connection closed
ssh_exchange_identification: read: Connection reset by peer报错如下: [root@izbp17x1~]# ssh admin@139.196 ...