Hadoop1.0 与Hadoop2.0
.png)
Hadoop1.0 与Hadoop2.0的更多相关文章
- Hadoop1.0 和 Hadoop2.0
date: 2018-11-16 18:54:37 updated: 2018-11-16 18:54:37 1.从Hadoop整体框架来说 1.1 Hadoop1.0即第一代Hadoop,由分布式存 ...
- Hadoop2.0的基本构成总览
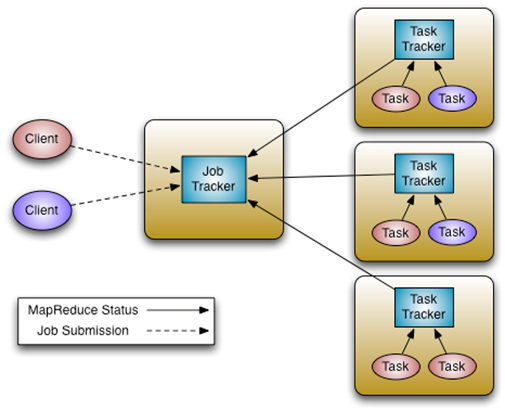
Hadoop1.x和Hadoop2.0构成图对比 Hadoop1.x构成: HDFS.MapReduce(资源管理和任务调度):运行时环境为JobTracker和TaskTracker: Hadoop ...
- Hadoop2.0(HDFS2)以及YARN设计的亮点
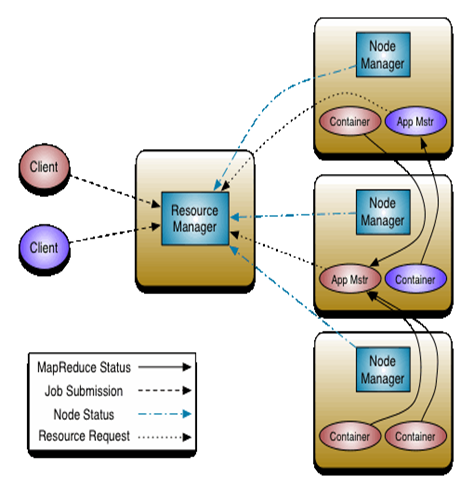
YARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave,ResouceManager负责对各个Node ...
- hadoop2.2.0 + hbase 0.94 + hive 0.12 配置记录
一开始用hadoop2.2.0 + hbase 0.96 + hive 0.12 ,基本全部都配好了.只有在hive中查询hbase的表出错.以直报如下错误: java.io.IOException: ...
- Cloudera Hadoop 5& Hadoop高阶管理及调优课程(CDH5,Hadoop2.0,HA,安全,管理,调优)
1.课程环境 本课程涉及的技术产品及相关版本: 技术 版本 Linux CentOS 6.5 Java 1.7 Hadoop2.0 2.6.0 Hadoop1.0 1.2.1 Zookeeper 3. ...
- hadoop2.0的datanode数据存储文件夹策略的多个副本
在hadoop2.0在,datanode数据存储盘选择策略有两种方式复制: 首先是要遵循hadoop1.0磁盘文件夹投票,实现类:RoundRobinVolumeChoosingPolicy.java ...
- hadoop2.0的数据副本存放策略
在hadoop2.0中,datanode数据副本存放磁盘选择策略有两种方式: 第一种是沿用hadoop1.0的磁盘目录轮询方式,实现类:RoundRobinVolumeChoosingPolicy.j ...
- HDP2.0.6+hadoop2.2.0+eclipse(windows和linux下)调试环境搭建
花了好几天,搭建好windows和linux下连接HDP集群的调试环境,在此记录一下 hadoop2.2.0的版本比hadoop0.x和hadoop1.x结构变化很大,没有eclipse-hadoop ...
- Hadoop2.0源码包简介
Hadoop2.0源码包简介 1.解压源码包: 2.目录结构: hadoop-common-project:Hadoop基础库所在目录,如RPC.Metrics.Counter等.包含了其它所有模块可 ...
随机推荐
- asp.net ashx导出excel到前台
最近有一个项目使用以前的ashx,不能使用FileResult,只有通过response返回拼接好的字符串.但是通过查阅资料拼接的字符串总是提示文件格式不匹配,虽然能正常打开,但是体验很不好,在此总结 ...
- Hadoop学习---Zookeeper+Hbase配置学习
软件版本号: JDK:jdk-8u45-linux-i586.tar.gz Zookeeper:zookeeper-3.4.6 Hbase:hbase-1.0.0-bin 一.JDK版本更换 由于之前 ...
- ArrayBlockingQueue详解
转自:https://blog.csdn.net/qq_23359777/article/details/70146778 1.介绍 ArrayBlockingQueue是一个阻塞式的队列,继承自Ab ...
- June 25th 2017 Week 26th Sunday
There is always that one song that brings back old memories. 总有那么一首歌,让你想起那些旧的回忆. There are seveal so ...
- .net 流(Stream) - StreamWriter和StreamReader、BinaryReader和BinaryWriter
转自:http://www.oseye.net/user/kevin/blog/86 一.StreamWriter和StreamReader 从上一篇博文可知文件流.内存流和网络流操作的都是字节,每次 ...
- [原]如何在Android用FFmpeg+SDL2.0之同步视频
关于视频同步的原理可以参考http://dranger.com/ffmpeg/tutorial05.html 和 [原]基础学习视频解码之同步视频 这两篇文章,本文是在这两篇的基础上移植到了Andro ...
- springMvc返回Json中自定义日期格式
(一)输出json数据 springmvc中使用jackson-mapper-asl即可进行json输出,在配置上有几点: 1.使用mvc:annotation-driven 2.在依赖管理中添加ja ...
- AtomicInteger线程安全的计数器
在多线程环境下计数的时候,++i和i++是不安全的,故而需要加锁机制,也可以使用volatile关键字进行修饰,但是更简单有效的方式是使用Atomic类
- PL/SQL 编程(二)
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/u011685627/article/details/26299399 1 For循环 ...
- BZOJ 2120 数颜色 【带修改莫队】
任意门:https://www.lydsy.com/JudgeOnline/problem.php?id=2120 2120: 数颜色 Time Limit: 6 Sec Memory Limit: ...