四、MapReduce 基础
是一个并行计算框架(计算的数据源比较广泛-HDFS、RDBMS、NoSQL),Hadoop的 MR模块充分利用了HDFS中所有数据节点(datanode)所在机器的内存、CUP以及少量磁盘完成对大数据集的分布式计算。MapReduce将计算分为两个阶段:
- 通过将一个大的计算任务分割成若干个小任务(计算目标数据集的分割),每一个小任务会分配给所有的计算节点(datanode所在物理机器)完成对局部数据的归类和分析,我们通常把该阶段定义为Map阶段,在Map阶段结束后会在本地系统磁盘存储计算的临时结果;
- 当Map阶段所有节点完成对局部数据的归类分析后,MR框架会启动Reduce任务完成对Map阶段的局部计算临时结果汇总,把以上阶段成为Reduce阶段。
I、计算流程
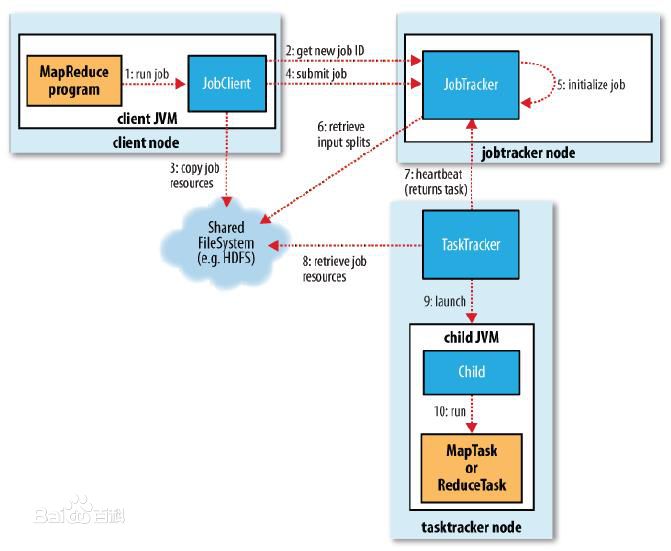
II、YARN环境搭建
配置文件
[root@CentOS ~]# vi /usr/hadoop-2.6.0/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--Resource Manager-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>CentOS</value>
</property>
[root@CentOS ~]# mv /usr/hadoop-2.6.0/etc/hadoop/mapred-site.xml.template /usr/hadoop-2.6.0/etc/hadoop/mapred-site.xml
[root@CentOS ~]# vi /usr/hadoop-2.6.0/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
启动计算服务
[root@CentOS ~]# start-yarn.sh
[root@CentOS ~]# jps
1584 SecondaryNameNode
1364 NameNode
1446 DataNode
5229 Jps
III、HelloWorld of MapReduce 编程
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.6.0</version>
</dependency>
IpMapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @program: hadoop_01
* @description:
* @author: luoht
* @create: 2019-01-04 16:08
**/
public class IpMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
/**
*192.168.0.12 1 001 click 5000 2019-01-04 14:44:00
* @param key :输入文本行字节偏移量
* @param value:输入文本行
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] tokens = value.toString().split("");
String ip = tokens[0];
context.write(new Text(ip),new IntWritable(1));
}
}
IpReducer
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @program: hadoop_01
* @description:
* @author: luoht
* @create: 2019-01-04 16:13
**/
public class IpReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
/**
*
* @param key :ip
* @param values: Int[]{1,1,1,..}
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int total = 0;
for (IntWritable value : values) {
total+=value.get();
}
context.write(key,new IntWritable(total));
}
}
封装job
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @program: hadoop_01
* @description:
* @author: luoht
* @create: 2019-01-04 16:15
**/
public class CustomJobSubmiter extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
/*1. 封装job 对象*/
Configuration conf=getConf();
Job job = Job.getInstance(conf);
/*2. 设置数据读入和写出的格式*/
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
/*3. 设置处理数据的路径*/
Path dst = new Path("/tt/test");
TextOutputFormat.setOutputPath(job,dst);
/*4. 设置数据计算逻辑*/
Path src=new Path("/tt/access");
TextInputFormat.addInputPath(job,src);
Path dst=new Path("/tt/result");
TextOutputFormat.setOutputPath(job,dst);
/*5. 设置Mapper和Reducer输出泛型*/
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
/*6. 提交任务*/
job.submit();
return 0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new CustomJobSubmiter(),args);
}
}四、MapReduce 基础的更多相关文章
- Hadoop 综合揭秘——MapReduce 基础编程(介绍 Combine、Partitioner、WritableComparable、WritableComparator 使用方式)
前言 本文主要介绍 MapReduce 的原理及开发,讲解如何利用 Combine.Partitioner.WritableComparator等组件对数据进行排序筛选聚合分组的功能.由于文章是针对开 ...
- 7,MapReduce基础
目录 MapReduce基础 一.关于MapReduce 二.MapReduce的优缺点 三.MapReduce的执行流程 四.编写MapReduce程序 五.MapReduce的主要执行流程 Map ...
- [Hadoop in Action] 第4章 编写MapReduce基础程序
基于hadoop的专利数据处理示例 MapReduce程序框架 用于计数统计的MapReduce基础程序 支持用脚本语言编写MapReduce程序的hadoop流式API 用于提升性能的Combine ...
- Android Studio系列教程四--Gradle基础
Android Studio系列教程四--Gradle基础 2014 年 12 月 18 日 DevTools 本文为个人原创,欢迎转载,但请务必在明显位置注明出处!http://stormzhang ...
- php四种基础排序算法的运行时间比较
/** * php四种基础排序算法的运行时间比较 * @authors Jesse (jesse152@163.com) * @date 2016-08-11 07:12:14 */ //冒泡排序法 ...
- SQL Server 2008空间数据应用系列四:基础空间对象与函数应用
原文:SQL Server 2008空间数据应用系列四:基础空间对象与函数应用 友情提示,您阅读本篇博文的先决条件如下: 1.本文示例基于Microsoft SQL Server 2008 R2调测. ...
- 初识webpack——webpack四个基础概念
前面的话 webpack是当下最热门的前端资源模块化管理和打包工具.它可以将许多松散的模块按照依赖和规则打包成符合生产环境部署的前端资源.当webpack处理应用程序时,它会递归地构建一个依赖关系图表 ...
- 二十四. Python基础(24)--封装
二十四. Python基础(24)--封装 ● 知识结构 ● 类属性和__slots__属性 class Student(object): grade = 3 # 也可以写在__slots ...
- 十四. Python基础(14)--递归
十四. Python基础(14)--递归 1 ● 递归(recursion) 概念: recursive functions-functions that call themselves either ...
- 四. Python基础(4)--语法
四. Python基础(4)--语法 1 ● 比较几种实现循环的代码 i = 1 sum = 0 while i <= 10: # 循环10-1+1=10次 sum += i i ...
随机推荐
- easyui grid 本地做分页
背景: 有的数据不是很多,但是有分页的需求,这个时候后台往往没有做分页,我们是一次请求了所有的数据. 代码: dataSource 为 grid 里的数据源 html部分: <table id= ...
- 十、一行多个:使用float布局的经典方法 ---接(一)
1.使用float必须要清除float:即在使用float元素的父级元素上清除float. 清除float的方法有三种,在父元素上加:1.width: 100% 或者固定宽度 +overflow:hi ...
- recommendation baselines
整理recommendation baseline 的实现代码和方法归类: bpr: https://github.com/gamboviol/bpr fpmc: https://github.c ...
- 用虚拟信用卡注册Google Play开发者账号
本文首发于http://www.abcdsxg.cn/free/net/562 虚拟信用卡 首先介绍一下虚拟信用卡(Virtual Credit Card),顾名思义,虚拟就是没有实体卡,一般都是在提 ...
- Linux->ZooKeeper开机启动的俩种方式
两种方式可以实现开机自启动 第一种:直接修改/etc/rc.d/rc.local文件 在/etc/rc.d/rc.local文件中需要输入两行, 其中export JAVA_HOME=/usr/jav ...
- 绘制播放音乐时的音波图形的View
绘制播放音乐时的音波图形的View 这个效果类似于这个哦: 效果如下: 源码: MusicView.h 与 MusicView.m // // MusicView.h // Music // // C ...
- Python学习---高阶函数的学习
高阶函数 高阶函数:函数名可以作为参数传递输入,函数名还可以作为返回值返回 函数名可以重新赋值,因为其本身就是一个变量 函数本身就是一个对象, 函数的变量名f本身就是指向函数本身的,加上括 ...
- backtrack渗透测试中常用的命令总结
ping 域名/ip 测试本机到远端主机是否联通. dig 域名/ip 查看域名解析的详细信息. host -l 域名 dns服务器 传输zone. 扫描 nmap: -sS 半开扫描TCP和SYN扫 ...
- 轻松bypass360网站卫士WAFSQL注入防护
随便网上找了一个网站,只是测试一下,没有干非法的事情! code 区域 http://www.py-guanyun.com/CompHonorBig.asp?id=49 code 区域 http:// ...
- create-react-app部署到GitHub Pages时报错:Failed to get remote。origin.url
最近使用create-react-app脚手架开发了一个私人博客:点击跳转,在部署到GitHub Pages的时候报了一个错误,具体如下: 在create-react-app的GitHub库的issu ...