Mysql Sql Explain
1.使用mysql explain的原因
在我们php程序员的日常写代码中,有时候会发现我们写的sql语句运行的特别慢,导致响应时间特别长,这种情况在高并发的情况下,我们的网站会直接崩溃,为什么双十一的淘宝在如此高的并发访问量的情况下依旧运转良好,除了过硬的设备以及服务器分流等技术外,良好的sql查询语句也是功不可没的! 我们会去寻找并且记录一些执行时间比较久的SQL语句,找出这些SQL语句并不意味着完事了,此时我们常常用到explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看。
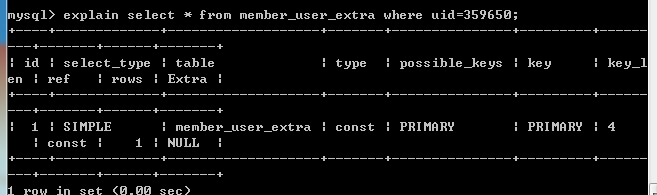
一个完整的查询语句的explain展现在我们眼前(explain也只能使用在select语句中):
expain出来的信息有10列,分别是id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra,下面对这些字段出现的可能进行解释:
1. id:
包含一组数字,表示查询中执行select子句或操作表的顺序
id相同,执行顺序由上至下,否则id值越大(通常子查询会产生)优先级越高,越先被执行
id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行
id列为null的就表是这是一个结果集,不需要使用它来进行查询。
2.select_type列常见的有:
表示查询中每个select子句的类型
用于处理查询的索引长度,如果是单列索引,那就整个索引长度算进去,如果是多列索引,那么查询不一定都能使用到所有的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列,这里不会计算进去。留意下这个列的值,算一下你的多列索引总长度就知道有没有使用到所有的列了。要注意,mysql的ICP特性使用到的索引不会计入其中。另外,key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。
Mysql Sql Explain的更多相关文章
- MySQL SQL Explain输出学习
MySQL的explain命令语句提供了如何执行SQL语句的信息,解析SQL语句的执行计划并展示,explain支持select.delete.insert.replace和update等语句,也支持 ...
- MySQL的EXPLAIN命令用于SQL语句的查询执行计划
MySQL的EXPLAIN命令用于SQL语句的查询执行计划(QEP).这条命令的输出结果能够让我们了解MySQL 优化器是如何执行SQL 语句的.这条命令并没有提供任何调整建议,但它能够提供重要的信息 ...
- mysql sql优化实例
mysql sql优化实例 优化前: pt-query-degist分析结果: # Query 3: 0.00 QPS, 0.00x concurrency, ID 0xDC6E62FA021C85B ...
- Mysql之EXPLAIN显示using filesort
索引使用经验: 1. 一条 SQL 语句只能使用 1 个索引 (5.0-),MySQL 根据表的状态,选择一个它认为最好的索引用于优化查询 2. 联合索引,只能按从左到右的顺序依次使用 Using w ...
- 详解MySQL中EXPLAIN解释命令
Explain 结果解读与实践 基于 MySQL 5.0.67 ,存储引擎 MyISAM . 注:单独一行的"%%"及"`"表示分隔内容,就象分开“第一 ...
- 巧用MySQL之Explain进行数据库优化
前记:很多东西看似简单,那是因为你并未真正了解它. Explain命令用于查看执行效果.虽然这个命令只能搭配select类型语句使用,如果你想查看update,delete类型语句中的索引效果,也不是 ...
- mysql sql执行顺序
<pre name="code" class="html">mysql> explain select * from (select * fr ...
- mysql sql语句执行时是否使用索引检查方法
在日常开发中,使用到的数据表经常都会有索引,这些索引可能是开发人员/DBA建表时创建的,也可能是在使用过程中新增的.合理的使用索引,可以加快数据库查询速度.然而,在实际开发工作中,会出现有些sql语句 ...
- MYSQL SQL语句技巧初探(一)
MYSQL SQL语句技巧初探(一) 本文是我最近了解到的sql某些方法()组合实现一些功能的总结以后还会更新: rand与rand(n)实现提取随机行及order by原理的探讨. Bit_and, ...
随机推荐
- ZooKeeper内部构件
引言 这个文档包含关于ZK内部工作的信息.目前为止,它讨论了这些主题: 原子广播 日志 原子传播 ZK的核心是一个原子的通信系统,它使所有的服务端保持同步. 保证.属性和定义 通过使用ZooKeepe ...
- 可以随时拿取spring容器中Bean的工具类
前言 在Spring帮我们管理bean后,编写一些工具类的时候需要从容器中拿到一些对象来做一些操作,比如字典缓存工具类,在没有找到字典缓存时,需要dao对象从数据库load一次,再次存入缓存中.此时需 ...
- 51Nod 1095 Anigram单词 | Hash
Input示例 5 add dad bad cad did 3 add cac dda Output示例 1 0 2 题意:一系列字符串,查询字符串S,能通过其他字符串交换串内字符顺序得到的字符串个数 ...
- [Luogu 2580] 于是他错误的点名开始了
[Luogu 2580] 于是他错误的点名开始了 不用好奇我为什么突然发水题题解- 突然觉得自己当年的幼儿园码风太幼稚,就试图把数据结构什么的用指针重写一遍- 想当年因为空间开太大而全 RE,调了一下 ...
- IntelliJ IDEA 热加载
修改java文件后 win按:Ctrl+Shift+F9 mac按:cmd+Shift+F9 tomcat-maven-plugin 启动的项目也用这个快捷键热加载
- 删除linux上7天前后缀名.sql的文件
#!/bin/bash#delete the file of 7 days agofind /data/mysqlbackup/ -mtime +7 -name "*.sql" - ...
- Mysql优化小记1
在项目开发中,需要写个windows服务从sqlserver复制数据到mysql(5.6.13 Win64(x86_64)),然后对这些数据进行计算分析.每15分钟复制一次,每次复制大概200条数据, ...
- 【POJ】2892 Tunnel Warfare
[算法]平衡树(treap) [题解]treap知识见数据结构 在POJ把语言从G++换成C++就过了……??? #include<cstdio> #include<algorith ...
- Vue前端开发规范(山东数漫江湖)
一.强制 1. 组件名为多个单词 组件名应该始终是多个单词的,根组件 App 除外. 正例: export default { name: 'TodoItem', // ... } 反例: expor ...
- JS的prototype和__proto__
一.prototype和__proto__的概念 prototype是函数的一个属性(每个函数都有一 个prototype属性),这个属性是一个指针,指向一个对象.它 是显示修改对象的原型的属性. _ ...