mysql之调优概论
一 简介
咱们先不说cpu的频率,内存的大小(这个和索引一样重要,但不是本文讨论的内容),硬盘的寻道时间。想起mysql的调优,最起码的必须知道explain执行计划,慢sql日志,老旧的profile命令,新的performance_schema性能视图和information_schema中当前事务和内存占用信息的相关表,还有 show engine innodb status的诊断信息,以及某些metrix中的tps,qps,iops的指标。
以上是为调优准备的一些工具,而数据库都会为高可用提供很多大大小小的功能,大的有:复制,组复制,分区,文件链接:即log日志与数据文件等可分别放置不同硬盘。小的有:计算列,为列计算hash,索引合并,索引下推,MRR,BKA,Loose Index 等算法,以及填充因子等。
当然,没有视图索引和分布式分区视图,以及join仅仅只支持nested这是mysql的不足,而sql server join的算法支持三种,loop while hash,极大的改善join的速度。mysql自带提升性能的功能并不多
,其他的就是经验之谈,比如静态表,不要在子查询中使用函数,尽量将子查询变为join查询,非字符串和blob列永远比其他的数字或者时间列要慢,join |order by|group一定不要让其在硬盘生成临时表,当然这个和内存有关,窄表和宽表设计等,当然最后还是取决你的业务类型。
优化入手有两种方法,一种是运行时的,即在运行的服务器上优化,一种是开发过程中。而无论哪种,performance_schema都会需要。
二 performance_schema讲解
性能视图是每个数据库中都会有的,sql server是dm_*开头的一系列内存表。而mysql就是performance_schema库中的各种表,先看入口的几个表:
SELECT * FROM setup_timers; -- 计时定义表
select * from setup_actors; -- 那些用户需要收集信息
select * from Setup_objects; -- 那些对象需要收集信息,比如mysql表,
select * from setup_consumers; -- 那些仪器的分类需要收集
select * from setup_instruments; -- 收集仪器,每一个功能点都会有仪器的事件,开始和结束,然后开启那个仪器,就会收集那个仪器的数据
首先我们看开启performance_schema的开关:
show variables like 'performance_schema' -- 这是一个read only变量
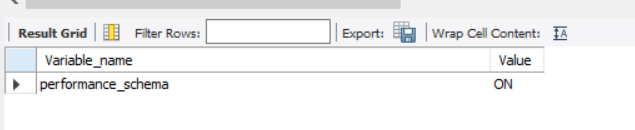
如果为OFF,则需要在配置文件中开启。
那么下面就一个一个介绍这几个入口表。
1 ,setup_actors表

全部用户都可收集。
2,Setup_objects
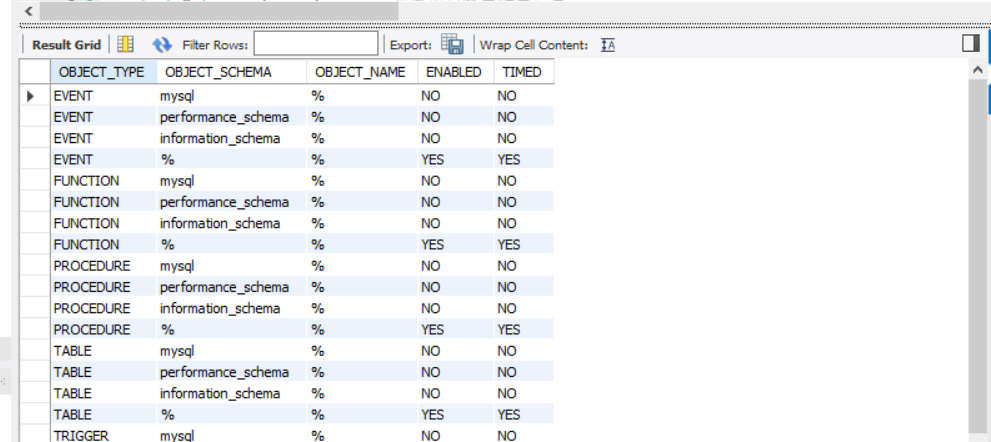
那些对象可以收集,是table还是trigger等。至于关闭两个列控制,enabled和timed字段设置为No,这几个表都是如此。
3 setup_consumers

事件的分类,stages是步骤,一个语句在服务器执行的过程步骤,结果和profile一样,profile方式不推荐,因为后面会去掉。transaction是事务的事件收集等。
4 setup_instruments
这个就是主要的事件监控仪器,如下:
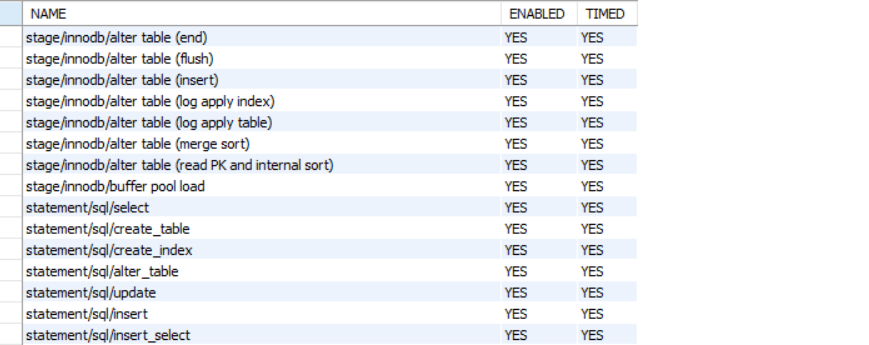
5 最后就是setup_timers,配合performance_timers定义那些仪器分类是的时间类型,如下:
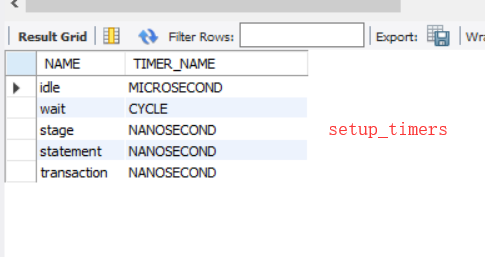
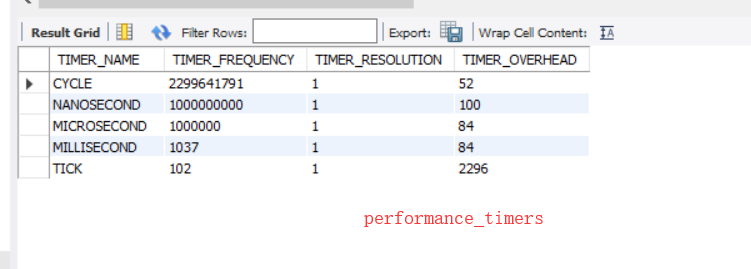
CYCLE:cpu时钟,TIMER_FREQUENCY是一秒有多少,TIMER_RESOLUTION是每次增加多少,最后是多久获取一次这个时间。
三 利用performance_schema获取priofile数据
开启相关的instrument:
我们看上面 instrument分类表setup_consumers中的信息,关于stage的行都是NO,那么我们需要改为YES,同时一会需要拿statements监控表中的信息,所以也需要开启statements:
UPDATE setup_consumers SET ENABLED = 'YES'
WHERE NAME LIKE '%stage%';
UPDATE setup_consumers SET ENABLED = 'YES'
WHERE NAME LIKE '%statements%';
然后把stage的instrument开启
UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES'
WHERE NAME LIKE '%stage/%'; -- 开启所有执行步骤的监控
UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES'
WHERE NAME LIKE '%statement/%';
执行依据sql
select * from quartz.TestOne
查询这条语句的queryid:
SELECT EVENT_ID, TRUNCATE(TIMER_WAIT/1000000000000,6) as Duration, SQL_TEXT
FROM performance_schema.events_statements_history_long WHERE SQL_TEXT like '%quartz%';
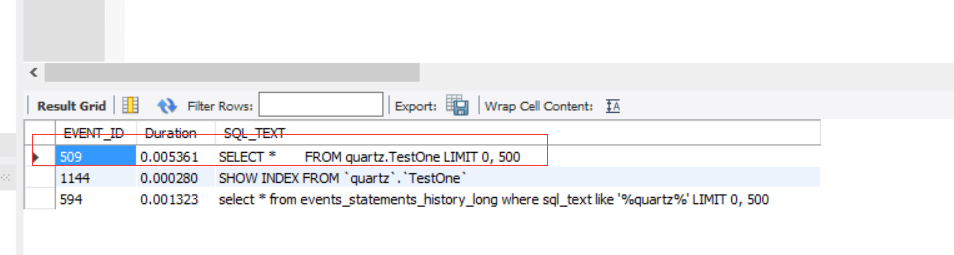
那么id就是509
然后执行性能监控表:
SELECT event_name AS Stage, TRUNCATE(TIMER_WAIT/1000000000000,6) AS Duration
FROM performance_schema.events_stages_history_long WHERE NESTING_EVENT_ID=509
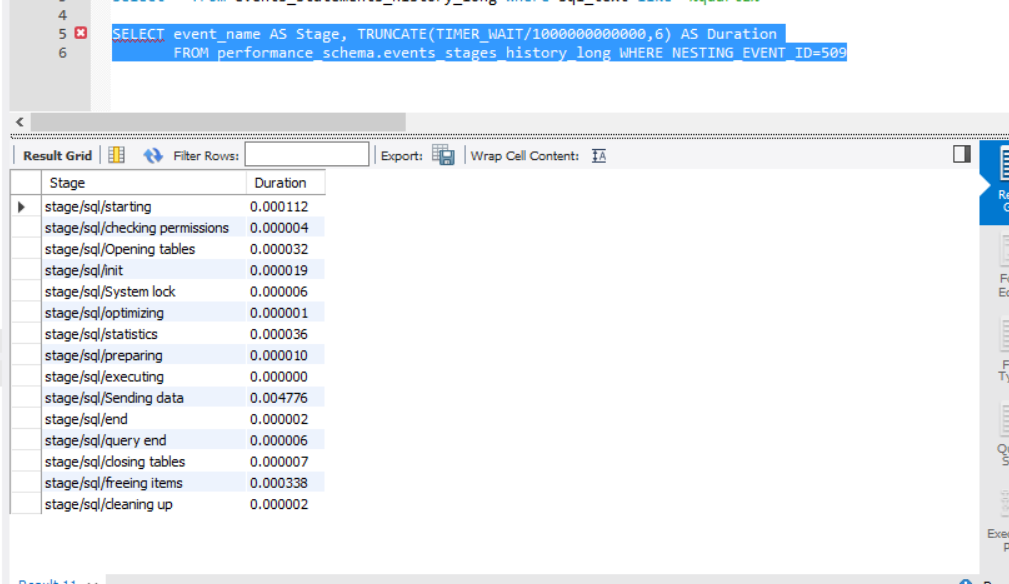
内容和老版本的profile结果一样。
主要看下stage/sql/Sending data这一行,这一行是主要io相关的事件,一般情况下,sql慢了,而这一行数值比较大,那肯定硬盘读数据慢了或者有锁冲突。
那么就是用error log,有死锁,mysql会将死锁信息打入error日志,show engine innodb status只是全局的一些信息,如果要想看详细的再去监控对应的instrument。
而且目前mysql8多支持NOWAIT和skiplocked两个语句,用法还是select.. from 表明 for update/for nowait等,非常灵活的解决了死锁的处理方式,当然你也可以让其事务隔离级别为脏读级别
,但是并不能解决更多的业务类型,设置死锁超时也是一个可行的办法。
mysql之调优概论的更多相关文章
- mysql技术调优资料整理
1,15 个有用的 MySQL/MariaDB 性能调整和优化技巧 2,MariaDB设置主从复制 3,CentOS6.4安装mysql2redis http://www.cnblogs ...
- MySQL性能调优——锁定机制与锁优化分析
针对多线程的并发访问,任何一个数据库都有其锁定机制,它的优劣直接关系着数据的一致完整性与数据库系统的高并发处理性能.锁定机制也因此成了各种数据库的核心技术之一.不同数据库存储引擎的锁定机制是不同的,本 ...
- MySQL性能优化总结___本文乃《MySQL性能调优与架构设计》读书笔记!
一.MySQL的主要适用场景 1.Web网站系统 2.日志记录系统 3.数据仓库系统 4.嵌入式系统 二.MySQL架构图: 三.MySQL存储引擎概述 1)MyISAM存储引擎 MyISAM存储引擎 ...
- MySQL 性能调优之存储引擎
原文:http://bbs.landingbj.com/t-0-246222-1.html http://bbs.landingbj.com/t-0-245851-1.html MySQ ...
- MySQL性能调优的10个方法 - mysql数据库栏目
摘要: https://edu.aliyun.com/a/29036?spm=5176.11182482.related_article.1.hbeZbF 摘要: MYSQL 应该是最流行了 WEB ...
- MySql(十一):MySQL性能调优——常用存储引擎优化
一.前言 MySQL 提供的非常丰富的存储引擎种类供大家选择,有多种选择固然是好事,但是需要我们理解掌握的知识也会增加很多.本章将介绍最为常用的两种存储引擎进行针对性的优化建议. 二.MyISAM存储 ...
- MySQL性能调优与架构设计——第 18 章 高可用设计之 MySQL 监控
第 18 章 高可用设计之 MySQL 监控 前言: 一个经过高可用可扩展设计的 MySQL 数据库集群,如果没有一个足够精细足够强大的监控系统,同样可能会让之前在高可用设计方面所做的努力功亏一篑.一 ...
- MySQL性能调优与架构设计——第 17 章 高可用设计之思路及方案
第 17 章 高可用设计之思路及方案 前言: 数据库系统是一个应用系统的核心部分,要想系统整体可用性得到保证,数据库系统就不能出现任何问题.对于一个企业级的系统来说,数据库系统的可用性尤为重要.数据库 ...
- MySQL性能调优与架构设计——第 16 章 MySQL Cluster
第 16 章 MySQL Cluster 前言: MySQL Cluster 是一个基于 NDB Cluster 存储引擎的完整的分布式数据库系统.不仅仅具有高可用性,而且可以自动切分数据,冗余数据等 ...
随机推荐
- python语言的jenkinapi
# coding:utf-8 from jenkinsapi.jenkins import Jenkins # 实例化Jenkins对象,传入地址+账号+密码 j = Jenkins("ht ...
- base64编码问题
最近遇到一个很奇怪的问题:post方式上传文件,因为文件不大,所以直接base64后作为参数扔给服务器.一开始好用,后来出问题了,上传的压缩包再下载后,能双击打开看到压缩包里面的文件,但是解压就报错, ...
- pageadmin CMS Sql新建数据库和用户名教程
用pageadmin网站制作如何Sql新建数据库和用户名 sql server软件安装完毕后,需要新建一个数据库用来作为网站的数据库. 1.打开sql管理界面,如图所示,找到数据库,右键单击数据库,选 ...
- [HNOI2004]宠物收养所
题目链接:戳我 其实也就是一个splay而已了. 但是一定要注意这种需要计算的,刚开始insert的时候插入极大值极小值的时候不要让它爆掉int.......(比如我刚开始就写了一个214748364 ...
- [USACO09FEB] 改造路Revamping Trails | [JLOI2011] 飞行路线
题目链接: 改造路 飞行路线 其实这两道题基本上是一样的,就是分层图的套路题. 为什么是分层图呢?首先,我们的选择次数比较少,可以把这几层的图建出来而不会爆空间.然后因为选择一个边权为0的路线之后我们 ...
- leetcode 45. 跳跃游戏 II JAVA
题目: 给定一个非负整数数组,你最初位于数组的第一个位置. 数组中的每个元素代表你在该位置可以跳跃的最大长度. 你的目标是使用最少的跳跃次数到达数组的最后一个位置. 示例: 输入: [2,3,1,1, ...
- 爬虫开发5.requests模块的cookie和代理操作
代理和cookie操作 一.基于requests模块的cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests ...
- 事件委托,元素节点操作,todolist计划列表实例
一. 事件委托 事件委托就是利用冒泡的原理,把事件加到父级上,来代替子集执行相应的操作,事件委托首先可以极大减少事件绑定次数,提高性能:其次可以让新加入的子元素也可以拥有相同的操作. 比如有20个&l ...
- UItextfield各个通知和回调的顺序
成为第一响应者之前,调用delegate的textFieldShouldBeginEditing(_:)方法 成为第一响应者 发送通知UIKeyboardWillShow和UIKeyboardDidS ...
- macdown快速上手
1.断句 在结尾处输入两个空格并使用回车. 2.标题分级 使用#来进行分级,#越多级数越低 3.链接 可以使用<>里面直接加上地址 或者使用[}里面加上链接名字然后后面接上()里面就是地址 ...