kafka rebalance你真的了解吗
介绍
今天主要分享一下 kafka 的 rebalance,在 kafka 中,rebalance 是一个十分重要的概念,很多时候引发的一些问题可能都是由于 rebalance 引起的,rebalance 也就是再均衡,顾名思义,再均衡就是再次负载均衡,下面会对再均衡进行一个详细的描述。
负载均衡
说再均衡之前,先说一说负载均衡,负载均衡就是将请求分发到不同的操作单元上,我们通俗一点来说,就是将请求分发到不同的服务器上,以减轻单台服务器的压力,提高吞吐量,负载均衡的方式有很多,下面是 nginx 的负载均衡,当客户端请求到 nginx 时,nginx 根据一定的负载均衡算法将请求转发到不同的服务器。
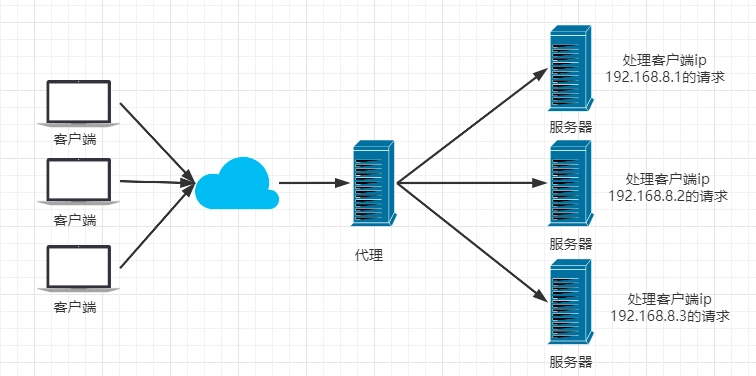
请求应该落到那一台机器上,这取决于我们使用的负载均衡策略,负载均衡策略有很多,比如随机,轮询,LFU,LRU 等等,这取决于我们的选择。
rebalance图示
上面说了负载均衡,其实再均衡也是一样,再 kafka 中,一个消费者群组怎么去消费一个主题下面的分区,该以什么方式去消费这些分区,是我们值得去考虑的,kafka 提供了一个分区分配器,他能协调哪些消费者应该去消费那些分区。
如下图所示,一个消费者群组中有两个消费者,他们各自消费两个分区。
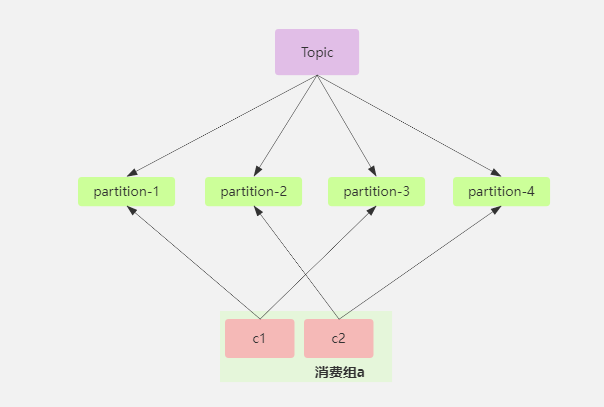
此时加入一个消费者,那么就触发了再均衡操作,kafka 就会重新进行分配,分配后的样子可能是下面的这样,c2 从原来的消费两个分区 partition-3,partition-4 变为只消费 partition-2,partition-4 让 c3 去消费。
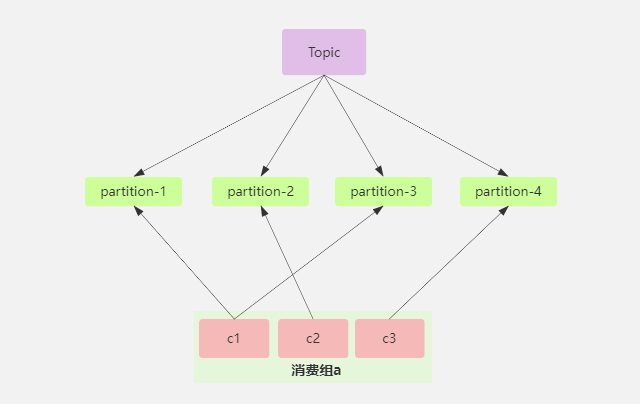
从上面我们看出,kafka 的再均衡其实就是协调消费者和分区的消费对应关系,我们一般是希望消费者和分区之间的消费关系尽量做到平衡,别出现某个消费者的负载很高,某个消费者的负载很低,资源不能进行合理的利用。
再均衡产生的条件
再均衡产生的条件就是有消费者加入或者退出,加入和退出的方式有很多,有一些是主动因素,有一些是被动因素,比如我们主动增加一个消费者,这时候就会发生再均衡,我们停掉一个消费者,那么这时候也发生再均衡,还有当消费者和 broker 之间由于长时间没有心跳,那么消费者就被提出,这时候也会发生再均衡,某个主题下的分区数量发生变化,也会发生再均衡,还有其他的一些因素,就不展开了,不过我们应该尽量避免再均衡。
再均衡期间消费者是读取不了任何消息,因为这段时间会对分区进行重新分配,所以
之前消费者与分区之间的对应关系已经不存在,需要进行重新分配,所以会出现短暂不可用现象。
主动因素导致消费者的加入和离开是无法避免的,当数据量比较大时,可能需要增加消费者来分担压力,提高吞吐量,所以这时候就需要人为去添加消费者了,这时候发生再均衡是可预见的,但是被动导致再均衡就不可预见了,下面我们从一些参数和原理来说明一下,尽量避免再均衡。
相关参数
在 kafka 中,分区的分配和分区分配器PartitionAssignor有关,在底层实现中,是通过协调器Coordinator来协调消费者和分区的,分为消费者端的消费者协调器ConsumerCoordinator和 Broker 端的组协调器GroupCoordinator。
Broker 端参数
group.max.session.timeout.ms:消费者会话的最大超时时间。如果消费者在这个时间内没有发送心跳 GroupCoordinator,那么它会被认为已经失效,会被踢出消费组。
group.min.session.timeout.ms:消费者会话的最小超时时间。如果消费者在这个时间内没有发送心跳 GroupCoordinator,那么它会被认为已经失效,会被踢出消费组。
group.initial.rebalance.delay.ms:消费者组启动时,等待多长时间再进行 rebalance。这个参数可以让消费者有时间加入消费者组。
consumer 端参数
session.timeout.ms:消费者会话的超时时间。如果一个消费者在这个时间内没有发送心跳到组协调器 GroupCoordinator,那么被认为它已经失效了,就会将其踢出消费者组。如果这个值设置过小,那么就会比较消耗资源,但是能够快速的发现 ConsumerCoordinator 是否还“存活”,然后进行 rebalance,如果设置过大,那么就会导致长时间没有收到心跳,可能 ConsumerCoordinator 已经“挂了”一段时间,没有及时进行 rebalance。
heartbeat.interval.ms:消费者发送心跳的时间间隔。心跳是消费者与 GroupCoordinator 之间维持会话的机制,如果一个消费者在这个时间间隔内没有发送心跳,那么 GroupCoordinator 认为它已经失效,然后将其踢出,如果这个值设置过大,那么一个消费者失效时,可能需要等待很长时间才能触发 rebalance,如果过小那么就会比较消耗资源。
max.poll.interval.ms:消费者处理消息的最大时间间隔。如果消费者在这个时间内没有消费完消息导致不能 poll 消息,那么它将被认为已经失效,将被踢出消费者组,这个值默认为 5 分钟。
heartbeat.interval.ms 的值一定要比 session.timeout.ms 小,官网建议是 1/3,比如 heartbeat.interval.ms 为 5s,那么 session.timeout.ms 为 15s,这样的话在这个时间会话内能收到三次心跳,不过这两个的值也要在 Broker 端 group.max.session.timeout.ms(5min)和 group.min.session.timeout.ms(6s)的区间之间。
分配器
消费者和分区之间进行分配是由分配器来完成的,当消费者加入和离开时触发 reabalance,然后会使用分配器从新对分区和消费者进行分配,kafka 有一个分配器接口ConsumerPartitionAssignor,它的下面有一个抽象类AbstractPartitionAssignor,如果我们需要自定义分配器,那么集成抽象类AbstractPartitionAssignor即可,kafka 默认提供了好几种分配器,如 RoundRobinAssignor,RangeAssignor,StickyAssignor,CooperativeStickyAssignor,kafka 默认使用 RangeAssignor。
如下,我创建了一个名称为 musk 的主题,分区数为 4,然后创建一个消费者,那么这时因为只有一个消费者,所以四个分区都划给了它。
此时我又加入一个消费者,因为加入消费者后会触发 rebalance,所以这时候就会对分区重新进行分配,分配后如下,每个消费者划分了两个分区。
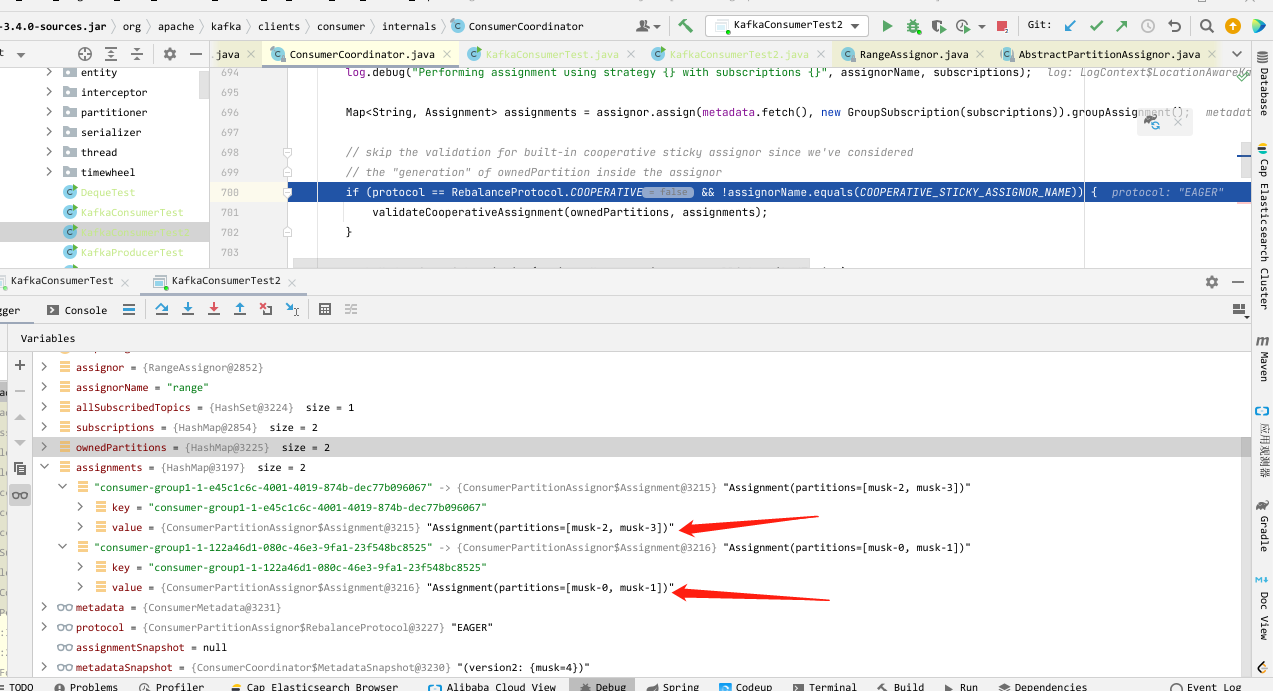
对于分配器,kafka 自带的已经能够满足我们大多时候的需求,因为我们在使用多个消费者的时候,其实就是为了让分区被均分给消费组内的消费者,以达到压力的分担。
总结
从上面我们对 rebalance 进行一些介绍,对 rebalance 产生的原因进行说明,对消费者协调器和组协调器进行了解,对一些参数进行详解,还有通过测试 rebalance 来更加直观说明 rebalance,rebalance 的触发有很多方式,不过我们应该尽量去避免它的发生,对于分区的修改,应该尽量在一开始规划好,不要后续去修改分区,对于其他引起 rebalance 的因素,也应该将其概率降到最低。
今天的分享就到这里,感谢你的观看,我们下期见,如果文中有说得不合理或者不正确的地方,希望你能进行指点

kafka rebalance你真的了解吗的更多相关文章
- kafka rebalance解决方案 -incremental cooperative协议和static membership功能
apache kafka的重平衡(rebalance),一直以来都为人诟病.因为重平衡过程会触发stop-the-world(STW),此时对应topic的资源都会处于不可用的状态.小规模的集群还好, ...
- 什么是 Kafka Rebalance 以及关于 Rebalance Kafka-Python 社区客户端应该关注的地方
什么是 Rebalance? Rebalance 为什么会发生?Rebalance 的情况下 consumer 是否还能正确消费消息呢? 记得之前在一段时间密集面试的时候总会问候选人这些问题. 重平衡 ...
- kafka rebalance 部分分区没有owner
转发请注明原创地址http://www.cnblogs.com/dongxiao-yang/p/6234673.html 最近业务同学反馈kafka上线的时候某个topic的部分分区一直没有owner ...
- Kafka Rebalance机制分析
什么是 Rebalance Rebalance 本质上是一种协议,规定了一个 Consumer Group 下的所有 consumer 如何达成一致,来分配订阅 Topic 的每个分区. 例如:某 G ...
- Kafka Rebalance机制和选举策略总结
自建博客地址:https://www.bytelife.net,欢迎访问! 本文为博客同步发表文章,为了更好的阅读体验,建议您移步至我的博客 本文作者: Jeffrey 本文链接: https://w ...
- Kafka 的这些原理你知道吗
如果只是为了开发 Kafka 应用程序,或者只是在生产环境使用 Kafka,那么了解 Kafka 的内部工作原理不是必须的.不过,了解 Kafka 的内部工作原理有助于理解 Kafka 的行为,也利用 ...
- Kafka 【的这些原理你知道吗】
如果只是为了开发 Kafka 应用程序,或者只是在生产环境使用 Kafka,那么了解 Kafka 的内部工作原理不是必须的.不过,了解 Kafka 的内部工作原理有助于理解 Kafka 的行为,也利用 ...
- Kafka 的这些原理你懂吗
如果只是为了开发 Kafka 应用程序,或者只是在生产环境使用 Kafka,那么了解 Kafka 的内部工作原理不是必须的.不过,了解 Kafka 的内部工作原理有助于理解 Kafka 的行为,也利用 ...
- Kafka基本原理
简介 Apache Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成为Apache项目的一部分.Kafka是一种快速.可扩展的.设计内在就是分布式的,分区的和可复制的提交 ...
- Storm 对 0.10.x 版 Kafka之commit offsets
由于 0.10.x 版 Kafka 与 0.8.x 版有很大的变化,这种变化对下游 Storm 有非常大的影响,0.10.x 版的 Kafka 不但增加了权限管理的功能,而且还将 simple 和 h ...
随机推荐
- Git系列 -> 如何获取远程库某个文件
有时候远程库存放很多文件夹,我们可能只需要下载或获取某个文件中的内容,可以采用以下: 首先点击clone 按钮,然后复制clone URL , 如果想要下载其中的某个文件夹的内容,需要在后面加入指定文 ...
- Git 提交(commit)没有自动生成Change-Id导致无法push
1). 检查仓储 .git/hook 下面是否有 commit-msg 文件,如果没有可以到下面的地址下载,或者把其他同事的commit-msg文件拷贝到你的.git/hook重新commit即可. ...
- vue实现按钮多选
需求是这样: 首先考虑使用elementui中的组建实现,但是有时候会忽略组建.实现方式两种: 1.直接使用element实现 let weekTimeData: [ '星期一', '星期二', '星 ...
- java pta第三次阶段性总结
一.前言 这是这学期最后一次总结,这三次的pta大作业也是最后一次,这几次大作业主要写了电信计费系统的主要功能,第一次大作业是座机计费功能,第二次大作业是手机计费功能,第三次大作业是短信计费的功能.这 ...
- mysql查询mapper返参类型为List
List<String> lists = mapper.select(); 返参类型为List,查询没有数据的时候,lists不会为null,lists.size() 为 0.
- 初步学习UE网络同步
UE 网络同步和框架介绍 为一个UE引擎的初学者基于现有知识储备和见识的限制下,对UE网络和游戏框架的粗鄙之见,文中多有错误敬请指出以较后文. 1.网络复制 不论是服务端还是客户端,代码都是一样的 ...
- java图形化界面编程(AWT)
1.AWT编程简介 在JDK发布时,sun公司提供了一套基本的GUI类库,这个GUI类库希望可以在所有平台下都能运行,这套基本类库被称为"抽象窗口工具集",它为java应用程序提供 ...
- 自学JavaDay01
1.Java的特性和优势 简单性 面向对象 可移植性 高性能 分布式 动态性 多线程 安全性 健壮性 2.Java三大版本 JavaSE:标准版(桌面程序,控制台开发......) JavaME:嵌入 ...
- CentOS7 yum方式安装mysql 5.7
1.检查服务器上有没有安装mysqlyum安装方式:yum list installed mysql*yum卸载 yum remove 已安装的包卸载完安装包后,删除安装文件rm -rf /var/l ...
- django_模板层的变量和标签
一.模板层的变量 1.能传递到模板层的数据类型:str(字符串).list(数组).dict(字典).obj(类实例化的对象).fun(函数)等. 2.在模板中使用变量的方法: (1)字符串:{{ 变 ...