记一次线上频繁fullGc的排查解决过程
发生背景
最近上线的一个项目几乎全是查询业务,并且都是大表的慢查询,sql优化是做了一轮又一轮,前几天用户反馈页面加载过慢还时不时的会timeout,但是我们把对应的sql都优化一遍过后,前台响应还是很慢,数据库测试sql运行时间在3s以内但响应的时候要么500要么就超时了,这时猜测可能是服务器出了问题,于是让运维监测了下GC情况,结果令人吃惊,近15小时发生了237次FGC,每次耗时近4000秒;于是我就让他把内存快照dump给我了
通过MAT分析内存快照
常用名词介绍
- Leak Suspects
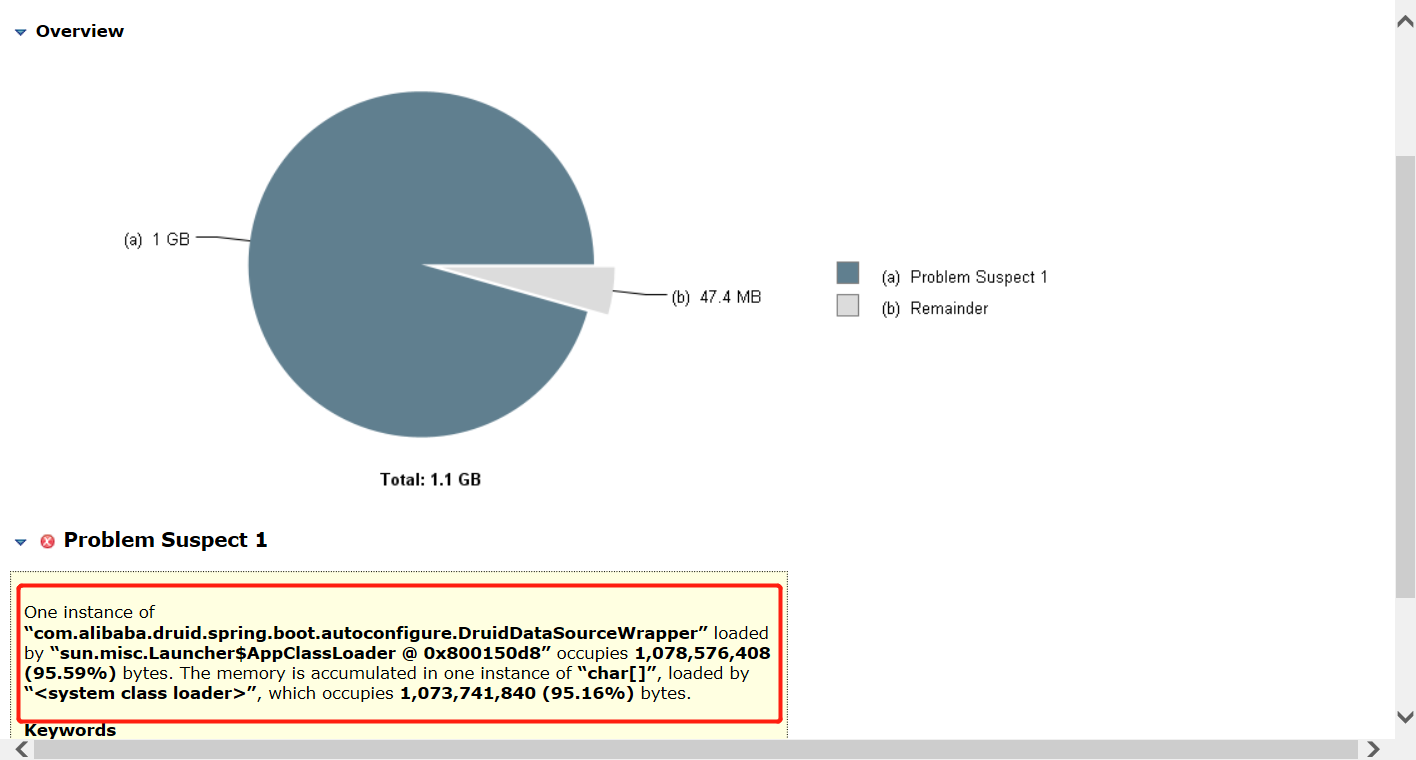
相当于一个总览,通过饼图的方式展示了可能造成内存溢出或泄露的对象使用的内存大小,并且会分析是哪个类加载器加载的哪个类占用了多少字节;如图:
- Dominator Tree
列出了对象与其自身的引用关系,并且倒序列出了对象占用的内存大小以及百分比;通过这些能很清晰的定位到占用内存的对象 - shallow heap
浅堆;对象没有引用其他对象时自身的大小 - retained heap
深堆;对象自身的大小加其引用对象的大小,即对象被回收时垃圾回收器能回收到的内存大小
快照分析
通过Leak Suspects分析得出占用内存最大的是DruidDataSourceWrapper实例,这是连接池的类竟然不是业务代码,然后通过Dominator Tree 观察到底是哪个对象占用的内存较大,如图:

发现竟然是软引用占用了大量内存空间,此时瞄了一眼DruidDataSourceWrapper的源码就短短数行并没有什么可能造成溢出的因素,奈何又没看过mybatis和连接池的源码,只能结合这个软引用猜测,软引用一般被用在缓存的场景,而我们每次查询的结果集都是5w以上的数据量,直接放内存就算会OOM的话应该也不会用到缓存,于是猜测mybatis的xml里是否用到了fetchSize,全局搜索果然发现了有使用fetchSize,值竟然是一万,于是将fetchSize改为500发布后问题解决
记一次印象深刻的SQL优化
上面也提到了,这次问题排查对很多查询sql进行了优化,下面举个实例以作备忘;有一张六千多万的数据表T1,其共有45列数据,有a,b,c,d四个列涉及到查询,查询sql为:
select b,c,d,count(1) from T1 where a=123 group by b,c,d
优化时执行sql响应时间大概在20多秒左右,检查索引情况发现a、b、c、d均建立了普通索引,通过执行计划分析发现只命中了a的索引,于是考虑将b、c、d建立一个联合索引,但是查询速度依然不理想,于是考虑利用稀疏索引的原理来创建一个a、b、c、d的联合索引,结果发现查询结果直接0点几秒,全结果集扫描共4万多条记录也只用了五秒左右,优化完成
记一次线上频繁fullGc的排查解决过程的更多相关文章
- 关于GC(上):Apache的POI组件导致线上频繁FullGC问题排查及处理全过程
某线上应用在进行查询结果导出Excel时,大概率出现持续的FullGC.解决这个问题时,记录了一下整个的流程,也可以作为一般性的FullGC问题排查指导. 1. 生成dump文件 为了定位FullGC ...
- 记一次线上服务CPU 100%的处理过程
告警 正在开会,突然钉钉告警声响个不停,同时市场人员反馈客户在投诉系统登不进了,报504错误.查看钉钉上的告警信息,几台业务服务器节点全部报CPU超过告警阈值,达100%. 赶紧从会上下来,SSH登录 ...
- 记一次线上OOM问题分析与解决
一.问题情况 最近用户反映系统响应越来越慢,而且不是偶发性的慢.根据后台日志,可以看到系统已经有oom现象. 根据jdk自带的jconsole工具,可以监视到系统处于堵塞时期.cup占满,活动线程数持 ...
- 工作记录:记一次线上ZK掉线问题排查
目录 问题的发现 zk的情况以及分析 总结 问题的发现 最早问题的发现在于用户提的,用户提出他支付时支付失败,过了一会儿再试就好了,于是翻日志,查询到当时duboo调用出现了下类错误: [TraceI ...
- 日常工作问题解决:记一次centos7上的lvm表错误解决过程
问题描述: 公司大数据hadoop2服务器采用电信云服务器,后来故障,电信恢复该服务器,需要重新部署程序,需要扩展lvm分区,但是使用pvsan命令发现有报错信息,需要解决以防重启后,因挂载问题,无法 ...
- 解Bug之路-记一次线上请求偶尔变慢的排查
解Bug之路-记一次线上请求偶尔变慢的排查 前言 最近解决了个比较棘手的问题,由于排查过程挺有意思,于是就以此为素材写出了本篇文章. Bug现场 这是一个偶发的性能问题.在每天几百万比交易请求中,平均 ...
- 记一次线上bug排查-quartz线程调度相关
记一次线上bug排查,与各位共同探讨. 概述:使用quartz做的定时任务,正式生产环境有个任务延迟了1小时之久才触发.在这一小时里各种排查找不出问题,直到延迟时间结束了,该任务才珊珊触发.原因主要就 ...
- 再记一次w3wp占用CPU过高的解决过程(Dictionary和线程安全)
在此之前项目有发生过两次类似的状况,都得以解决,但最近又会发现偶尔CPU会跑满,虽然之前使用过WinDbg解决过两次问题但人的记忆是不可靠的,今天处理同样问题的时候还是遇到了一些障碍,这一次希望可以记 ...
- 记一次线上事故的JVM内存学习
今天线上的hadoop集群崩溃了,现象是namenode一直在GC,长时间无法正常服务.最后运维大神各种倒腾内存,GC稳定后,服务正常.虽说全程在打酱油,但是也跟着学习不少的东西. 第一个问题:为什么 ...
随机推荐
- 模拟赛:树和森林(lct.cpp) (树形DP,换根DP好题)
题面 题解 先解决第一个子问题吧,它才是难点 Subtask_1 我们可以先用一个简单的树形DP处理出每棵树内部的dis和,记为dp0[i], 然后再用一个换根的树形DP处理出每棵树内点 i 到树内每 ...
- python压缩pdf(指定缩放比例)
python压缩pdf(指定缩放比例) 原理 pdf文件处理使用https://pymupdf.readthedocs.io/en/latest/index.html库可以轻松实现,该库的官方说明文档 ...
- HBase 安装与配置及常用Shell命令
HBase 安装与配置 首要配置 配置时间同步(所有节点上执行) yum -y install chrony vi /etc/chrony.conf #写入(7版本用server:8版本用pool): ...
- clipboard实现文本复制的方法
1.下载地址: https://github.com/mo3408/clipboard 2.使用方法: 先引入js: <script src="dist/clipboard.min.j ...
- Kingbase V8R6存储过程变量数据导出到操作系统文件
Kingbase V8R6存储过程变量数据导出到操作系统文件 说明: KingbaseES V8R6如何将自定义过程中的变量数据导出到操作系统文件中. 本次案例数据库版本: test=# select ...
- Spring源码学习笔记12——总结篇,IOC,Bean的生命周期,三大扩展点
Spring源码学习笔记12--总结篇,IOC,Bean的生命周期,三大扩展点 参考了Spring 官网文档 https://docs.spring.io/spring-framework/docs/ ...
- 微服务系列之网关(二) konga配置操作
1.konga核心对象 Kong 的四大核心对象:upstream,target,service,route.下面分别说: (1)upstream,字面意思上游,实际项目理解是对某一个服务的一个或者多 ...
- JDK8中String的intern()方法详细解读【内存图解+多种例子+1.1w字长文】
写在前面,欢迎大家关注小编的微信公众号!!谢谢大家!! 一.前言 String字符串在我们日常开发中最常用的,当然还有他的两个兄弟StringBuilder和StringBuilder.他三个的区别也 ...
- 实践torch.fx第二篇-fx量化实操
好久不见各位,哈哈,又鸽了好久. 本文紧接上一篇<实践torch.fx第一篇--基于Pytorch的模型优化量化神器>继续说,主要讲如何利用FX进行模型量化. 为什么这篇文章拖了这么久,有 ...
- docker-compose安装harbor
目录 Harbor 安装环境说明 获取安装包(离线安装方式) 安装harbor 用docker-compose查看Harbor容器的运行状态 Harbor访问测试 上传镜像到Harbor服务器 Har ...