大规模人脸分类—allgather操作(2)
腾讯开源人脸识别训练代码TFace 中关于all_gather层的实现如下。接下来解释为什么backward要进行reduce相加操作。
https://github.com/Tencent/TFace
class AllGatherFunc(Function):
""" AllGather op with gradient backword
"""
@staticmethod
def forward(ctx, tensor, *gather_list):
gather_list = list(gather_list)
dist.all_gather(gather_list, tensor)
return tuple(gather_list)
@staticmethod
def backward(ctx, *grads):
grad_list = list(grads)
rank = dist.get_rank()
grad_out = grad_list[rank]
dist_ops = [
dist.reduce(grad_out, rank, ReduceOp.SUM, async_op=True) if i == rank else
dist.reduce(grad_list[i], i, ReduceOp.SUM, async_op=True) for i in range(dist.get_world_size())
]
for _op in dist_ops:
_op.wait()
grad_out *= len(grad_list) # cooperate with distributed loss function
return (grad_out, *[None for _ in range(len(grad_list))])
AllGather = AllGatherFunc.apply
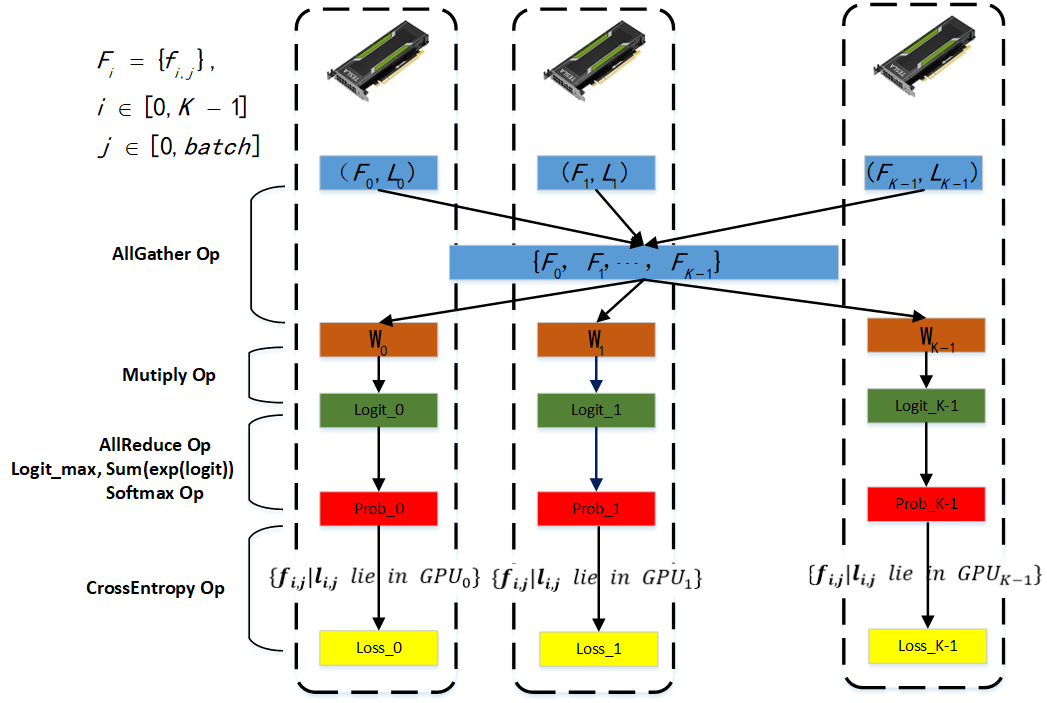
下面用示意图来描述大规模人脸分类的过程,如下图。
结合下面示意图和公式表达来理解。
B: batch size, d: feature dimension, K: gpu number, C: class number, \(c_j\): class number of j-th gpu
(1)\(F_j \in R^{B*d}\): 第j块GPU上特征
(2)\(F_{total} = torch.cat((F_0, F_1, ^, F_{K-1} )) \in R^{KB*d}\): 表示所有的K个GPU上特征合并在一起
(3)\(W_j \in R^{d*c_j}\):第j块GPU上的分类权重
(4)\(logit_j=F_{total}W_j \in R^{KB*c_j}\): 这里简化分类层为常规线性变换。(下面的公式中\(y_j\)就表示\(logit_j\))
\(\frac {\partial L_j}{\partial F_{total}} = \frac{\partial L_j}{\partial y_j}* \frac{\partial y_j}{\partial F_{total}}=\frac{\partial L_j}{\partial y_j}*W_j^T\),(\(R^{KB*c_j}*R^{c_j*d}=R^{KB*d}\),数据维度是可以对应上的)。
可以看出每块GPU上产生的对全体特征向量的梯度维度都是一样(这个是肯定的),每块GPU上产生梯度是通过上述链式法则得到的,得到梯度的公式中,分两个部分相乘,一个是对logit值的导数,一个是当前卡上局部分类权重W的导数。对于每块卡而言这两部分都不一样。也就是每块gpu都对全体特征向量\(F_{total}\)都产生梯度。总的loss是各个GPU上loss先求和再归约,因此在求对logit梯度时,也除以了总的样本数量(KB),然后对全体特征向量\(F_{total}\)在allgather层要进行相加。\(\frac{\partial L}{\partial F_{total}}=\frac{1}{KB}\sum _{j=0}^{j=K-1}\frac {\partial L_j}{\partial F_{total}} =\frac{1}{KB}\sum _{j=0}^{j=K-1}\frac{\partial L_j}{\partial y_j}*W_j^T=\sum _{j=0}^{j=K-1}\frac{1}{KB}\frac{\partial L_j}{\partial y_j}*W_j^T\)。
可是不明白上述代码为什么要乘以GPU的数量,对应代码为:grad_out *= len(grad_list) 。
大规模人脸分类—allgather操作(2)的更多相关文章
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
https://zhuanlan.zhihu.com/p/25928551 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文题目便是文本分类问题,趁此机会总结下文本分类 ...
- [转] 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
转自知乎上看到的一篇很棒的文章:用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文 ...
- 用keras的cnn做人脸分类
keras介绍 Keras是一个简约,高度模块化的神经网络库.采用Python / Theano开发. 使用Keras如果你需要一个深度学习库: 可以很容易和快速实现原型(通过总模块化,极简主义,和可 ...
- wordpress搜索结果排除某个分类如何操作
我们知道wordpress的搜索结果页search.php和分类页category.php是一样的,但是客户的网站是功能比较多的系统,有新闻又有产品,如果搜索结果只想展示产品要如何操作呢?随ytkah ...
- SQL分类-DDL_操作数据库_创建&查询
SQL分类 1.DDL(Data Definition Language)数据定义语言 用来定义数据库对象:数据库,表,列等.关键字:create , drop, alter 等 2.DML(Data ...
- python集合的分类与操作
如图: 集合的炒作分类: 确定大小 测试项的成员关系 遍历集合 获取一个字符串表示 测试相等性 连接两个集合 转换为另一种类型的集合 插入一项 删除一项 替换一项 访问或获取一项
- Python函数分类及操作
为什么使用函数? 答:函数的返回值可以确切知道整个函数执行的结果 函数的定义:1.数学意义的函数:两个变量:自变量x和因变量y,二者的关系 2.Pytho ...
- .NET做人脸识别并分类
.NET做人脸识别并分类 在游乐场.玻璃天桥.滑雪场等娱乐场所,经常能看到有摄影师在拍照片,令这些经营者发愁的一件事就是照片太多了,客户在成千上万张照片中找到自己可不是件容易的事.在一次游玩等活动或家 ...
- face recognition[翻译][深度学习理解人脸]
本文译自<Deep learning for understanding faces: Machines may be just as good, or better, than humans& ...
- face recognition[翻译][深度人脸识别:综述]
这里翻译下<Deep face recognition: a survey v4>. 1 引言 由于它的非侵入性和自然特征,人脸识别已经成为身份识别中重要的生物认证技术,也已经应用到许多领 ...
随机推荐
- PGSQL新建临时表
初始化临时表,会话结束后自动删除 普通写法 CREATE TEMP TABLE tmp_student( id VARCHAR(10), name VARCHAR(3O), age INTEGER ) ...
- RestTemplate 远程服务调用
* 使用 Eureka 和 Nacos 为注册中心时也能使用这种方式调用 一.远程调用类 bean 配置注入 和 配置负载均衡 注意,必须在可配置类中注入 bean,例如 SpringBoot 启动 ...
- 不需要鼠标交互的UI去掉RaycastTarget
UI事件会在EventSystem在Update的Process触发.UGUI会遍历屏幕中所有RaycastTarget是true的UI,接着就会发射线,并且排序找到玩家最先触发的那个UI,在抛出事件 ...
- JavaSE——遍历字符串与统计字符个数
package com.zhao.stringtest; import java.util.Scanner; public class test2 { //键盘录入一个字符串,统计该字符串中大写字母, ...
- 正则过滤http|https地址
let reg = /(\w+):\/\/([^/:]+)(:\d*)?/; let s = http.match(reg); let s1 = http1.match(reg); console.l ...
- 谷歌浏览器上elementUI的按钮文字消失了
解决方案:有个谷歌浏览器插件,好像是什么淘宝的,删掉即可
- JavaScript案例:倒计时
展示效果: 代码示例: <!DOCTYPE html> <html lang="en"> <head> <meta charset=&qu ...
- Power shell 读取电量,改变屏幕亮度
1. Get-Wmiobject -List win32* # 列出所有win32_信息(基本的BIOS,Battery , Memory, processor) 2.Get-WmiObject ...
- Linux 第八节(防火墙 )
-------------------iptables-------------------------- RHEL 5 6 7.0 7.1 iptable RHEL 8 firewall FORWA ...
- nohup--将程序放入后台执行
作用:可以将程序以忽略挂起信号的方式运行,常与&一起使用 语法: nohup Command [ Arg - ] [ & ] 将程序放到后台运行的方法: command & ...