虚假新闻检测(CADM)《Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversarial Domain Mixup》
论文信息
论文标题:Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversarial Domain Mixup
论文作者:Huimin Zeng, Zhenrui Yue, Ziyi Kou, Lanyu Shang, Yang Zhang, Dong Wang
论文来源:aRxiv 2022
论文地址:download
论文代码:download
1 Introduction
2 Problem Statement
Regarding misinformation detection, we aim at training a model $f$ , which takes an input text $\boldsymbol{x}$ (a COVID-19 claim or a piece of news) to predict whether the information contained in $\boldsymbol{x}$ is valid or not (i.e., a binary classification task). Moreover, in our domain adaptation problem, we use $\mathcal{P}$ to denote source domain data distribution and $\mathcal{Q}$ for the target domain data distribution. Each data point ($\boldsymbol{x}$, $y$) contains an input segment of COVID-19 claim or news ($\boldsymbol{x}$) and a label $y \in\{0,1\}$ ( $y=1$ for true information and $y=0$ for false information). To differentiate the notations of the data sampled from the source distribution $\mathcal{P}$ and the target distribution $\mathcal{Q}$ , we further introduce two definitions of the domain data:
- Source domain: The subscript $s$ is used to denote the source domain data: $\mathcal{X}_{s}=\left\{\left(\boldsymbol{x}_{s}, y_{s}\right) \mid\left(\boldsymbol{x}_{s}, y_{s}\right) \sim \mathcal{P}\right\}$ .
- Target domain: Similarly, the subscript t is used to denote the target domain data: $\mathcal{X}_{t}=\left\{\boldsymbol{x}_{t} \mid \boldsymbol{x}_{t} \sim \mathcal{P}\right\}$ . Note that in our unsupervised setting, the ground truth labels of target domain data $y_{t}$ are not used during training.
Our goal is to adapt a classifier $f$ trained on $\mathcal{P}$ to $\mathcal{Q}$ . For a given target domain input $\boldsymbol{x}_{t}$ , a well-adapted model aims at making predictions as correctly as possible.
3 Method
整体框架:
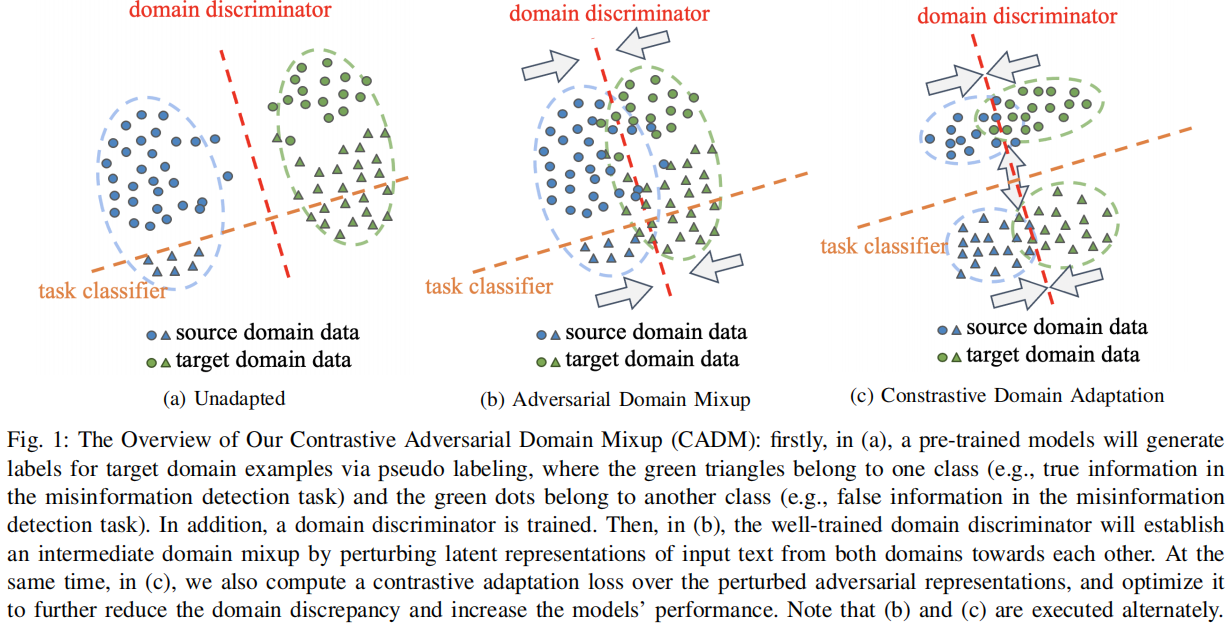
3.1 Domain Discriminator
第一步是训练一个域鉴别器 $f_{D}$ 来分类输入数据是属于源域还是属于目标域。该域鉴别器与 COVID 模型共享相同的 BERT Encoder $f_{e}$,并具有不同的二进制分类模块 $f_{D}$。域鉴别器以 BERT Encoder 中的标记 [CLS] 表示作为输入,以预测输入数据的域,如所示:
$\hat{y}=f_{D}(\boldsymbol{z}) \quad\quad(1)$
其中,$z$ 是 token [CLS] 的表示。
对于 $f_{D}$ 的训练,明确地将源域数据的域标签 $y_{D}$ 定义为 $y_{D}=0$,将目标域数据的域标签定义为 $y_{D}=1$。因此,对域鉴别器的训练可以表述为:
$\underset{f_{D}}{\text{min}} \;\; \mathbb{E}_{\left(\boldsymbol{x}, y_{D}\right) \sim \mathcal{X}^{\prime}}\left[l\left(f_{D}\left(f_{e}(\boldsymbol{x})\right), y_{D}\right)\right] \quad\quad(2)$
其中,$\mathcal{X}^{\prime}$ 表示带有域标签的源域和目标域训练数据的合并数据集。
3.2 Adversarial Domain Mixup
在训练了域鉴别器后,我们提出直接干扰来自源域和目标域的输入数据的潜在表示到域鉴别器的决策边界,如 Figure 1b 所示。为此,来自两个域的扰动表示(即域对抗表示)可以变得更接近,表明域间隙减小。在此,从两个域生成的域对抗性表示在模型的潜在特征空间中形成了一个平滑的中间域混合。在数学上,通过求解一个优化问题,可以找到干扰训练样本 $ \boldsymbol{x}$ 的潜在表示 $ \boldsymbol{z}$ 的最优扰动 $\delta^{*}$:
$\begin{array}{r}\mathcal{A}\left(f_{e}, f_{D}, \boldsymbol{x}, y_{D}, \epsilon\right)=\underset{\boldsymbol{\delta}}{\text{max}} \left[l\left(f_{D}(\boldsymbol{z}+\boldsymbol{\delta}), y_{D}\right)\right] \\\text { s.t. } \quad\|\boldsymbol{\delta}\| \leq \epsilon, \quad \boldsymbol{z}=f_{e}(\boldsymbol{x})\end{array}\quad\quad(3)$
注意,在上面的方程中,我们引入了一个超参数 $\epsilon$ 来约束扰动 $\delta$ 的范数,从而避免了无穷大解。最后,将 $\text{Eq.3}$ 应用于合并训练集 $\mathcal{X}^{\prime}$ 中的所有训练样本,得到对抗域混合 $\mathcal{Z}^{\prime}$:
$\begin{aligned}\mathcal{Z}^{\prime} & =\left\{\boldsymbol{z}^{\prime} \mid \boldsymbol{z}^{\prime}=\boldsymbol{z}+\mathcal{A}\left(f_{e}, f_{D}, \boldsymbol{x}, y_{D}, \epsilon\right),\left(\boldsymbol{x}, y_{D}\right) \in \mathcal{X}^{\prime}\right\} \\& :=\mathcal{Z}_{s}^{\prime} \cup \mathcal{Z}_{t}^{\prime}\end{aligned}\quad\quad(4)$
其中,$\mathcal{Z}_{s}^{\prime}$ 是扰动的源特性,$\mathcal{Z}_{t}^{\prime}$ 是受干扰的目标特征。我们使用投影梯度下降(PGD)来近似 $\text{Eq.3}$ 的解,如在[7],[8]。
3.3 Contrastive Domain Adaptation
接下来,受[6]的启发,我们提出了 $\mathcal{Z}_{a d v}$ 的双重对比自适应损失,以进一步将源数据域的知识适应到目标数据域。首先,我们减少了类内表示之间的域差异。也就是说,如果一个表示从源数据域的标签是真(或假)和一个表示从目标数据域的伪标签是真(或假),那么这两个表示被视为类内表示,我们减少域之间的差异。其次,如 Figure 1c 所示,真实信息和虚假信息的表示之间的差异将被扩大。
为了计算我们提出的对比自适应损失,我们建议使用径向基函数(RBF)来度量标记类之间的差异。在[11]中,RBF 被证明是量化深度神经网络中不确定性的有效工具。由于我们的伪标记过程是为了自动过滤出目标域数据的低置信度标签,因此使用RBF来衡量标记类之间的差异可以有效地提高伪标签的质量,最终有助于模型的域适应。
在形式上,使用 RBF 内核的定义:$k\left(z_{1}, z_{2}\right)=\exp \left[-\frac{\left\|\boldsymbol{z}_{1}-\boldsymbol{z}_{2}\right\|^{2}}{2 \sigma^{2}}\right]$
我们定义了错误信息检测任务的类感知损失如下:
$\begin{aligned}\mathcal{L}_{\text {con }}\left(\mathcal{Z}^{\prime}\right) =&-\sum_{i=1}^{\left|\mathcal{Z}_{s}^{\prime}\right|} \sum_{j=1}^{\left|\mathcal{Z}_{t}^{\prime}\right|} \frac{\mathbb{1}\left(y_{s}^{(i)}=0, \hat{y}_{t}^{(j)}=0\right) k\left(\boldsymbol{z}_{s}^{(i)}, \boldsymbol{z}_{t}^{(j)}\right)}{\sum_{l=1}^{\left|\mathcal{Z}_{s}^{\prime}\right|} \sum_{m=1}^{\left|\mathcal{Z}_{t}^{\prime}\right|} \mathbb{1}\left(y_{s}^{(l)}=0, \hat{y}_{t}^{(m)}=0\right)} \\& -\sum_{i=1}^{\left|\mathcal{Z}_{s}^{\prime}\right|} \sum_{j=1}^{\left|\mathcal{Z}_{t}^{\prime}\right|} \frac{\mathbb{1}\left(y_{s}^{(i)}=1, \hat{y}_{t}^{(j)}=1\right) k\left(\boldsymbol{z}_{s}^{(i)}, \boldsymbol{z}_{t}^{(j)}\right)}{\sum_{l=1}^{\left|\mathcal{Z}_{s}^{\prime}\right|} \sum_{m=1}^{\left|\mathcal{Z}_{t}^{\prime}\right|} \mathbb{1}\left(y_{s}^{(l)}=1, \hat{y}_{t}^{(m)}=1\right)} \\& +\sum_{i=1}^{\left|\mathcal{Z}_{s}^{\prime}\right|} \sum_{j=1}^{\left|\mathcal{Z}_{s}^{\prime}\right|} \frac{\mathbb{1}\left(y_{s}^{(i)}=1, y_{s}^{(j)}=0\right) k\left(\boldsymbol{z}_{s}^{(i)}, \boldsymbol{z}_{s}^{(j)}\right)}{\sum_{l=1}^{\left|\mathcal{Z}_{s}^{\prime}\right|} \sum_{m=1}^{\left|\mathcal{Z}_{s}^{\prime}\right|} \mathbb{1}\left(y_{s}^{(l)}=1, y_{s}^{(m)}=0\right)} \\& +\sum_{i=1}^{\left|\mathcal{Z}_{t}^{\prime}\right|} \sum_{j=1}^{\left|\mathcal{Z}_{t}^{\prime}\right|} \frac{\mathbb{1}\left(\hat{y}_{t}^{(i)}=1, \hat{y}_{t}^{(j)}=0\right) k\left(\boldsymbol{z}_{t}^{(i)}, \boldsymbol{z}_{t}^{(j)}\right)}{\sum_{l=1}^{\left|\mathcal{Z}_{t}^{\prime}\right|} \sum_{m=1}^{\left|\mathcal{Z}_{t}^{\prime}\right|} \mathbb{1}\left(\hat{y}_{t}^{(l)}=1, \hat{y}_{t}^{(m)}=0\right)}\end{aligned}\quad\quad(5)$
其中,$\hat{y}_{t}$ 为目标域样本的伪标签,$z$ 表示标记 CLS 的表示。
3.4 Overall Contrastive Adaptation Loss
现在,我们将任务分类问题的交叉熵损失和上述对比自适应损失合并为 COVID 模型的单一优化目标:
$\mathcal{L}_{\text {all }}=\mathcal{L}_{c e}(\boldsymbol{\mathcal { X }})+\lambda \mathcal{L}_{\text {con }}\left(\mathcal{Z}^{\prime}\right) \quad\quad(6)$
其中,$\mathcal{L}_{c e}$ 代表交叉熵损失函数。
4 Experiment
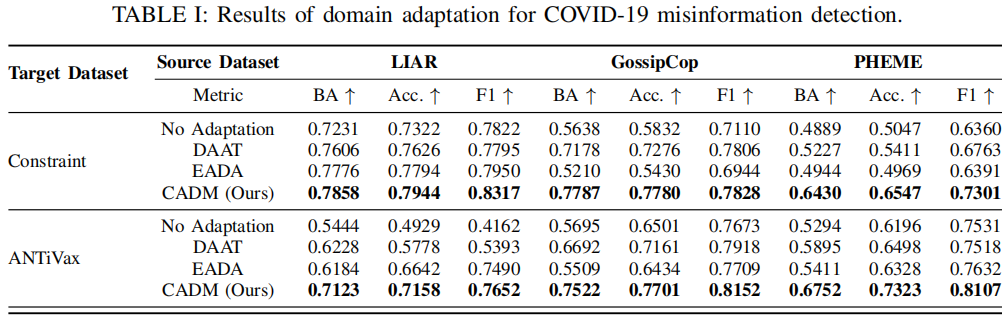
在我们的实验中,我们使用了三个 source misinformation datasets :GossipCop , LIAR and PHEME,两个 COVID misinformation datasets:Constraint and ANTiVax。
Results:
虚假新闻检测(CADM)《Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversarial Domain Mixup》的更多相关文章
- Domain Adaptation (3)论文翻译
Abstract The recent success of deep neural networks relies on massive amounts of labeled data. For a ...
- Unsupervised Domain Adaptation by Backpropagation
目录 概 主要内容 代码 Ganin Y. and Lempitsky V. Unsupervised Domain Adaptation by Backpropagation. ICML 2015. ...
- Deep Transfer Network: Unsupervised Domain Adaptation
转自:http://blog.csdn.net/mao_xiao_feng/article/details/54426101 一.Domain adaptation 在开始介绍之前,首先我们需要知道D ...
- 论文阅读 | A Curriculum Domain Adaptation Approach to the Semantic Segmentation of Urban Scenes
paper链接:https://arxiv.org/pdf/1812.09953.pdf code链接:https://github.com/YangZhang4065/AdaptationSeg 摘 ...
- Domain Adaptation (1)选题讲解
1 所选论文 论文题目: <Unsupervised Domain Adaptation with Residual Transfer Networks> 论文信息: NIPS2016, ...
- A Primer on Domain Adaptation Theory and Applications
目录 概 主要内容 符号说明 Prior shift Covariate shift KMM Concept shift Subspace mapping Wasserstein distance 应 ...
- 关于模式识别中的domain generalization 和 domain adaptation
今晚听了李文博士的报告"Domain Generalization and Adaptation using Low-Rank Examplar Classifiers",讲的很精 ...
- 【论文笔记】Domain Adaptation via Transfer Component Analysis
论文题目:<Domain Adaptation via Transfer Component Analysis> 论文作者:Sinno Jialin Pan, Ivor W. Tsang, ...
- 域适应(Domain adaptation)
定义 在迁移学习中, 当源域和目标的数据分布不同 ,但两个任务相同时,这种 特殊 的迁移学习 叫做域适应 (Domain Adaptation). Domain adaptation有哪些实现手段呢? ...
- Domain Adaptation论文笔记
领域自适应问题一般有两个域,一个是源域,一个是目标域,领域自适应可利用来自源域的带标签的数据(源域中有大量带标签的数据)来帮助学习目标域中的网络参数(目标域中很少甚至没有带标签的数据).领域自适应如今 ...
随机推荐
- mongodb基础整理篇————副本概念篇[外篇]
前言 副本集整理. 开始逐步把mongodb博客补齐了. 正文 什么是副本集 副本集是一组服务器,其中一个是用于处理写入操作的主节点,还有多个用于保存主节点的数据副本的从节点. 如果主节点崩溃了,则从 ...
- super关键字的使用
1.super理解为:父类的 2.super可以用来调用:属性.方法.构造器 3.super的使用:调用属性和方法 3.1 我们可以在子类的方法或构造器中.通过使用"super.属性&quo ...
- JavaScript基础&实战(3)js中的流程控制语句、条件分支语句、for循环、while循环
文章目录 1.流程控制语句 1.1 代码 1.2 测试结果 2.弹窗提示输入内容 2.1 代码 2.2 测试结果 3.条件分支语句 3.1 代码 3.2 测试结果 4.while和 do...whil ...
- MRR和Hits@n
使用 MRR/Hits@n 评估链路预测 平均倒数秩(Mean reciprocal rank,MRR) MRR是一种衡量搜索质量的方法.我们取一个未被破坏的节点,找到距离定义为相似性分数的" ...
- Debian 参考手册之第6章Debian档案库
来源:https://www.debian.org/doc/manuals/debian-faq/ftparchives#oldcodenames 第 6 章 Debian 档案库 目录 6.1. 有 ...
- 编辑距离(Minimum Edit Distance)
编辑距离(Minimum Edit Distance,MED),也叫 Levenshtein Distance.他的含义是计算字符串a转换为字符串b的最少单字符编辑次数.编辑操作有:插入.删除.替换( ...
- Java多线程-ThreadPool线程池-2(四)
线程池是个神器,用得好会非常地方便.本来觉得线程池的构造器有些复杂,即使讲清楚了对今后的用处可能也不太大,因为有一些Java定义好的线程池可以直接使用.但是(凡事总有个但是),还是觉得讲一讲可能跟有助 ...
- vim编译器
光标移动,模式切换,删除,查找,复制,粘贴,撤销 vim的三种模式(重点) vim存在的三种模式 命令模式,编辑模式,尾行模式 命令 模式:不能直接编辑.但是可以用快捷键进行一些操作(删除,复制,移动 ...
- 如何通过Java导出带格式的 Excel 数据到 Word 表格
在Word中制作报表时,我们经常需要将Excel中的数据复制粘贴到Word中,这样则可以直接在Word文档中查看数据而无需打开另一个Excel文件.但是如果表格比较长,内容就会存在一定程度的丢失,无法 ...
- Jenkins发版通知企业微信机器人
1)开始通知 在Jenkins发版过程的第一步添加下面内容,调用下面脚本实现机器人发版通知(注意脚本路径和传参) ${BUILD_USER}是Jenkins内置变量,执行发布的用户名,需要安装插件-B ...