基于RL(Q-Learning)的迷宫寻路算法
强化学习是一种机器学习方法,旨在通过智能体在与环境交互的过程中不断优化其行动策略来实现特定目标。与其他机器学习方法不同,强化学习涉及到智能体对环境的观测、选择行动并接收奖励或惩罚。因此,强化学习适用于那些需要自主决策的复杂问题,比如游戏、机器人控制、自动驾驶等。强化学习可以分为基于价值的方法和基于策略的方法。基于价值的方法关注于寻找最优的行动价值函数,而基于策略的方法则直接寻找最优的策略。强化学习在近年来取得了很多突破,比如 AlphaGo 在围棋中战胜世界冠军。
强化学习的重要概念:
- 环境:其主体被嵌入并能够感知和行动的外部系统
- 主体:动作的行使者
- 状态:主体的处境
- 动作:主体执行的动作
- 奖励:衡量主体动作成功与否的反馈
问题描述
给定一个N*N矩阵,其中仅有-1、0、1组成该矩阵,-1表示障碍,0表示路,1表示终点和起点:
# 生成迷宫图像
def generate_maze(size):
maze = np.zeros((size, size))
# Start and end points
start = (random.randint(0, size-1), 0)
end = (random.randint(0, size-1), size-1)
maze[start] = 1
maze[end] = 1
# Generate maze walls
for i in range(size*size):
x, y = random.randint(0, size-1), random.randint(0, size-1)
if (x, y) == start or (x, y) == end:
continue
if random.random() < 0.2:
maze[x, y] = -1
if np.sum(np.abs(maze)) == size*size - 2:
break
return maze, start, end
上述函数返回一个numpy数组类型的迷宫,起点和终点
生成迷宫图像:
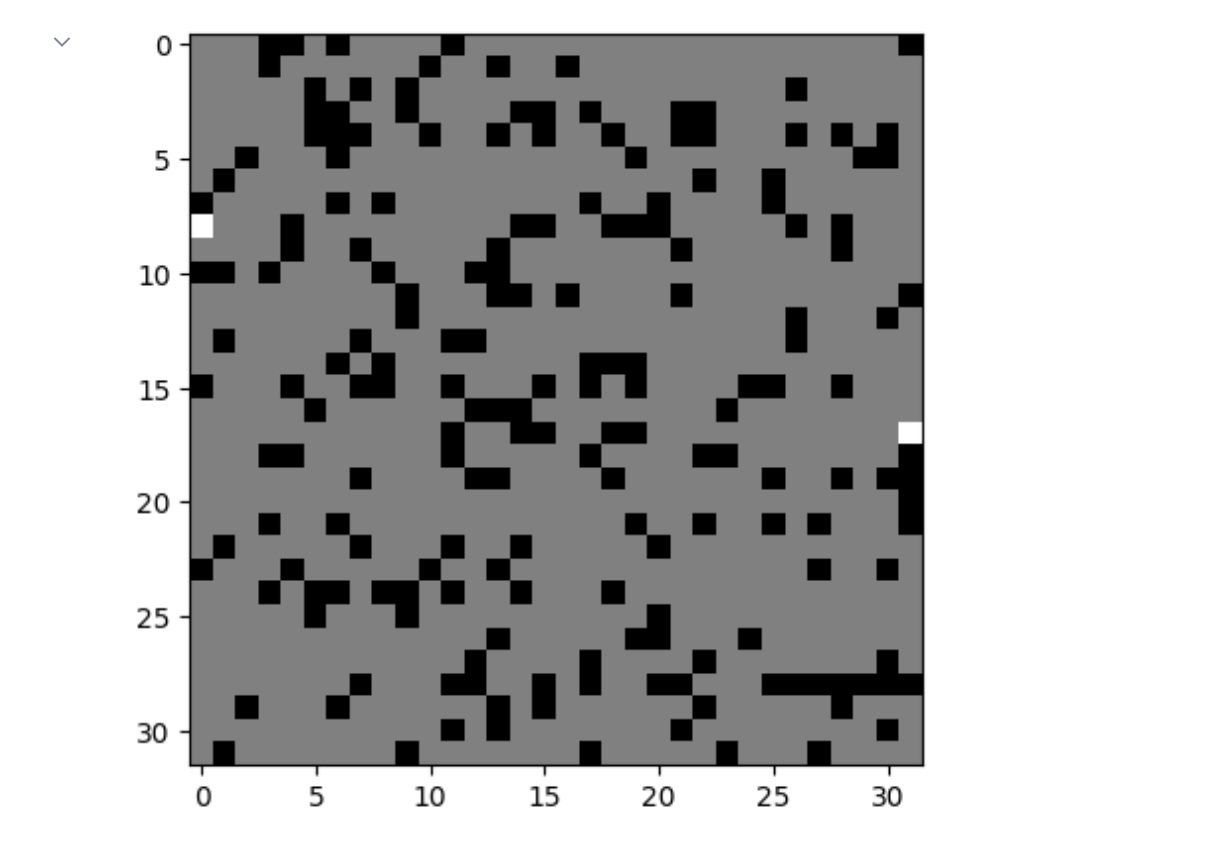
使用BFS进行寻路:
# BFS求出路径
def solve_maze(maze, start, end):
size = maze.shape[0]
visited = np.zeros((size, size))
solve = np.zeros((size,size))
queue = [start]
visited[start[0],start[1]] = 1
while queue:
x, y = queue.pop(0)
if (x, y) == end:
break
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
nx, ny = x + dx, y + dy
if nx < 0 or nx >= size or ny < 0 or ny >= size or visited[nx, ny] or maze[nx, ny] == -1:
continue
queue.append((nx, ny))
visited[nx, ny] = visited[x, y] + 1
if visited[end[0],end[1]] == 0:
return solve,[]
path = [end]
x, y = end
while (x, y) != start:
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
nx, ny = x + dx, y + dy
if nx < 0 or nx >= size or ny < 0 or ny >= size or visited[nx, ny] != visited[x, y] - 1:
continue
path.append((nx, ny))
x, y = nx, ny
break
points = path[::-1] # 倒序
for point in points:
solve[point[0]][point[1]] = 1
return solve, points
上述函数返回一个numpy数组,和点组成的路径,图像如下:

BFS获得的解毫无疑问是最优解,现在使用强化学习的方法来解决该问题(QLearning、DQN)
QLearning
该算法核心原理是Q-Table,其行和列表示State和Action的值,Q-Table的值Q(s,a)是衡量当前States采取行动a的重要依据
具体步骤如下:
- 初始化Q表
- 执行以下循环:
- 初始化一个Q表格,Q表格的行表示状态,列表示动作,Q值表示某个状态下采取某个动作的价值估计。初始时,Q值可以设置为0或随机值。
- 针对每个时刻,根据当前状态s,选择一个动作a。可以根据当前状态的Q值和某种策略(如贪心策略)来选择动作。
- 执行选择的动作a,得到下一个状态s'和相应的奖励r$
- 基于下一个状态s',更新Q值。Q值的更新方式为:
- 初始化一个状态s。
- 根据当前状态s和Q表中的Q值,选择一个动作a。可以通过epsilon-greedy策略来进行选择,即有一定的概率随机选择动作,以便于探索新的状态,否则就选择Q值最大的动作。
- 执行选择的动作a,得到下一个状态s'和奖励r。
- 根据s'和Q表中的Q值,计算出最大Q值maxQ。
- 根据Q-learning的更新公式,更新Q值:Q(s, a) = Q(s, a) + alpha * (r + gamma * maxQ - Q(s, a)),其中alpha是学习率,gamma是折扣因子。
- 将当前状态更新为下一个状态:s = s'。
- 如果当前状态为终止状态,则转到步骤1;否则转到步骤2。
- 重复执行步骤1-7直到收敛,即Q值不再发生变化或者达到预定的最大迭代次数。最终得到的Q表中的Q值就是最优的策略。
- 重复执行2-4步骤,直到到达终止状态,或者达到预设的最大步数。
- 不断执行1-5步骤,直到Q值收敛。
- 在Q表格中根据最大Q值,选择一个最优的策略。
代码实现
实现QLearningAgent类:
class QLearningAgent:
def __init__(self,actions,size):
self.actions = actions
self.learning_rate = 0.01
self.discount_factor = 0.9
self.epsilon = 0.1 # 贪婪策略取值
self.num_actions = len(actions)
# 初始化Q-Table
self.q_table = np.zeros((size,size,self.num_actions))
def learn(self,state,action,reward,next_state):
current_q = self.q_table[state][action] # 从Q-Table中获取当前Q值
new_q = reward + self.discount_factor * max(self.q_table[next_state]) # 计算新Q值
self.q_table[state][action] += self.learning_rate * (new_q - current_q) # 更新Q表
# 获取动作
def get_action(self,state):
if np.random.rand() < self.epsilon:
action = np.random.choice(self.actions)
else:
state_action = self.q_table[state]
action = self.argmax(state_action)
return action
@staticmethod
def argmax(state_action):
max_index_list = []
max_value = state_action[0]
for index,value in enumerate(state_action):
if value > max_value:
max_index_list.clear()
max_value = value
max_index_list.append(index)
elif value == max_value:
max_index_list.append(index)
return random.choice(max_index_list)
类的初始化:
def __init__(self,actions,size):
self.actions = actions
self.learning_rate = 0.01
self.discount_factor = 0.9
self.epsilon = 0.1 # 贪婪策略取值
self.num_actions = len(actions)
# 初始化Q-Table
self.q_table = np.zeros((size,size,self.num_actions))
上述代码中,先初始化动作空间,设置学习率,discount_factor是折扣因子,epsilon是贪婪策略去值,num_actions是动作数
def learn(self,state,action,reward,next_state):
current_q = self.q_table[state][action] # 从Q-Table中获取当前Q值
new_q = reward + self.discount_factor * max(self.q_table[next_state]) # 计算新Q值
self.q_table[state][action] += self.learning_rate * (new_q - current_q) # 更新Q表
该方法是QLearning的核心流程,给定当前状态、动作、赏罚和下一状态更新Q表
# 获取动作
def get_action(self,state):
if np.random.rand() < self.epsilon:
# 贪婪策略 随机选取动作
action = np.random.choice(self.actions)
else:
# 从Q-Table中选择
state_action = self.q_table[state]
action = self.argmax(state_action)
return action
该方法首先使用贪婪策略来决定是随机选择一个动作,还是选择 Q-Table 中当前状态对应的最大 Q 值对应的动作
@staticmethod
def argmax(state_action):
max_index_list = []
max_value = state_action[0]
for index,value in enumerate(state_action):
if value > max_value:
max_index_list.clear()
max_value = value
max_index_list.append(index)
elif value == max_value:
max_index_list.append(index)
return random.choice(max_index_list)
该方法首先获取最大值对应的动作,遍历Q表中的所有动作,找到最大值所对应的所有动作,最后从这些动作中随机选择一个作为最终的动作。
定义环境
下述定义了一个迷宫环境:
class MazeEnv:
def __init__(self,size):
self.size = size
self.actions = [0,1,2,3]
self.maze,self.start,self.end = self.generate(size)
# 重置状态
def reset(self):
self.state = self.start
self.goal = self.end
self.path = [self.start]
self.solve = np.zeros_like(self.maze)
self.solve[self.start] = 1
self.solve[self.end] = 1
return self.state
def step(self, action):
# 执行动作
next_state = None
if action == 0 and self.state[0] > 0:
next_state = (self.state[0]-1, self.state[1])
elif action == 1 and self.state[0] < self.size-1:
next_state = (self.state[0]+1, self.state[1])
elif action == 2 and self.state[1] > 0:
next_state = (self.state[0], self.state[1]-1)
elif action == 3 and self.state[1] < self.size-1:
next_state = (self.state[0], self.state[1]+1)
else:
next_state = self.state
if next_state == self.goal:
reward = 100
elif self.maze[next_state] == -1:
reward = -100
else:
reward = -1
self.state = next_state # 更新状态
self.path.append(self.state)
self.solve[self.state] = 1
done = (self.state == self.goal) # 判断是否结束
return next_state, reward, done
@staticmethod
# 生成迷宫图像
def generate(size):
maze = np.zeros((size, size))
# Start and end points
start = (random.randint(0, size-1), 0)
end = (random.randint(0, size-1), size-1)
maze[start] = 1
maze[end] = 1
# Generate maze walls
for i in range(size * size):
x, y = random.randint(0, size-1), random.randint(0, size-1)
if (x, y) == start or (x, y) == end:
continue
if random.random() < 0.2:
maze[x, y] = -1
if np.sum(np.abs(maze)) == size*size - 2:
break
return maze, start, end
@staticmethod
# BFS求出路径
def solve_maze(maze, start, end):
size = maze.shape[0]
visited = np.zeros((size, size))
solve = np.zeros((size,size))
queue = [start]
visited[start[0],start[1]] = 1
while queue:
x, y = queue.pop(0)
if (x, y) == end:
break
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
nx, ny = x + dx, y + dy
if nx < 0 or nx >= size or ny < 0 or ny >= size or visited[nx, ny] or maze[nx, ny] == -1:
continue
queue.append((nx, ny))
visited[nx, ny] = visited[x, y] + 1
if visited[end[0],end[1]] == 0:
return solve,[]
path = [end]
x, y = end
while (x, y) != start:
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
nx, ny = x + dx, y + dy
if nx < 0 or nx >= size or ny < 0 or ny >= size or visited[nx, ny] != visited[x, y] - 1:
continue
path.append((nx, ny))
x, y = nx, ny
break
points = path[::-1] # 倒序
for point in points:
solve[point[0]][point[1]] = 1
return solve, points
执行
下面生成一个32*32的迷宫,并进行30000次迭代
maze_size = 32
# 创建迷宫环境
env = MazeEnv(maze_size)
# 初始化QLearning智能体
agent = QLearningAgent(actions=env.actions,size=maze_size)
# 进行30000次游戏
for episode in range(30000):
state = env.reset()
while True:
action = agent.get_action(state)
next_state,reward,done = env.step(action)
agent.learn(state,action,reward,next_state)
state = next_state
if done:
break
print(agent.q_table) # 输出Q-Table
定义一个函数,用于显示迷宫的路线:
from PIL import Image
def maze_to_image(maze, path):
size = maze.shape[0]
img = Image.new('RGB', (size, size), (255, 255, 255))
pixels = img.load()
for i in range(size):
for j in range(size):
if maze[i, j] == -1:
pixels[j, i] = (0, 0, 0)
elif maze[i, j] == 1:
pixels[j, i] = (0, 255, 0)
for x, y in path:
pixels[y, x] = (255, 0, 0)
return np.array(img)
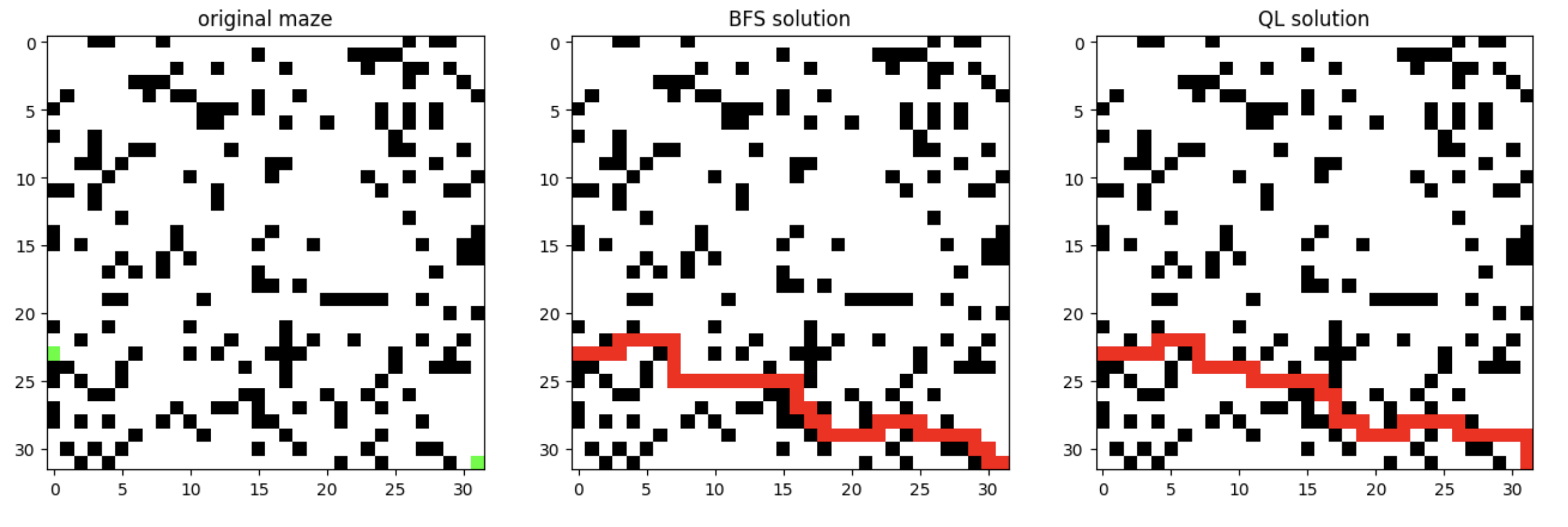
接下来显示三个图像:迷宫图像、BFS求解的路线、QLearning求解路线:
plt.figure(figsize=(16, 10))
image1 = maze_to_image(env.maze,[])
plt.subplot(1,3,1)
plt.imshow(image1)
plt.title('original maze')
_,path = env.solve_maze(env.maze,env.start,env.end)
image2 = maze_to_image(env.maze,path)
plt.subplot(1,3,2)
plt.imshow(image2)
plt.title('BFS solution')
image3 = maze_to_image(env.maze,env.path)
plt.subplot(1,3,3)
plt.imshow(image3)
plt.title('QL solution')
# 显示图像
plt.show()
显示:
基于RL(Q-Learning)的迷宫寻路算法的更多相关文章
- 【Android】基于A星寻路算法的简单迷宫应用
简介 基于[漫画算法-小灰的算法之旅]上的A星寻路算法,开发的一个Demo.目前实现后退.重新载入.路径提示.地图刷新等功能.没有做太多的性能优化,算是深化对A星寻路算法的理解. 界面预览: 初始化: ...
- 基于Unity的A星寻路算法(绝对简单完整版本)
前言 在上一篇文章,介绍了网格地图的实现方式,基于该文章,我们来实现一个A星寻路的算法,最终实现的效果为: 项目源码已上传Github:AStarNavigate 在阅读本篇文章,如果你对于里面提到的 ...
- 《C++游戏开发》十六 游戏中的寻路算法(二):迷宫&A*算法基础
本系列文章由七十一雾央编写,转载请注明出处. http://blog.csdn.net/u011371356/article/details/10289253 作者:七十一雾央 新浪微博:http: ...
- PHP树生成迷宫及A*自己主动寻路算法
PHP树生成迷宫及A*自己主动寻路算法 迷宫算法是採用树的深度遍历原理.这样生成的迷宫相当的细,并且死胡同数量相对较少! 随意两点之间都存在唯一的一条通路. 至于A*寻路算法是最大众化的一全自己主动寻 ...
- 如何用简单例子讲解 Q - learning 的具体过程?
作者:牛阿链接:https://www.zhihu.com/question/26408259/answer/123230350来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明 ...
- A*寻路算法的探寻与改良(三)
A*寻路算法的探寻与改良(三) by:田宇轩 第三分:这部分内容基于树.查找算法等对A*算法的执行效率进行了改良,想了解细 ...
- A*寻路算法的探寻与改良(二)
A*寻路算法的探寻与改良(二) by:田宇轩 第二部分:这部分内容主要是使用C语言编程实现A*, ...
- A*寻路算法的探寻与改良(一)
A*寻路算法的探寻与改良(一) by:田宇轩 第一部分:这里我们主 ...
- 强化学习9-Deep Q Learning
之前讲到Sarsa和Q Learning都不太适合解决大规模问题,为什么呢? 因为传统的强化学习都有一张Q表,这张Q表记录了每个状态下,每个动作的q值,但是现实问题往往极其复杂,其状态非常多,甚至是连 ...
- Learning to rank基本算法
搜索排序相关的方法,包括 Learning to rank 基本方法 Learning to rank 指标介绍 LambdaMART 模型原理 FTRL 模型原理 Learning to rank ...
随机推荐
- 用户输入URL回车到页面呈现之间发生的具体步骤
这个过程中涉及到负责管理的浏览器进程.负责网络请求的网络进程和负责页面渲染的渲染进程 渲染过程这里先不进行具体描述,后续会单独整理 整体步骤 前提,当前页面的卸载事件和收集需要释放的内存 第一步,浏览 ...
- Rsync+NFS实战,解决NFS单点问题
1.环境准备 主机 ⻆⾊ ip web01 NFS客户端.RSYNC客户端 172.16.1.7 nfs NFS服务端.RSYNC客户端 172.16.1.31 backup NFS服务端.RSYNC ...
- 如何通过dump文件定位崩溃,解决问题
1.dump文件是附加堆栈信息的存储文件的简称,文件扩展名".dmp",通过dump文件我们可以得到程序运行某一时刻的堆栈数据.2.当程序意外崩溃后,通常程序会立即中断运行,拿到这 ...
- Sqoop导入MySQL表中数据到Hive出现错误: ERROR hive.HiveConfig: Make sure HIVE_CONF_DIR is set correctly.ERROR tool.ImportTool: Import failed:
1.问题描述: (1)问题示例: [Hadoop@master TestDir]$ sqoop import --connect jdbc:mysql://master:3306/source?use ...
- WIn环境基于vs编辑器,Qt应用申请管理员权限的解决方法(转载)
原文章地址:https://blog.csdn.net/weixin_38416696/article/details/103879377 基本按照那个文章的操作.基本可以了. 唯一问题就是那个vs的 ...
- Qt 5.15.2 QTextEdit无法设置新字体的处理方式
首发于我的个人博客:xie-kang.com 博客内有更多文章,欢迎大家访问 原文地址 在使用QT 5.15.2 开发的过程中碰到了件怪事,下列代码无法给QTextEdit选中的文字设置字体: QTe ...
- mysql5.7主从搭建过程
1.下载程序包 mysql-5.7.33-linux-glibc2.12-x86_64.tar.gz ,解压至/opt/app/mysql2.配置/etc/my.cnf[mysql]socket=/o ...
- java8利用流和lambda表达式对list遍历处理
java8的lambda表达式提供了一些方便list操作的方法,主要涵盖分组.过滤.求和.最值.排序.去重. 优点: (1) 简洁,跟之前的传统写法对比,能少写不少代码; (2) 易并行计算.尤其适用 ...
- Python内置函数:enumerate
enumerate(sequence, [start=0]) enumerate单词本身翻译为列举.枚举. 官方说明: enumerate() 函数用于将一个可遍历的数据对象(如列表.元组或字符串)组 ...
- 从0搭建Vue3组件库(六):前端流程化控制工具gulp的使用
前言 随着前端诸如webpack,rollup,vite的发展,gulp感觉似乎好像被取代了.其实并没有,只不过它从台前退居到了幕后.我们仍然可以在很多项目中看到它的身影,比如elementplus. ...