hive从入门到放弃(六)——常用文件存储格式
hive 存储格式有很多,但常用的一般是 TextFile、ORC、Parquet 格式,在我们单位最多的也是这三种
hive 默认的文件存储格式是 TextFile。
除 TextFile 外的其他格式的表不能直接从本地文件导入数据,要先导入到 TextFile 格式的表中,再从表中用 insert 导入到其他格式的表中。
一、TextFile
TextFile 是行式存储。
建表时无需指定,一般默认这种格式,以这种格式存储的文件,可以直接在 HDFS 上 cat 查看数据。
可以用任意分隔符对列分割,建表时需要指定分隔符。
不会对文件进行压缩,因此加载数据的时候会比较快,因为不需要解压缩;但也因此更占用存储空间。
二、ORCFile
ORCFile 是列式存储。
建表时需指定 STORED AS ORC,文件存储方式为二进制文件。
Orc表支持None、Zlib、Snappy压缩,默认支持Zlib压缩。
Zlib 压缩率比 Snappy 高,Snappy 效率比 Zlib 高。
这几种压缩方式都不支持文件分割,所以压缩后的文件在执行 Map 操作时只会被一个任务所读取。
因此若压缩文件较大,处理该文件的时间比处理其它普通文件的时间要长,造成数据倾斜。
另外,hive 建事务表需要指定为 orc 存储格式。
ORC 格式如下所示:
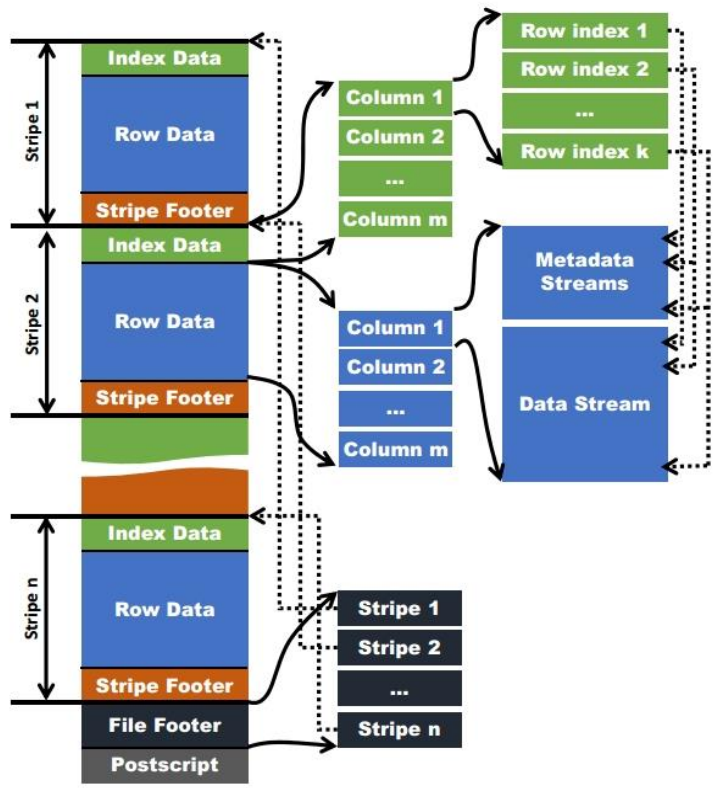
- stripe:存储数据的地方,包括实际数据、数据的索引信息
- index data:保存了数据在 stripe 中位置的索引信息
- rows data:数据实际存储的地方,数据以流的形式进行存储
- stripe footer:保存数据所在的文件目录
- file footer:包含了文件中 stripe 的列表,每个 stripe 的行数,以及每个列的数据类型。它还包含每个列的最小值、最大值、行计数、求和等聚合信息。
- postscript:含有压缩参数和压缩大小相关的信息
三、Parquet
Parquet 也是列式存储。
建表时需指定 STORED AS PARQUET,文件存储方式为二进制文件。
可以使用的压缩方式有 UNCOMPRESSED、 SNAPPY、GZP和LZO。默认值为 UNCOMPRESSED,表示页的压缩方式
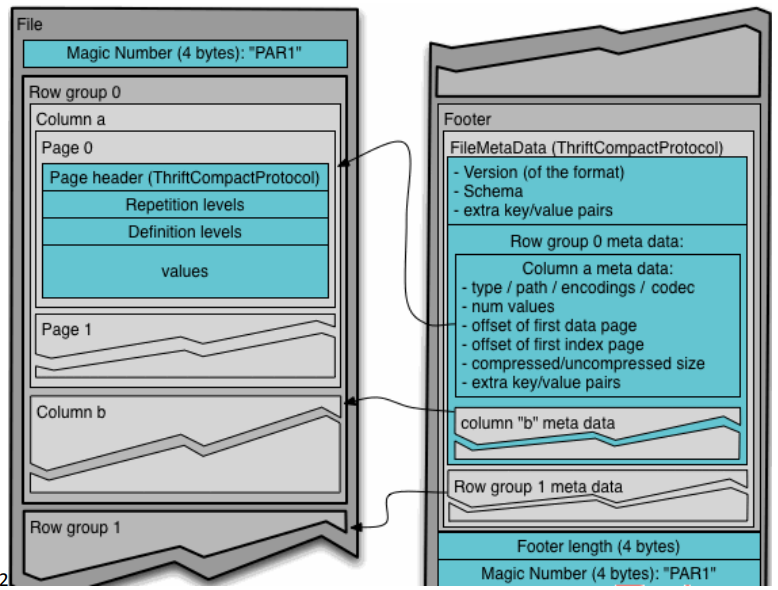
行组(Row Group):每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
四、三者对比
同样的数据,TextFile 为 2.4G 的情况下,将原数据存放为 ORC 以及 Parquet 格式后,其占用存储大小以及查询效率大致如下:
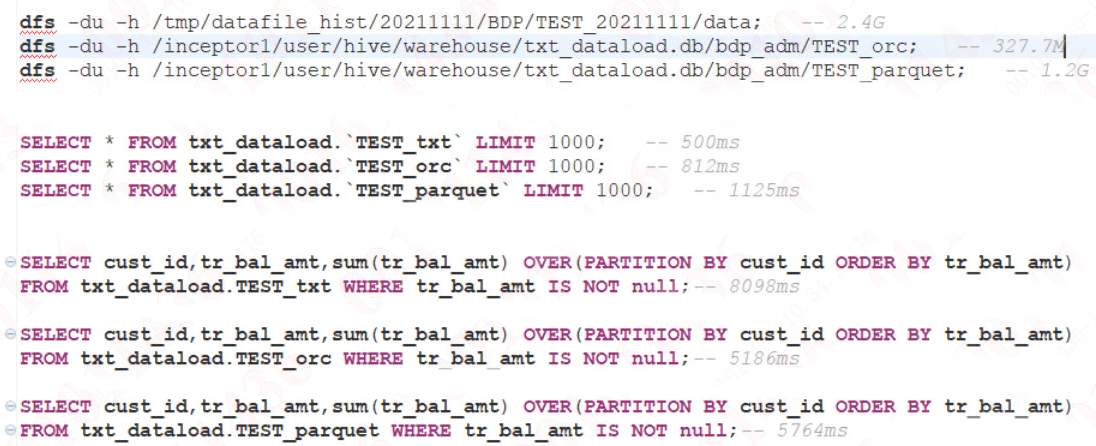
由此可以看出压缩比:ORC > Parquet > TextFile
在只有 Fecth 的情况下,由于 TextFile 不需要解压缩,因此效率较高。
对于需要 MapReduce 操作的查询,效率:ORC >= Parquet > TextFile
当然,这只是我自己简单的测试,有些变量并没有控制好。
比如在单个文件比较大的情况下,可能 Parquet 的效率会比较高。
在实际生产中,使用 Parquet 存储 lzo 压缩的方式比较常见,这种情况下可以避免由于读取不可分割的大文件引发的数据倾斜。
但是,如果数据量并不大,使用 ORC 存储 snappy 压缩的效率还是非常高的;对于需要事务的场景,还是用 ORC。
至于要用哪种存储格式,需要基于自身业务进行考量。
今天的文章到这里就结束了,如果觉得写的不错的话,可以随手点个赞和关注!
关注“大数据的奇妙冒险”,转载请注明出处!
hive从入门到放弃(六)——常用文件存储格式的更多相关文章
- hive从入门到放弃(三)——DML数据操作
上一篇给大家介绍了 hive 的 DDL 数据定义语言,这篇来介绍一下 DML 数据操作语言. 没看过的可以点击跳转阅读: hive从入门到放弃(一)--初识hive hive从入门到放弃(二)--D ...
- hive从入门到放弃(一)——初识hive
之前更完了<Kafka从入门到放弃>系列文章,本人决定开新坑--hive从入门到放弃,今天先认识一下hive. 没看过 Kafka 系列的朋友可以点此传送阅读: <Kafka从入门到 ...
- hive从入门到放弃(二)——DDL数据定义
前一篇文章,介绍了什么是 hive,以及 hive 的架构.数据类型,没看的可以点击阅读:hive从入门到放弃(一)--初识hive 今天讲一下 hive 的 DDL 数据定义 创建数据库 CREAT ...
- hive从入门到放弃(四)——分区与分桶
今天讲讲分区表和分桶表,前面的文章还没看的可以点击链接: hive从入门到放弃(一)--初识hive hive从入门到放弃(二)--DDL数据定义 hive从入门到放弃(三)--DML数据操作 分区 ...
- Hive性能调优(一)----文件存储格式及压缩方式选择
合理使用文件存储格式 建表时,尽量使用 orc.parquet 这些列式存储格式,因为列式存储的表,每一列的数据在物理上是存储在一起的,Hive查询时会只遍历需要列数据,大大减少处理的数据量. 采用合 ...
- python全栈开发从入门到放弃之常用模块和正则
什么是模块? 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1 使用python编写的代码(.p ...
- MyBatis从入门到放弃六:延迟加载、一级缓存、二级缓存
前言 使用ORM框架我们更多的是使用其查询功能,那么查询海量数据则又离不开性能,那么这篇中我们就看下mybatis高级应用之延迟加载.一级缓存.二级缓存.使用时需要注意延迟加载必须使用resultMa ...
- 大数据:Hive - ORC 文件存储格式
一.ORC File文件结构 ORC的全称是(Optimized Row Columnar),ORC文件格式是一种Hadoop生态圈中的列式存储格式,它的产生早在2013年初,最初产生自Apache ...
- Hive - ORC 文件存储格式【转】
一.ORC File文件结构 ORC的全称是(Optimized Row Columnar),ORC文件格式是一种Hadoop生态圈中的列式存储格式,它的产生早在2013年初,最初产生自Apache ...
随机推荐
- linux环境下搭建solr服务器--单机版
前提需要在安装好jdk和tomcat,本人用的是jdk1.8+tomcat8.5+solr4.10. 第一步:安装linux.jdk.tomcat.(这步都是比较简单的,就不多说了) 第二步:把sol ...
- labview和matlab区别
LabVIEW和MATLAB作为本身功能比较完善的软件环境,在各自不同的领域中有着十分广泛的应用.下面小编就详细介绍LabVIEW和MATLA以及它们之间的区别. 一.LabVIEW简介 LabVIE ...
- 前端调试利器 - Charles
Docs 开发之 Charles 配置指南 1.下载与安装 charles-proxy-4.1.4 .dmg56.12 MB已存到云盘下载 2.激活 使用公司正版license 激活 安装证书 点击证 ...
- 一块小饼干(Cookie)的故事-上篇
cookie 如果非要用汉语理解的话应该是 一段小型文本文件,由网景的创始人之一的卢 蒙特利在93年发明. 上篇是熟悉一下注册的大致流程,下篇熟悉登录流程以及真正的Cookie 实现基本的注册功能 我 ...
- Android Studio安装及问题
安装教程+虚拟机调试:https://blog.csdn.net/y74364/article/details/96121530 gradle下载缓慢解决办法:https://blog.csdn.ne ...
- CCF201812-1小明上学
题目背景 小明是汉东省政法大学附属中学的一名学生,他每天都要骑自行车往返于家和学校.为了能尽可能充足地睡眠,他希望能够预计自己上学所需要的时间.他上学需要经过数段道路,相邻两段道路之间设有至多一盏红绿 ...
- ssm项目框架搭建(增删改查案例实现)——(SpringMVC+Spring+mybatis项目整合)
Spring 常用注解 内容 一.基本概念 1. Spring 2. SpringMVC 3. MyBatis 二.开发环境搭建 1. 创建 maven 项目 2. SSM整合 2.1 项目结构图 2 ...
- HTML 和 form 表单常用标签
HTML和CSS 常用标签: p:段落,自动换行 span:和div类似,但是默认不换行 br:换行 hr:分割线 h1-h6:标题标签 a:超链接 瞄点:通过给a链接设置#XX作为链接,给需要链接的 ...
- Java在方法中定义可变参数类型
学习目标: 掌握可变参数的应用 学习内容: 1.定义 在方法中传递数组有一种更简单的方式--方法的可变参数,其本质是一个语法糖,目的是让开发者写代码更简单. 2.语法 [修饰符] 返回值类型 方法名称 ...
- TypeScript学习文档-基础篇(完结)
目录 TypeScript学习第一章:TypeScript初识 1.1 TypeScript学习初见 1.2 TypeScript介绍 1.3 JS .TS 和 ES之间的关系 1.4 TS的竞争者有 ...