[报告] Microsoft :Application of deep learning methods in speech enhancement
Application of deep learning methods in speech enhancement
语音增强中的深度学习应用
按:
本文是DNS,AEC,PLC等国际级语音竞赛的主办方——Microsoft Research Labs音频与声学研究组(Audio and Acoustics Research Group)于2021年发表的Sound capture and speech enhancement for speech-enabled devices中节选的一章,总结了该组今年来在语音增强领域的工作。该报告的作者为Ivan Tashev和Sebastian Braun。本篇所有图片均源自该报告及其引文。
1. (基于时频域监督学习的)语音增强模块
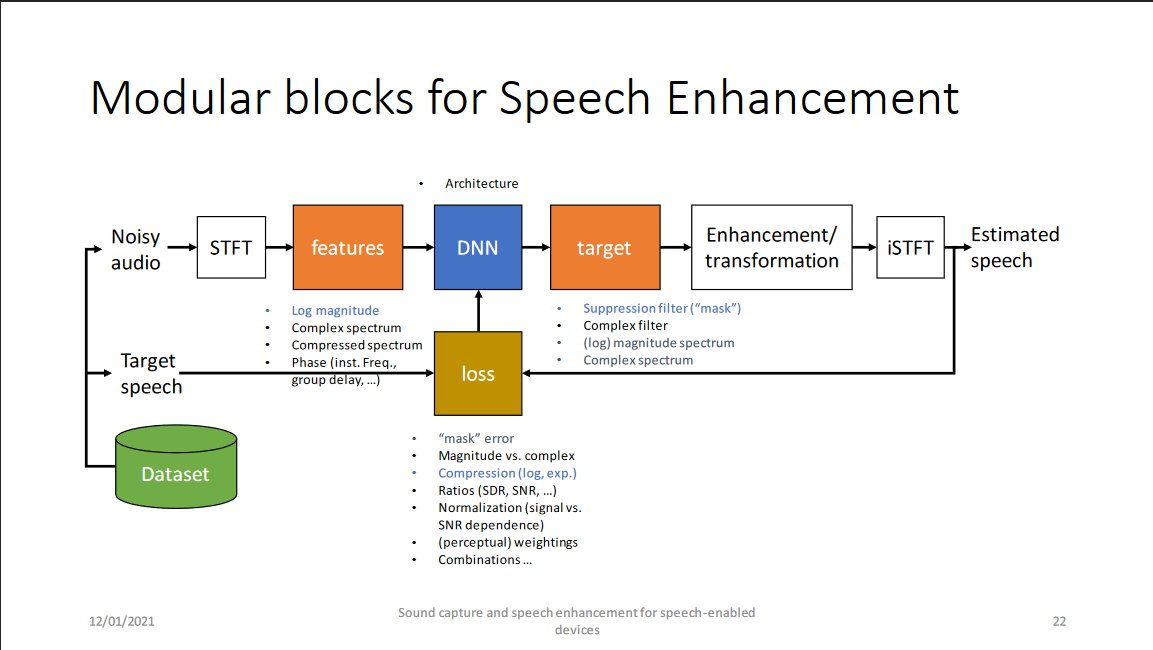
该模块主要展示了时频域语音增强的流程,包括短时傅里叶变换(STFT)、特征提取、神经网络、预测目标、增强/变换(过程)、短时傅里叶反变换(iSTFT)和损失函数几部分。其中自图中第二行开始只在训练阶段进行,本图建议与该组之前的一篇工作中的图(见下图)结合使用。
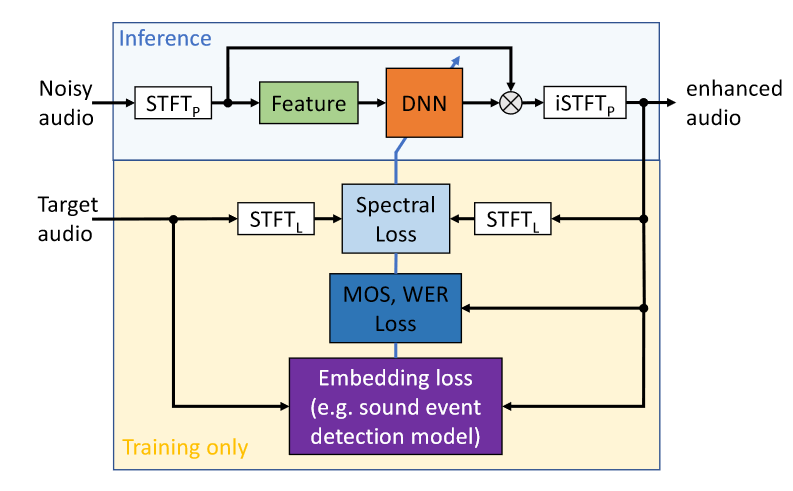
这里主要有以下几点可以讨论:
- STFT: 由于噪声模态的多样性导致语音增强任务天然与语音分离任务有区别,利用傅里叶变换基函数将噪声和语音成分变换到特定的空间中区分模式可能更利于网络的训练和鲁棒性;此外,由于混响情况下时域算法的劣势以及阵列增强中可能的与传统波束形成技术的级联;当然还有从传统语音增强技术中发展而来的习惯;还有最最重要地,目前DNS Challenge的比赛结果。尽管有一些如demucs等优秀的基于时域的语音增强算法,基于时频域的语音增强算法可能更具优势(tips:此处为个人见解)。
- 特征提取:特征提取部分除了直接的复数谱和幅度谱,微软特别提到了对数功率谱和(幂律)压缩复数谱,在说明这两个特征之前,需要说明请注意在报告中预测目标并没有对应的对数幅度谱或者压缩复数谱,而是原始STFT域的谱或掩蔽,这点与之前网络输出与输入对应的一些文献是有区别的,其想表达的是输入经过压缩变换(不论是对数压缩还是指数压缩)的特征将有助于系统性能。
这里简要说明一下对数功率谱和(幂律)压缩复数谱,其中对数幅度谱的使用见于该组的这篇和这篇,定义为\(P = log10(|X(k, n)|^2)\)P = torch.log10(torch.norm(x_stft, dim=-1) + 1e-9);
而幂律压缩复数谱可参考这篇,定义为\(X_{cprs}=\frac{X(k,n)}{|X(k,n)|}|X(k,n)|^{c}\)x_mag = torch.norm(x_stft, dim=-1) + 1e-9
x_cprs_mag = x_mag ** c
x_cprs = torch.stack((x_stft[..., 0] / x_mag * x_cprs_mag, x_stft[..., 1] / x_mag * x_cprs_mag), dim=-1)
- 损失函数:报告中推荐的是压缩谱损失,其他损失包括mask的距离、能量损失(SDR/SI-SDR)、谱距离、感知加权损失和(以上几项或以上几项和其他项的)联合损失。
损失函数分别定义和测评在文献和文献中,其中一部分见下图
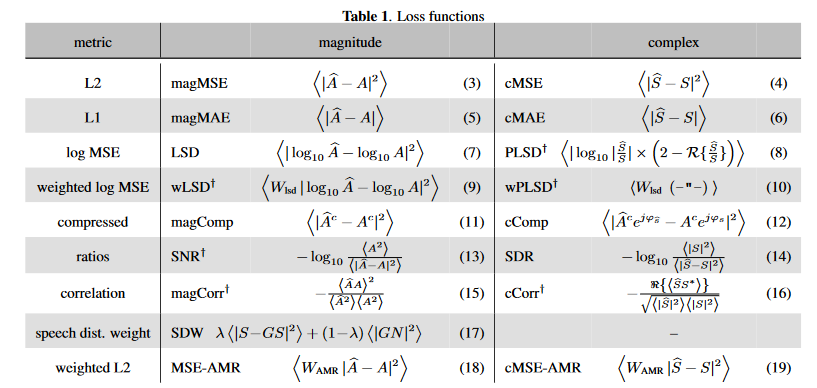
推测压缩谱损失推荐的是幅度正则的压缩谱损失(Magnitude-regularized compressed spectral loss):\(\mathcal{L}=\frac{1}{\sigma_S^{c}}(\lambda\sum_{k,n}{|S^c-\widehat{S}^c|^2+(1-\lambda\sum_{k,n}{||S|^c-|\widehat{S}|^c|^2})})\),其中\(\sigma_S\)是纯净语音有声段的能量,压缩谱的操作与上文定义一致,\(c\)和\(\lambda\)微软推荐都为0.3。
2. 训练数据的生成与增广
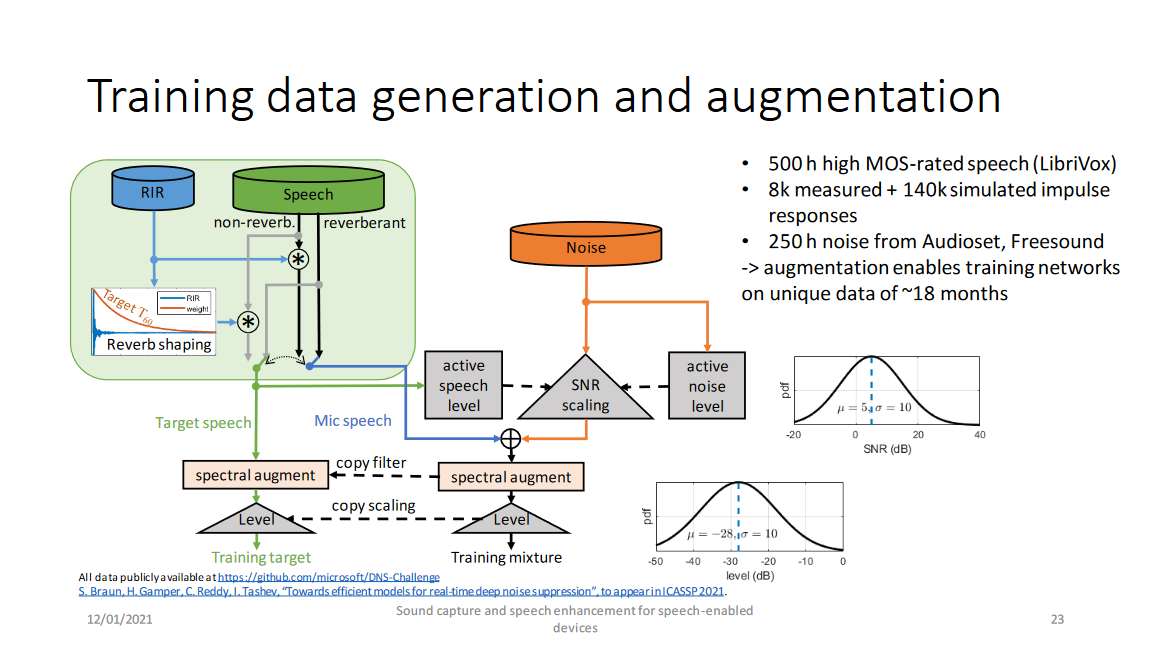
微软推荐的数据生成方式如上图,先不考虑混响情况,纯净语音和噪声分别计算其能量,根据信噪比混合得到带噪数据,而后<带噪数据,纯净语音>用相同的滤波器进行谱增广,最后调节语音音量的动态范围。需要注意的是:
- 纯净语音要进行清洗,选择MOS高的,排除“脏”数据
- 每条预料要足够长(微软推荐10s一句,根据其测评在其模型、特征和loss下至少应长于5s,当条件改变句子最短长度也可能变化)
- 该报告推荐的信噪比按均值5 dB,方差10 dB的高斯分布随机选取
- 该报告推荐的dBFS音量增广按均值-28 dB,方差10 dB的高斯分布随机选取
- 谱增广是指RNNoise中使用的滤波器:\(H(z)=\frac{1+r_1z^{-1}+r_2z^{-2}}{1+r_3z^{-1}+r_4z^{-2}}\),其中\(r_i\sim\mathcal{U}(-\frac{3}{8},\frac{3}{8})\)。但是该报告引用文献中指出由于数据量重足,谱增广是不必要的
最后考虑混响情况(图中绿色区域):和其他文章一样,房间冲激响应(RIR)卷积纯净语音得到混响语音。而为了使语音听起来自然,目标语音仍带少量混响,具体的实现上是令语音与经加权函数加权的RIR卷积,其中加权函数的定位为:\(w_{RIR}(t)=exp(-(t-t_0)\frac{6log(10)}{0.3}), if\quad t \ge t_0,(otherwise\quad w_{RIR}(t)=1)\)
3. 有效的网络架构
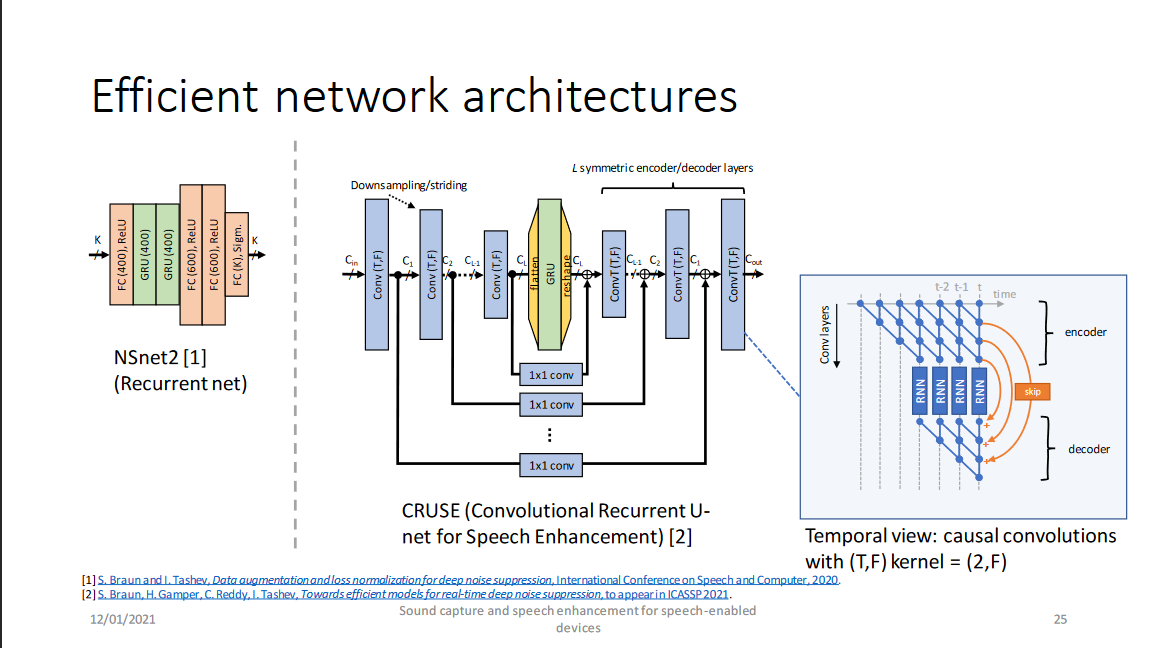
微软提供了两个网络架构,分别为NSNet2(DNS Challenge的baseline)和CRUSE(DNS Challenge中微软提交的比赛方案Microsoft-2)。
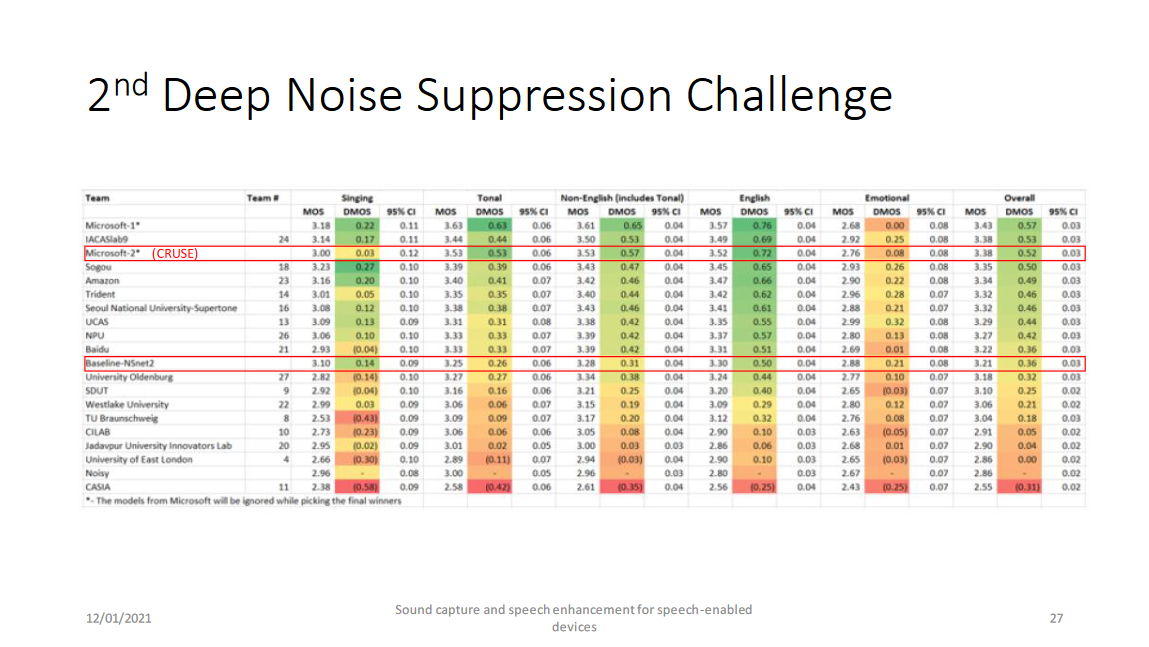
以上两个网络分别是RNNoise(by Valin)-style的幅度谱域模型和GCRN(by Tan)-style的复数谱域模型,RNNoise和GCRN将在之后的博客中将进行详细介绍,这两个网络的介绍请参见博客和博客中介绍。最后是他们的结果:
[报告] Microsoft :Application of deep learning methods in speech enhancement的更多相关文章
- 视觉中的深度学习方法CVPR 2012 Tutorial Deep Learning Methods for Vision
Deep Learning Methods for Vision CVPR 2012 Tutorial 9:00am-5:30pm, Sunday June 17th, Ballroom D (Fu ...
- NLP related basic knowledge with deep learning methods
NLP related basic knowledge with deep learning methods 2017-06-22 First things first >>> ...
- 论文阅读:Face Recognition: From Traditional to Deep Learning Methods 《人脸识别综述:从传统方法到深度学习》
论文阅读:Face Recognition: From Traditional to Deep Learning Methods <人脸识别综述:从传统方法到深度学习> 一.引 ...
- 论文翻译:2022_PACDNN: A phase-aware composite deep neural network for speech enhancement
论文地址:PACDNN:一种用于语音增强的相位感知复合深度神经网络 引用格式:Hasannezhad M,Yu H,Zhu W P,et al. PACDNN: A phase-aware compo ...
- Why are very few schools involved in deep learning research? Why are they still hooked on to Bayesian methods?
Why are very few schools involved in deep learning research? Why are they still hooked on to Bayesia ...
- deep learning 的综述
从13年11月初开始接触DL,奈何boss忙or 各种问题,对DL理解没有CSDN大神 比如 zouxy09等 深刻,主要是自己觉得没啥进展,感觉荒废时日(丢脸啊,这么久....)开始开文,即为记录自 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- What are some good books/papers for learning deep learning?
What's the most effective way to get started with deep learning? 29 Answers Yoshua Bengio, ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料汇总 (上)
转载:http://dataunion.org/8463.html?utm_source=tuicool&utm_medium=referral <Brief History of Ma ...
随机推荐
- 从零开始,开发一个 Web Office 套件(14):复制、粘贴、剪切、全选
这是一个系列博客,最终目的是要做一个基于 HTML Canvas 的.类似于微软 Office 的 Web Office 套件(包括:文档.表格.幻灯片--等等). 博客园:<从零开始, 开发一 ...
- Java中的序列化Serialable
Java中的序列化Serialable https://blog.csdn.net/caomiao2006/article/details/51588838
- SpringAOP--代理
前言 在Spring或者SpringBoot中,可以通过@Aspect注解和切点表达式等配置切面,实现对某一功能的织入.然而其内部到底是如何实现的呢? 实际上,Spring在启动时为切点方法所在类生成 ...
- 面试问题之C++语言:mutable关键字
转载于:https://www.cnblogs.com/xkfz007/articles/2419540.html mutable关键字 mutable的中文意思是"可变的,易变的" ...
- django CBV 及其装饰器
#urls.py from django.contrib import admin from django.urls import path, re_path from app01 import vi ...
- 在 Spring 中如何注入一个 java 集合?
Spring 提供以下几种集合的配置元素:类型用于注入一列值,允许有相同的值.类型用于注入一组值,不允许有相同的值.类型用于注入一组键值对,键和值都可以为任意类型.类型用于注入一组键值对,键和值都只能 ...
- mysql的cpu飙升原因及处理
Mysql 批量杀死进程 正常情况下kill id,即可,但是有时候某一异常连接特别多的时候如此操作会让人抓狂,下面记录下小方法: use information_schema; select co ...
- Python - numpy.clip()函数
np.clip( a, a_min, a_max, out=None): 部分参数解释: 该函数的作用是将数组a中的所有数限定到范围a_min和a_max中.a:输入矩阵:a_min:被限定的最小值, ...
- My模板设计模式
模板模式 目标: 第一个设计模式:模板模式 步骤: 第一个设计模式:模板模式 讲解: 我们现在使用抽象类设计一个模板模式的应用, 例如在小学的时候,我们经常写作文,通常都是有模板可以套用的. 假如我现 ...
- 搞懂高并发性能指标:QPS、TPS、RT、吞吐量
一.QPS,每秒查询 QPS:Queries Per Second意思是"每秒查询率",是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的 ...