集合篇-ConcurrentHashMap
点赞再看,养成习惯,微信搜索「小大白日志」关注这个搬砖人。
文章不定期同步公众号,还有各种一线大厂面试原题、我的学习系列笔记。
jdk1.7和jdk1.8中ConcurrentHashMap的区别?
底层数据结构的区别
- jdk1.7中的ConcurrenHashMap的底层结构=Segment数组+HashEntry数组来实现,put过程使用了Synchronized,结构如下:
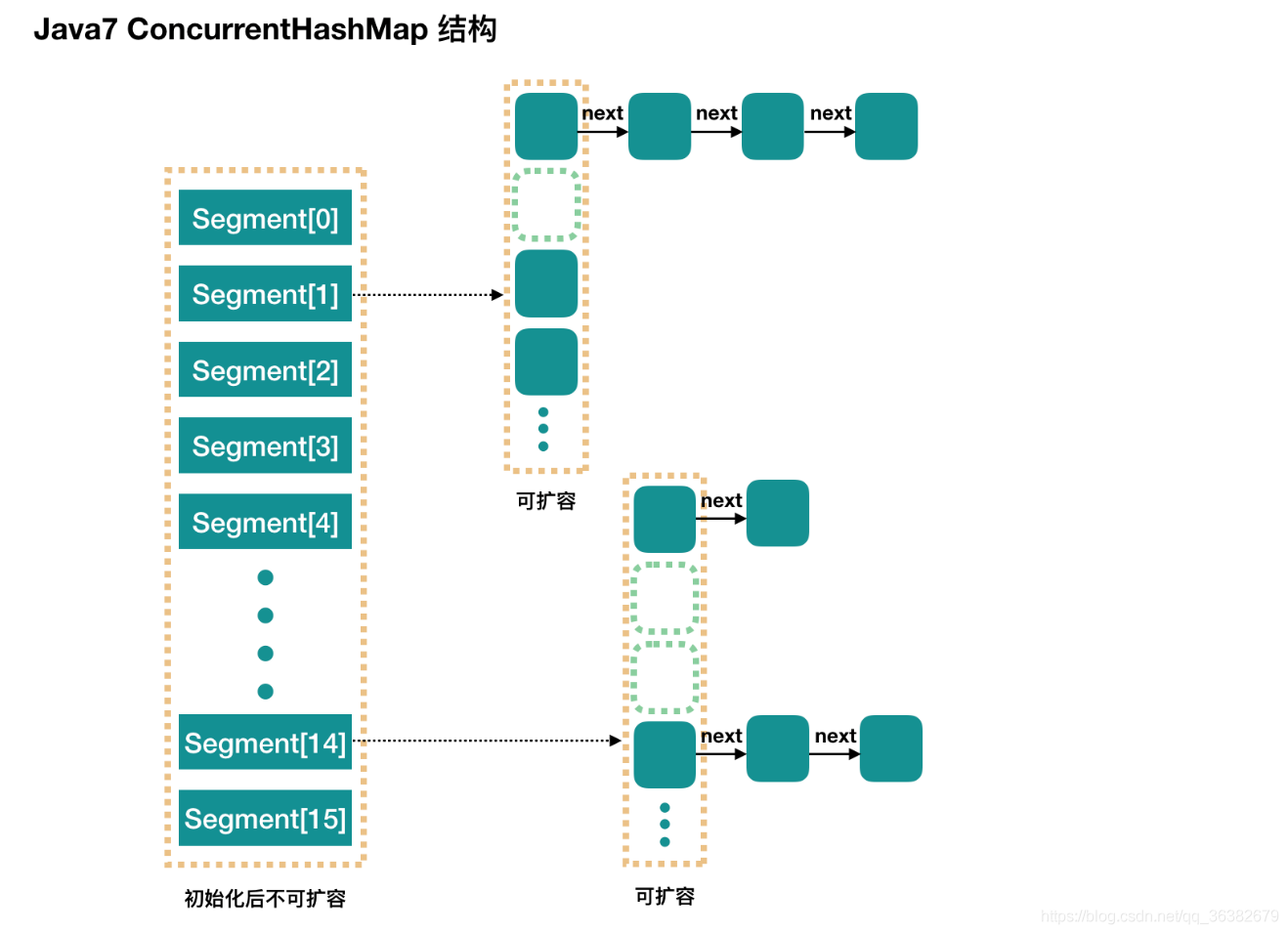
由上,jdk1.7中ConcurretHashMap=Segment类数组,每个Segment元素=HashEntry类数组=类似一个hashMap结构,每个HashEntry元素=链表;当多线程并发时,锁住的是单个Segment元素(Segment继承ReentrantLock,此处jdk1.7使用的是ReentrantLock的非公平锁),但即使是单个Segment元素,里面也含有一整个HashEntry数组(类似一个HashMap),所以锁住的是一整个HashEntry数组,故并发度也没有那么高 - jdk1.8中的ConcurrenHashMap的底层结构=Node数组+链表+红黑树,put过程使用了Synchronized+CAS(调用Unsafe类的cas方法),结构如下:
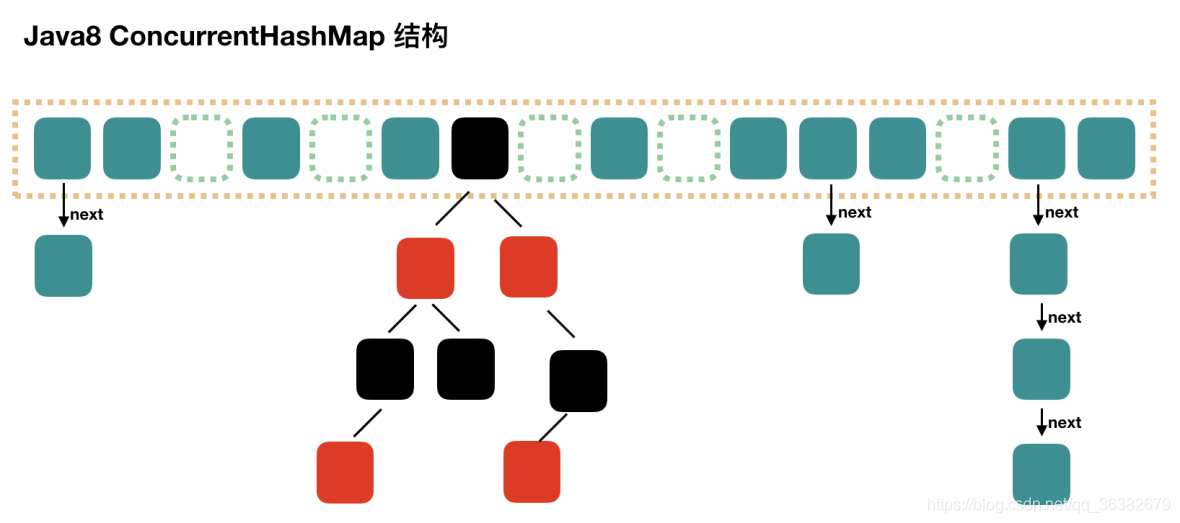
由上,jdk1.8中ConcurretHashMap类似于HashMap,它们都是数组+链表+红黑树,所有的操作都一样,唯一区别是ConcurretHashMap在具体某个桶的位置插入元素时,该位置的链表或红黑树会被同步访问【Synchronized(某桶的头节点)】,这样粒度比jdk1.7的更小了,锁住的是某个链表(或红黑树)
put方法的区别
jdk1.7中的put需定位两次:先定位要插入的元素在segment数组的下标,然后加锁去根据这个下标定位HashEntry数组的下标【key的hash值&HashEntry数组长度】,没有获得锁的线程做一些准备工作:
(1)提前找好HashEntry中桶的位置;
(2)遍历该桶有没有相同的key
进行(1)、(2)的同时不断自旋获取锁,超过64次还没获取到锁就挂起该线程jdk1.8中的put只需定位一次:
-->假如Node型table数组为空则初始化initTable()
-->table初始化完成,定位要插入元素所在的table[i]的位置,进一步判断table[i]为空则执行cas插入;
-->table[i]不为空且table[i].hash=-1,代表ConcurrentHashMap正在扩容,则加入扩容;
-->table[i].hash不为-1则直接插入,若是链表则插入到链表尾,若是红黑树则插入到红黑树
短时间内如何将大量数据高效地插入到ConcucurentHashMap?
以jdk1.8为例,影响concurrentHashMap插入元素的效率主要有两点:插入时频繁地扩容+插入时并发地访问:
(1)解决‘插入时频繁地扩容’:需选择合适的初始化容量和扩容因子
(2)解决‘插入时并发地访问’:插入节点时会对Node链表头节点加锁,然而锁也有'偏向锁...重量级锁',只要控制锁不发生升级,尽量保持在偏向锁状态,这样每个桶就只有一个线程访问,不会发生高并发从而提高插入效率。如何保持每个头结点加锁之后都是'偏向锁'状态呢?利用concurrentHashMap的spread()方法求key的hash值(预处理数据),将存在哈希冲突的key都集中地插入某个桶(可能会有多个桶-多个哈希冲突),因为每个桶都用单线程去put,从而没有其他线程去竞争同一个桶的锁,锁就一直为‘偏向锁’。
jdk1.8的put源码
final V putVal(K key, V value, boolean onlyIfAbsent) { //onlyIfAbsent默认传入false
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode()); //求key的hash值=预处理hashcode:便于将存在哈希冲突的key集中地插入某个桶
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0) //如果table为空则初始化数组
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //如果table非空则检查插入位置table[i]处的位置是否为空,若是则用cas插入Node节点
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED) //如果插入位置table[i]的头结点f的【hash值=fh】为-1则代表concurrentHashMap正在扩容,则加入扩容
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) { //以上情况都不是,则插入到链表或红黑树,该步直接把头结点synchronized加锁,这样锁住的就是单个链表或单个红黑树
if (tabAt(tab, i) == f) {
if (fh >= 0) {//判断该桶位置处是链表还是红黑树:头结点的hash值>=,代表该处是链表
binCount = 1;
for (Node<K,V> e = f;; ++binCount) { //binCount用于计算该链表的结点树,后面会用到判断binCount>8则转为红黑树
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {//key相同
oldVal = e.val;
if (!onlyIfAbsent) //onlyIfAbsent默认为false
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) { //插入到链表尾
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD) //TREEIFY_THRESHOLD默认8,判断链表结点数>=8则转为红黑树
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
//Node型数组table为空时,初始化
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
//sizeCtl默认为0,可有三种取值:-1代表table正被其他线程初始化;0代表table等待初始化;大于0代表table初始化完成
if ((sc = sizeCtl) < 0)
Thread.yield(); // -1代表table正被其他线程初始化,本线程让出时间片进入就绪状态
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { //SIZECTL默认为0:【this在SIZECTL偏移量处的值=默认0】与sc相比,若相等则将this在SIZECTL偏移量处的值置为-1,代表table正在被初始化【疑问:sizeCtl是不同于SIZECTL的,SIZECTL=-1但sizeCtl没有置-1,所以上面Thread.yield()应该永远执行不到?】
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;//sc默认为0,DEFAULT_CAPACITY=默认16
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2); //n=16,n >>> 2即n/4,所以sc=n-(n/4)=3n/4=0.75n=12
}
} finally {
sizeCtl = sc; //把sizeCtl置为12>0,代表table初始化完成
}
break;
}
}
return tab;
}
OK,如果文章哪里有错误或不足,欢迎各位留言。
创作不易,各位的「三连」是二少创作的最大动力!我们下期见!
集合篇-ConcurrentHashMap的更多相关文章
- JUC源码分析-集合篇(一)ConcurrentHashMap
JUC源码分析-集合篇(一)ConcurrentHashMap 1. 概述 <HashMap 源码详细分析(JDK1.8)>:https://segmentfault.com/a/1190 ...
- JUC源码分析-集合篇:并发类容器介绍
JUC源码分析-集合篇:并发类容器介绍 同步类容器是 线程安全 的,如 Vector.HashTable 等容器的同步功能都是由 Collections.synchronizedMap 等工厂方法去创 ...
- JUC源码分析-集合篇(四)CopyOnWriteArrayList
JUC源码分析-集合篇(四)CopyOnWriteArrayList Copy-On-Write 简称 COW,是一种用于程序设计中的优化策略.其基本思路是,从一开始大家都在共享同一个内容,当某个人想 ...
- 死磕 java集合之ConcurrentHashMap源码分析(三)
本章接着上两章,链接直达: 死磕 java集合之ConcurrentHashMap源码分析(一) 死磕 java集合之ConcurrentHashMap源码分析(二) 删除元素 删除元素跟添加元素一样 ...
- 【JAVA秒会技术之秒杀面试官】秒杀Java面试官——集合篇(一)
[JAVA秒会技术之秒杀面试官]秒杀Java面试官——集合篇(一) [JAVA秒会技术之秒杀面试官]JavaEE常见面试题(三) http://blog.csdn.net/qq296398300/ar ...
- JUC源码分析-集合篇(十)LinkedTransferQueue
JUC源码分析-集合篇(十)LinkedTransferQueue LinkedTransferQueue(LTQ) 相比 BlockingQueue 更进一步,生产者会一直阻塞直到所添加到队列的元素 ...
- JUC源码分析-集合篇(九)SynchronousQueue
JUC源码分析-集合篇(九)SynchronousQueue SynchronousQueue 是一个同步阻塞队列,它的每个插入操作都要等待其他线程相应的移除操作,反之亦然.SynchronousQu ...
- JUC源码分析-集合篇(八)DelayQueue
JUC源码分析-集合篇(八)DelayQueue DelayQueue 是一个支持延时获取元素的无界阻塞队列.队列使用 PriorityQueue 来实现. 队列中的元素必须实现 Delayed 接口 ...
- JUC源码分析-集合篇(七)PriorityBlockingQueue
JUC源码分析-集合篇(七)PriorityBlockingQueue PriorityBlockingQueue 是带优先级的无界阻塞队列,每次出队都返回优先级最高的元素,是二叉树最小堆的实现. P ...
随机推荐
- 用strace处理程序异常挂死情况
1. 环境: ubuntu 系统 + strace + vim 2.编写挂死程序:(参考博客) #include <stdio.h> #include <sys/types.h> ...
- 一图学Python
网上有这样一张图片,信息量很大,通常会被配上标题"一张图让你学会Python": 这张图流传甚广,但我没有找到明确的出处,图片上附带了 UliPad 的作者 Limodou 的信息 ...
- SpringBoot:自定义注解实现后台接收Json参数
0.需求 在实际的开发过程中,服务间调用一般使用Json传参的模式,SpringBoot项目无法使用@RequestParam接收Json传参 只有@RequestBody支持Json,但是每次为了一 ...
- 深入理解Java虚拟机-HotSpot虚拟机对象探秘
一.对象的创建过程 虚拟机遇到一条new指令时,首先将去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载.解析和初始化过.如果没有,那就先执行相应的类 ...
- jQuery--事件绑定|委派|切换
一.事件的绑定 1.事件的绑定介绍 事件绑定: bind(type,fn) 给当前对象绑定一个事件.例如:A.bind("click",fn);类似A.click(fn) unbi ...
- kafka中的回调函数
kafka客户端中使用了很多的回调方式处理请求.基本思路是将回调函数暂存到ClientRequest中,而ClientRequest会暂存到inFlightRequests中,当返回response的 ...
- promethues常用的函数
prometheus函数常用 时数据 (Instant vector): 包含一组时序,每个时序只有一个点,例如:http_requests_total区间数据 (Range vector): 包含一 ...
- 学习Apache(五)
apache目前主要有两种模式:prefork模式和worker模式: 1)prefork模式(默认模式) prefork是Unix平台上的默认(缺省)MPM,使用多个子进程,每个子进程只有一个线程 ...
- C++ | 程序编译连接原理
文章目录 预编译(生成*.i文件) 编译(生成*.s文件) 汇编(生成*.o文件,也叫目标文件) 链接(生成*.exe文件,也叫可执行文件) 汇编--目标文件 查看文件头 查看符号表 查看 .o 文件 ...
- Matlab解析LQR与MPC的关系
mathworks社区中的这个资料还是值得一说的. 1 openExample('mpc/mpccustomqp') 我们从几个角度来解析两者关系,简单的说就是MPC是带了约束的LQR. 在陈虹模型预 ...