关于cpu体系架构的一些有趣的故事分享
从排查一次匪夷所思的coredump,引出各种体系架构的差异。
本文中的所有内容来自学习DCC888的学习笔记或者自己理解的整理,如需转载请注明出处。周荣华@燧原科技
1 背景
从全世界有记载的第一台计算机Z1 (computer) - Wikipedia在1936年发明,到1946年冯诺依曼体系架构的清晰提出,计算机体系架构的演进虽然没有什么革命性的变化,但各种体系架构的微调还是很明显的。
发展到现在虽然存在X86/ARM/MIPS/ALPHA/PPC/RISC-V等多种门派,但实际的设计思想上,主要有两种,一种是基于X86的系统架构,另外一种就是其他系统架构。
为什么这么分?
因为X86的很多特性,基本上只有X86有,而其他体系架构基本上都是共享的另外一种。
例如CISC和RISC,字节对齐,变长指令和固定长度指令,指令寻址模式,等等。
现在用的各种体系架构,只有x86是复杂指令集,变长,内存访问可以不是字节对齐的(当然,对齐之后性能更好),没有固定的加载和保存指令,而是采用很多计算指令直接访问内存。
相对于x86,其他体系架构,包括ARM/MIPS/ALPHA/PPC/RISC-V,都是精简指令集,指令长度也是固定的,内存访问必须对齐,否则coredump,内存的访问只能通过有限的几个加载和保存指令进行,其他计算指令仅限于在寄存器上操作。
2 体系架构
计算机的体系架构,英文称为Computer architecture - Wikipedia,涉及的工作主要分三部分:
指令集、微架构和系统设计。
其中指令集相当于用户界面,是软件和硬件的接口。
微架构是指令集的具体实现。
系统设计主要是支撑微架构的内存、总线、功耗等设计。
下面的问题单就X86来阐述。
32位的处理器太古老,我们单说64位之后的故事。
x86-64 - Wikipedia讲述了x86-64的体系架构的微架构演进过程:
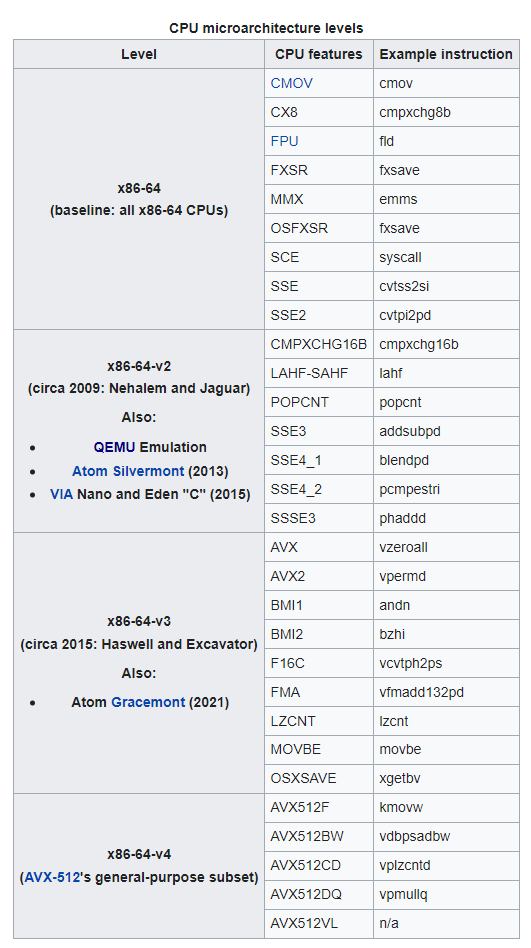
最早出来的是x86-64,相当于64位x86的基线版本,基本上所有64位x86处理器都支持,包括常见的MMX、SSE、FPU,都不是问题。基于这个基线版本往上发展出了v2/v3和v4版本。
现在虚拟机(QEMU)基本上支持到v2就终结了,所以后面v3/v4变成了少数用户的选择。随着这些微架构的演进,不仅指令集,寄存器也会有较大变化。那怎么保证编译出来的程序在各种x86的硬件上都能正常运行是个大问题。解决这个问题的主角就是编译器。
考虑到泛化和性能的不同要求,即使在同样的体系架构下,也可以指定具体的硬件版本,这就是gcc/clang等编译器的arch参数的由来。
x86 Options (Using the GNU Compiler Collection (GCC))中提到的arch的取值从各种具体的处理器型号,到泛化的v2/v3/v4,都是为了方便程序员可以尽可能保证兼容性的前提下,也能提升性能。
如果不考虑泛化,用户还可以简单用一个-march-native在x86平台上实现基于当前硬件的极致优化。
3 问题
这里碰到的一个问题就是极致优化带来的兼容性问题。
某服务器上编译出来的版本,在部分x86的机器上能正常运行,但部分x86机器上不能正常运行。通过gdb断点排查,报非法指令,而且代码段指向vxorps这条指令,后面紧跟着的3个寄存器非常扎眼zmm。
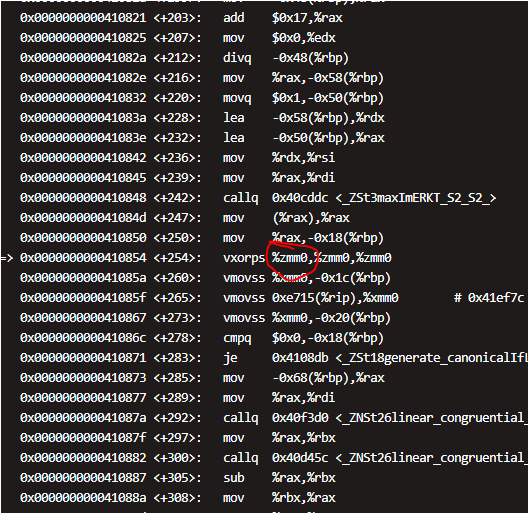
zmm寄存器是v4版本引入的功能。
能运行含zmm寄存器指令的cpu是“Intel(R) Xeon(R) Gold 6130 CPU @ 2.10GHz”,网上查了一下,是intel 2017年的产品。
到目前位置,MMX指令使用的寄存器经过了三代演进,xmm/ymm/zmm:
xmm0 ~ xmm15, are 128 bits, almost every modern machine has it, they are released in 1999.
ymm0 ~ ymm15, are 256 bits, new machine usually have it, they are released in 2011.
zmm0 ~ zmm31, are 512 bits, normal pc probably don't have it (as the year 2016),
由于后一代的寄存器长度是上一代的两倍,决定了前一代处理器是无法使用后一代处理器的寄存器的,相反,本地如果是更高一级的寄存器,可以运行低级的寄存器相关指令。
同样的代码,都指定-march=native的情况下,在“AMD Ryzen Threadripper 3960X 24-Core Processor”上编译的结果是这样的,指令本身没有变,寄存器从zmm变成了xmm。
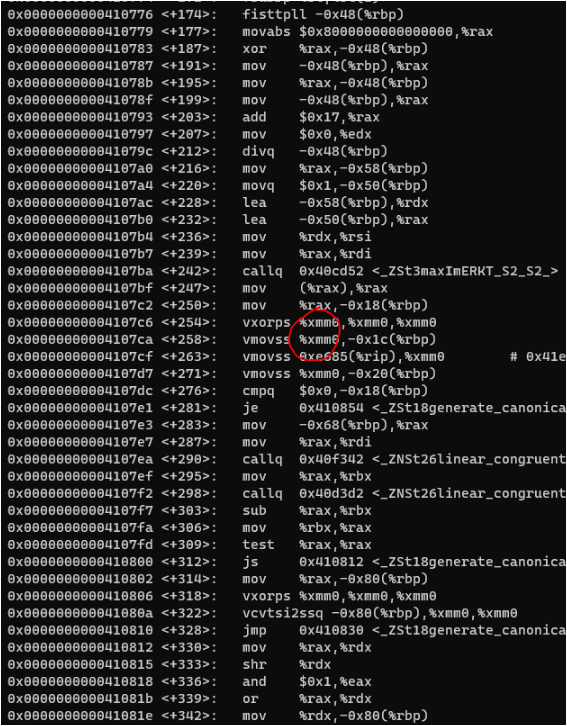
4 问题的解决
既然知道是gcc的arch指定有问题导致的,就要从修改arch入手。
做了一些实验,例如下面左边是-march=native编译,右边是-march=x86-64的结果。可以看出native编译出来使用incl,相对于addl,使指令更短,性能更好。

最终各种实验对比结果看结论如下:
-m64 -march=x86-64 -mtune=generic 编译出来的结果使用xmm寄存器
-march=native 编译出来的结果,在amd服务器上是xmm寄存器,在intel服务器上是zmm寄存器
为了保证兼容性,先统一用-m64 -march=x86-64 -mtune=generic 进行编译。
5 怎么做的更好
由于大多数编译器还不支持-march=x86-64-v2等直接选择x86-64具体版本的选项,有一种折中方案是native-avx512的做法,一般参数是这样的:
add_compile_options (-march=native)
add_compile_options (-mno-avx512f)
这样写的意思是其他方面可以尽量用本地能支持的最新的,但不要使用avx512f的功能,约等于x86-64-v3这个arch参数的功能。
关于cpu体系架构的一些有趣的故事分享的更多相关文章
- 【转】XenServer体系架构解析
XenServer是一套已在云计算环境中经过验证的企业级开放式服务器虚拟化解决方案,可以将静态.复杂的IT环境转变为更加动态.易于管理的虚拟数据中心,从而大大降低数据中心成本.同时,它可以提供先进的管 ...
- 面向服务体系架构(SOA)和数据仓库(DW)的思考基于 IBM 产品体系搭建基于 SOA 和 DW 的企业基础架构平台
面向服务体系架构(SOA)和数据仓库(DW)的思考 基于 IBM 产品体系搭建基于 SOA 和 DW 的企业基础架构平台 当前业界对面向服务体系架构(SOA)和数据仓库(Data Warehouse, ...
- 基于物联网操作系统HelloX的智慧家庭体系架构
基于物联网操作系统HelloX的智慧家庭体系架构 智慧家庭是物联网的一个分支应用,是一个被广泛认同的巨大IT市场空间.目前市场上已经有很多针对智慧家庭的产品或解决方案,但与移动互联网不同,智慧家庭至今 ...
- [转]OpenContrail 体系架构文档
OpenContrail 体系架构文档 英文原文:http://opencontrail.org/opencontrail-architecture-documentation/ 翻译者:@KkBLu ...
- InnoDB引擎体系架构
InnoDB引擎架构介绍 innodb存储引擎的体系架构,可简单划分成三层: 数据文件 :磁盘上的数据文件 内存池:缓存磁盘上的数据,方便读取,同时在对磁盘文件数据修改之前在这里缓存,然后按一定规刷新 ...
- InnoDB体系架构(二)内存
InnoDB体系架构(二)内存 上篇文章 InnoDB体系架构(一)后台线程 介绍了MySQL InnoDB存储引擎后台线程:Master Thread.IO Thread.Purge Thread. ...
- InnoDB体系架构
MySQL支持插件式存储引擎,常用的存储引擎则是MyISAM和InnoDB,通常在OLTP(Online Transaction Processing 在线事务处理)中,我们选择使用InnoDB,所以 ...
- NUMA 体系架构
NUMA 体系架构 SMP 体系架构 NUMA 体系架构 NUMA 结构基本概念 Openstack flavor NUMA 策略 Nova 实现 NUMA 流程 1. SMP 体系架构 CPU 计算 ...
- 面向服务体系架构(SOA)和数据仓库(DW)的思考
摘要: 当前业界对面向服务体系架构(SOA)和数据仓库(Data Warehouse,DW)都介绍的很多,提出了很多优秀的解决方案,但是一般是把 SOA 和 DW 单独考虑,SOA 和 DW 有着共同 ...
随机推荐
- Vue_transition动画
1 <!DOCTYPE html> 2 <html lang="en" xmlns:v-on="http://www.w3.org/1999/xhtml ...
- Vue_基础功能循环、计算、绑定、事件处理、组件
1 <!DOCTYPE html> 2 <html lang="en" xmlns:v-bind="http://www.w3.org/1999/xht ...
- CV技术指南免费版知识星球
最近公众号的交流群满了,我们决定搞一个免费的知识星球,让大家在里面交流.以往都是我们写原创,大家阅读,读者之间没什么交流.与此同时,在CV技术指南交流群里,大部分问题都得到了很好地解决,但从来没有 ...
- C语言超全学习路线(收藏让你少走弯路)
刚入门是否觉得C语言很难?那可能是你还没找到正确的C语言学习路线,收藏以防找不到,让你少走弯路. 基本语法 选择控制语句 if,swith 循环控制语句 while,for 控制语句相关关键字分析 变 ...
- XCTF练习题---CRYPTO---Railfence解析
XCTF练习题---CRYPTO---Morse解析 flag:cyberpeace{railfence_cipher_gogogo} 解题步骤: 1.观察题目,下载附件进行查看 2.根据题目提示,发 ...
- HCNP Routing&Switching之Super VLAN
前文我们了解了VLAN隔离技术MUX VLAN相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/16196936.html:今天我们来聊一聊VLAN优化S ...
- filter/backdrop-filter 毛玻璃效果
对于方式二采用的方式,如果存在边缘模糊程度不够,可以设置扩大伪元素范围(margin: -20px),父元素超出裁剪(overflow: hidden). <!DOCTYPE html> ...
- 拖动元素调换位置——sortable.js
使用简介: https://github.com/SortableJS/Sortable https://segmentfault.com/a/1190000008209715 /**! * Sort ...
- SpringBoot从0到0.7——第四天
SpringBoot从0到0.7--第四天 今天进行实战开发一个小项目,SpringBoot和Thymeleaf集成的小项目 因为懒得写写前端,直接找的别人的项目在它的的基础上进行配置,进行修改.gi ...
- 基于 range 的 for 循环和 auto
基于 range 的 for 循环和 auto C++11 引入一种循环的新形式,叫基于 range 的 for 循环,它允许我们用更简单易读的形式遍历容器中的所有元素 vector<int&g ...