7.Spark SQL
1.分析SparkSQL出现的原因,并简述SparkSQL的起源与发展。
SparkSQL出现是因为关系数据库已经不能满足各种在大数据时代新增的用户需求。首先,用户需要在不同的结构化和非结构化数据中执行各种操作。其次,用户需要执行像机器学习和图像处理等等高级分析,在实际应用中,也经常需要融合关系查询和分析复杂算法。而SparkSQL正好可以弥补这个缺陷。
起源
在三四年前,Hive可以说是SQL on Hadoop的唯一选择,负责将SQL编译成可扩展的MapReduce作业。鉴于Hive的性能以及与Spark的兼容,Shark项目由此而生。
Shark即Hive on Spark,本质上是通过Hive的HQL解析,把HQL翻译成Spark上的RDD操作,然后通过Hive的metadata获取数据库里的表信息,实际HDFS上的数据和文件,会由Shark获取并放到Spark上运算。Shark的最大特性就是快和与Hive的完全兼容,且可以在shell模式下使用rdd2sql()这样的API,把HQL得到的结果集,继续在scala环境下运算,支持自己编写简单的机器学习或简单分析处理函数,对HQL结果进一步分析计算。
发展
在2014年7月1日的Spark Summit上,Databricks宣布终止对Shark的开发,将重点放到Spark SQL上。
Databricks表示,Spark SQL将涵盖Shark的所有特性,用户可以从Shark 0.9进行无缝的升级。
Databricks推广的Shark相关项目一共有两个,分别是Spark SQL和新的Hive on Spark(HIVE-7292)
Databricks表示,Shark更多是对Hive的改造,替换了Hive的物理执行引擎,因此会有一个很快的速度。然而,不容忽视的是,Shark继承了大量的Hive代码,因此给优化和维护带来了大量的麻烦。
2.简述RDD 和DataFrame的联系与区别
联系:
1.都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利。
2、都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action才会运算。
3.都会根据spark的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
4、三者都有partition的概念。
5.三者有许多共同的函数,如filter,排序等。
区别:
RDD是分布式的java对象的集合,但是对象内部结构对于RDD而言却是不可知的。
DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息,相当于关系数据库中的一张表。
3.DataFrame的创建与保存
3.1 PySpark-DataFrame创建:
spark.read.text(url)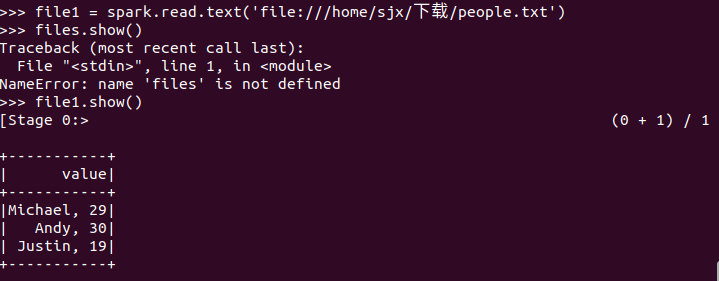
spark.read.json(url) 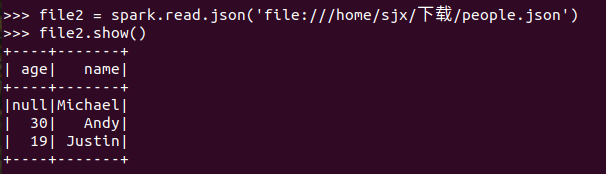
spark.read.format("text").load("people.txt")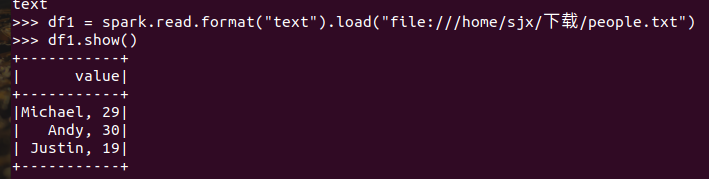
spark.read.format("json").load("people.json")
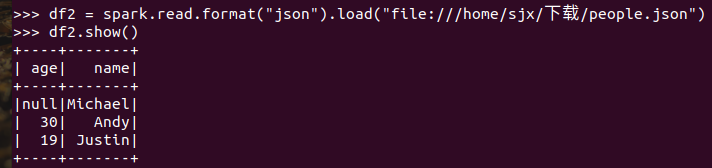
描述从不同文件类型生成DataFrame的区别。
text文件生成的DataFrame只有value属性;而json文件生成的DataFrame会识别到文件中的键值
用相同的txt或json文件,同时创建RDD,比较RDD与DataFrame的区别。


区别:RDD是直接输出对象,DataFrame是以对象里面的的详细结构进行输出
3.2 DataFrame的保存
df.write.text(dir)
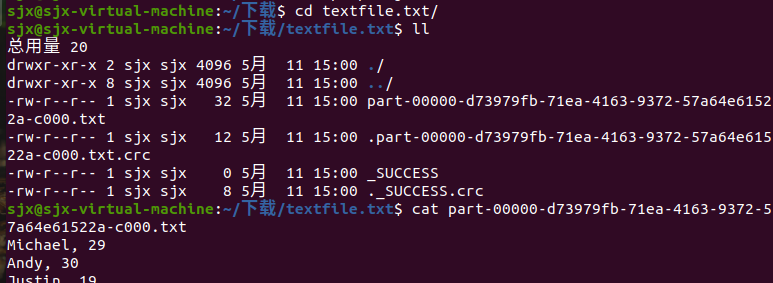
df.write.json(dri)
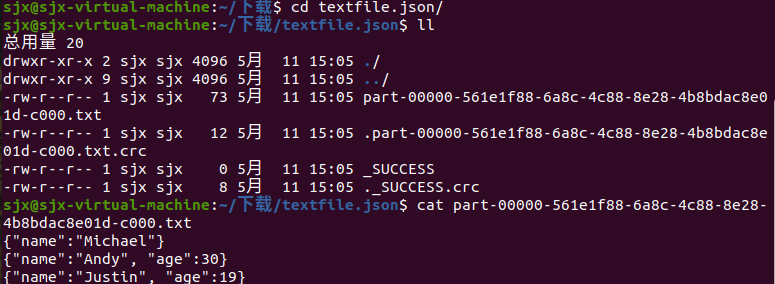
df.write.format("text").save(dir)
df.write.format("json").save(dir)
4.选择题
4.1单选(2分)关于Shark,下面描述正确的是:C
A.Shark提供了类似Pig的功能
B.Shark把SQL语句转换成MapReduce作业
C.Shark重用了Hive中的HiveQL解析、逻辑执行计划翻译、执行计划优化等逻辑
D.Shark的性能比Hive差很多
4.2单选(2分)下面关于Spark SQL架构的描述错误的是:D
A.在Shark原有的架构上重写了逻辑执行计划的优化部分,解决了Shark存在的问题
B.Spark SQL在Hive兼容层面仅依赖HiveQL解析和Hive元数据
C.Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责
D.Spark SQL执行计划生成和优化需要依赖Hive来完成
4.3单选(2分)要把一个DataFrame保存到people.json文件中,下面语句哪个是正确的:A
A.df.write.json("people.json")
B.df.json("people.json")
C.df.write.format("csv").save("people.json")
D.df.write.csv("people.json")
4.4多选(3分)Shark的设计导致了两个问题:AC
A.执行计划优化完全依赖于Hive,不方便添加新的优化策略
B.执行计划优化不依赖于Hive,方便添加新的优化策略
C.Spark是线程级并行,而MapReduce是进程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使 用另外一套独立维护的、打了补丁的Hive源码分支
D.Spark是进程级并行,而MapReduce是线程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使 用另外一套独立维护的、打了补丁的Hive源码分支
4.5 多选(3分)下面关于为什么推出Spark SQL的原因的描述正确的是:AB
A.Spark SQL可以提供DataFrame API,可以对内部和外部各种数据源执行各种关系操作
B.可以支持大量的数据源和数据分析算法,组合使用Spark SQL和Spark MLlib,可以融合传统关系数据库的结构化数据管理能力 和机器学习算法的数据处理能力
C.Spark SQL无法对各种不同的数据源进行整合
D.Spark SQL无法融合结构化数据管理能力和机器学习算法的数据处理能力
4.6多选(3分)下面关于DataFrame的描述正确的是:ABCD
A.DataFrame的推出,让Spark具备了处理大规模结构化数据的能力
B.DataFrame比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能
C.Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询
D.DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息
4.7多选(3分)要读取people.json文件生成DataFrame,可以使用下面哪些命令:AC
A.spark.read.json("people.json")
B.spark.read.parquet("people.json")
C.spark.read.format("json").load("people.json")
D.spark.read.format("csv").load("people.json")
5. PySpark-DataFrame各种常用操作
5.1基于df的操作:
打印数据 df.show()默认打印前20条数据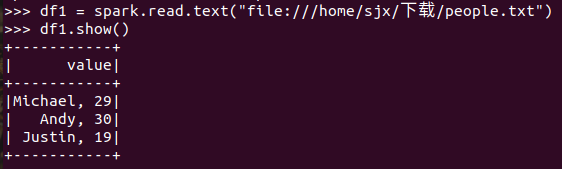
打印概要 df.printSchema()

查询总行数 df.count()

df.head(3) #list类型,list中每个元素是Row类

输出全部行 df.collect() #list类型,list中每个元素是Row类

查询概况 df.describe().show()

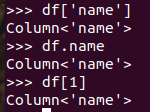
取列 df[‘name’], df.name, df[1]
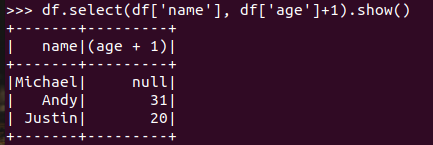
选择 df.select() 每个人的年龄+1
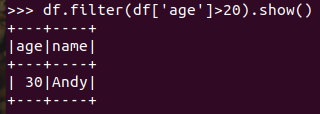
筛选 df.filter() 20岁以上的人员信息
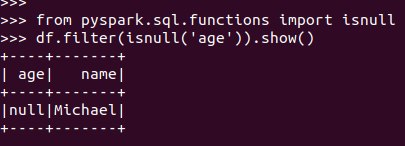
筛选年龄为空的人员信息
分组df.groupBy() 统计每个年龄的人数

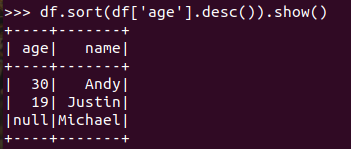
排序df.sortBy() 按年龄进行排序
5.2 基于spark.sql的操作
创建临时表 df.registerTempTable('people')

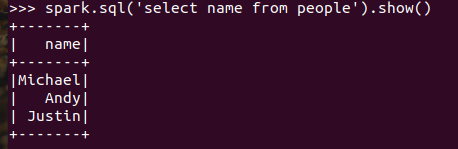
spark.sql执行SQL语句 spark.sql('select name from people').show()
5.3 pyspark中DataFrame与pandas中DataFrame
分别从文件创建两种DataFrame
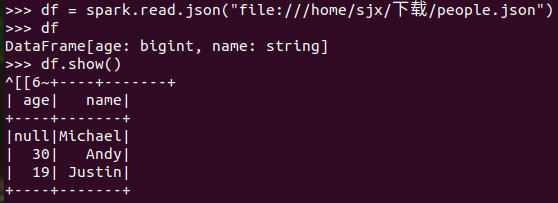
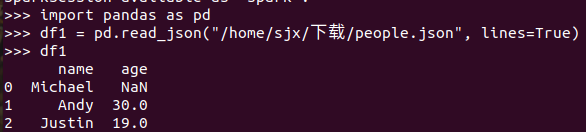
查看两种df的区别
pandas中DataFrame转换为Pyspark中DataFrame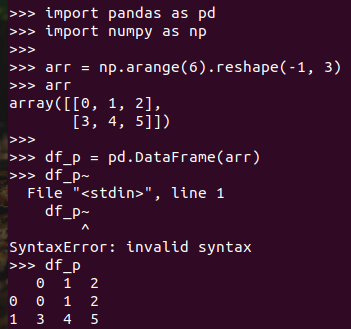
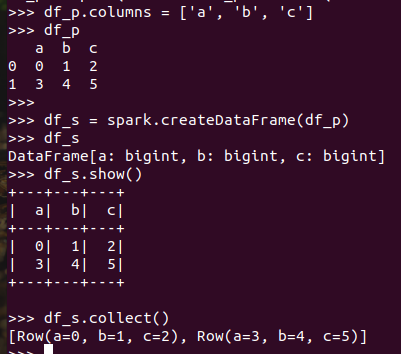
Pyspark中DataFrame转换为pandas中DataFrame
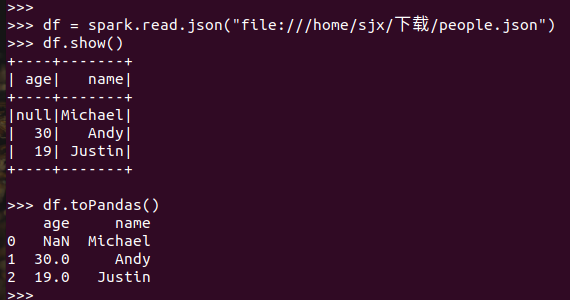
7.从RDD转换得到DataFram:
7.1 利用反射机制推断RDD模式
创建RDD sc.textFile(url).map(),读文件,分割数据项
每个RDD元素转换成 Row
由Row-RDD转换到DataFrame
7.2 使用编程方式定义RDD模式
#下面生成“表头” 
#下面生成“表中的记录” 
#下面把“表头”和“表中的记录”拼装在一起
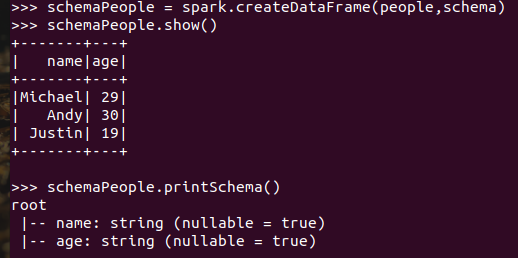
8.选择题:
8.1单选(2分)以下操作中,哪个不是DataFrame的常用操作: D
A.printSchema()
B.select()
C.filter()
D.sendto()
8.2多选(3分)从RDD转换得到DataFrame包含两种典型方法,分别是: AB
A.利用反射机制推断RDD模式
B.使用编程方式定义RDD模式
C.利用投影机制推断RDD模式
D.利用互联机制推断RDD模式
8.3多选(3分)使用编程方式定义RDD模式时,主要包括哪三个步骤: ABC
A.制作“表头”
B.制作“表中的记录”
C.制作映射表
D.把“表头”和“表中的记录”拼装在一起
7.Spark SQL的更多相关文章
- Spark SQL 之 Data Sources
#Spark SQL 之 Data Sources 转载请注明出处:http://www.cnblogs.com/BYRans/ 数据源(Data Source) Spark SQL的DataFram ...
- Spark SQL 之 DataFrame
Spark SQL 之 DataFrame 转载请注明出处:http://www.cnblogs.com/BYRans/ 概述(Overview) Spark SQL是Spark的一个组件,用于结构化 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
Spark版本:1.6.2 概览 Spark SQL用于处理结构化数据,与Spark RDD API不同,它提供更多关于数据结构信息和计算任务运行信息的接口,Spark SQL内部使用这些额外的信息完 ...
- Spark SQL Example
Spark SQL Example This example demonstrates how to use sqlContext.sql to create and load a table ...
- 通过Spark SQL关联查询两个HDFS上的文件操作
order_created.txt 订单编号 订单创建时间 -- :: -- :: -- :: -- :: -- :: order_picked.txt 订单编号 订单提取时间 -- :: ...
- Spark SQL 之 Migration Guide
Spark SQL 之 Migration Guide 支持的Hive功能 转载请注明出处:http://www.cnblogs.com/BYRans/ Migration Guide 与Hive的兼 ...
- Spark SQL 官方文档-中文翻译
Spark SQL 官方文档-中文翻译 Spark版本:Spark 1.5.2 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 Data ...
- Spark SQL 之 Performance Tuning & Distributed SQL Engine
Spark SQL 之 Performance Tuning & Distributed SQL Engine 转载请注明出处:http://www.cnblogs.com/BYRans/ 缓 ...
- 基于Spark1.3.0的Spark sql三个核心部分
基于Spark1.3.0的Spark sql三个核心部分: 1.可以架子啊各种结构化数据源(JSON,Hive,and Parquet) 2.可以让你通过SQL,saprk内部程序或者外部攻击,通过标 ...
随机推荐
- 2021.07.17 P3177 树上染色(树形DP)
2021.07.17 P3177 树上染色(树形DP) [P3177 HAOI2015]树上染色 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 重点: 1.dp思想是需要什么,维护 ...
- Java数组-2022年4月17日
目录 数组 数组Array 数组的常见异常 数组的遍历 数组的扩容 数组类型的返回值 可变长数组 排序算法 二维数组 测试代码 数组 数组Array ArrayList概念:一个连续的空间,存储多个相 ...
- Python获取文件夹下的所有文件名
1 #获取文件夹内的图片 2 import os 3 def get_imlist(path): 4 return [os.path.join(path,f) for f in os.listdir( ...
- 前后端分离后台管理系统 Gfast v3.0 全新发布
GFast V3.0 平台简介 基于全新Go Frame 2.0+Vue3+Element Plus开发的全栈前后端分离的管理系统 前端采用vue-next-admin .Vue.Element UI ...
- css3 做出顶边倾斜的 梯形 div
效果图: <html> <head> <meta charset="utf-8"> <title>顶边倾斜的div梯形</ti ...
- CAS如何解决ABA问题
点赞再看,养成习惯,微信搜索「小大白日志」关注这个搬砖人. 文章不定期同步公众号,还有各种一线大厂面试原题.我的学习系列笔记. CAS如何解决ABA问题 什么是ABA:在CAS过程中,线程1.线程2分 ...
- python学习-Day20
目录 今日内容详细 作业讲解 re模块补充说明 findall的优先级查询 通过索引的方式单独获取分组内匹配到的数据 分组之后还可以给组起别名 split的优先级查询 collections模块 具名 ...
- lab_1 清华大学ucore bootload启动ucore os(预备基础知识+实验过程)
实验1 :bootload启动ucore os 1.0实验内容: lab1中包含一个bootloader和一个OS.这个bootloader可以切换到X86保护模式,能够读磁盘并加载ELF执行文件格式 ...
- Linux_yum源仓库-本地-网络-练习实验
1.本地光盘挂载使用yum源 实验环境centos8 系统版本CentOS-8.3.2011-x86_64-dvd1 1)配置前检查 1.1 虚拟机设置选择对应版本镜像文件 1.2 启动虚拟机后处于连 ...
- Java 14中对switch的增强,终于可以不写break了
面对这样的if语句,你是不是很难受呢? if (flag == 1) { log.info("didispace.com: 1"); } else if (flag == 2) { ...