Python实现XMind测试用例快速转Excel用例
转载请注明出处️
作者:测试蔡坨坨
原文链接:caituotuo.top/c2d10f21.html
你好,我是测试蔡坨坨。
今天分享一个Python编写的小工具,实现XMind测试用例转Excel用例。
前言
XMind和Excel是在日常测试工作中最常用的两种用例编写形式,两者也有各自的优缺点。
使用XMind编写测试用例更有利于测试思路的梳理,以及更加便捷高效,用例评审效率更高,但是由于每个人使用XMind的方式不同,设计思路也不一样,可能就不便于其他人执行和维护。
使用Excel编写测试用例由于有固定的模板,所以可能更加形式化和规范化,更利于用例管理和维护,以及让其他人更容易执行用例,但是最大的缺点就是需要花费更多的时间成本。
由于项目需要,需要提供Excel形式的测试用例,同时编写两种形式的测试用例显然加大了工作量,于是写了个Python脚本,可快速将XMind用例转换成Excel用例。
设计思路
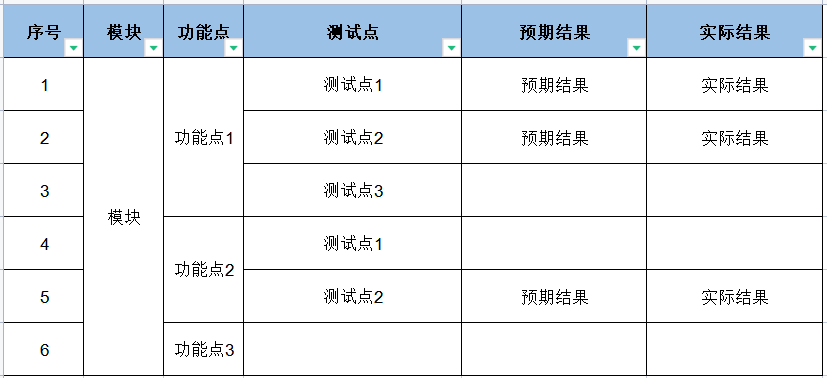
Excel测试用例模板样式如下图所示:

表头固定字段:序号、模块、功能点
为了让脚本更加灵活,后面的字段会根据XMind中每一个分支的长度自增,例如:测试点/用例标题、预期结果、实际结果、前置条件、操作步骤、优先级、编写人、执行人等
根据Excel模板编写对应的XMind测试用例:
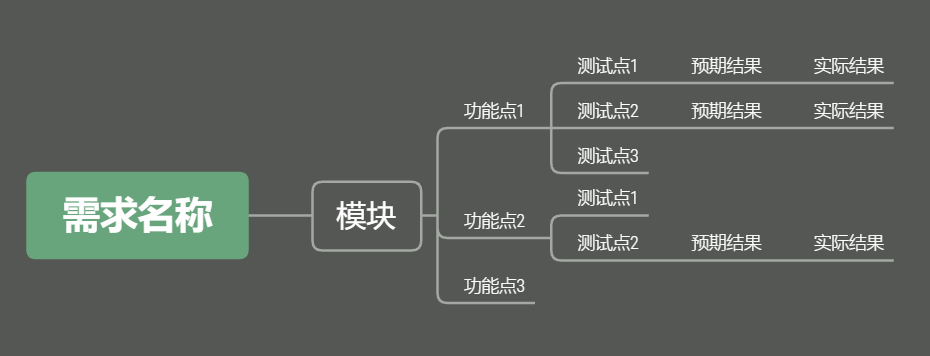
实现:
将XMind中的每一条分支作为一条序号的用例,再将每个字段写入Excel中的每一个单元格中
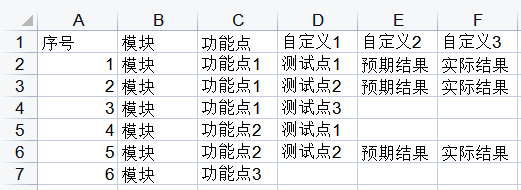
再手动调整美化一下表格:
完整代码
# author: 测试蔡坨坨
# datetime: 2022/8/16 22:44
# function: XMind转Excel
from typing import List, Any
import xlwt
from xmindparser import xmind_to_dict
def resolve_path(dict_, lists, title):
"""
通过递归取出每个主分支下的所有小分支并将其作为一个列表
:param dict_:
:param lists:
:param title:
:return:
"""
# 去除title首尾空格
title = title.strip()
# 若title为空,则直接取value
if len(title) == 0:
concat_title = dict_["title"].strip()
else:
concat_title = title + "\t" + dict_["title"].strip()
if not dict_.__contains__("topics"):
lists.append(concat_title)
else:
for d in dict_["topics"]:
resolve_path(d, lists, concat_title)
def xmind_to_excel(list_, excel_path):
f = xlwt.Workbook()
# 生成单sheet的Excel文件,sheet名自取
sheet = f.add_sheet("XX模块", cell_overwrite_ok=True)
# 第一行固定的表头标题
row_header = ["序号", "模块", "功能点"]
for i in range(0, len(row_header)):
sheet.write(0, i, row_header[i])
# 增量索引
index = 0
for h in range(0, len(list_)):
lists: List[Any] = []
resolve_path(list_[h], lists, "")
# print(lists)
# print('\n'.join(lists)) # 主分支下的小分支
for j in range(0, len(lists)):
# 将主分支下的小分支构成列表
lists[j] = lists[j].split('\t')
# print(lists[j])
for n in range(0, len(lists[j])):
# 生成第一列的序号
sheet.write(j + index + 1, 0, j + index + 1)
sheet.write(j + index + 1, n + 1, lists[j][n])
# 自定义内容,比如:测试点/用例标题、预期结果、实际结果、操作步骤、优先级……
# 这里为了更加灵活,除序号、模块、功能点的标题固定,其余以【自定义+序号】命名,如:自定义1,需生成Excel表格后手动修改
if n >= 2:
sheet.write(0, n + 1, "自定义" + str(n - 1))
# 遍历完lists并给增量索引赋值,跳出for j循环,开始for h循环
if j == len(lists) - 1:
index += len(lists)
f.save(excel_path)
def run(xmind_path):
# 将XMind转化成字典
xmind_dict = xmind_to_dict(xmind_path)
# print("将XMind中所有内容提取出来并转换成列表:", xmind_dict)
# Excel文件与XMind文件保存在同一目录下
excel_name = xmind_path.split('\\')[-1].split(".")[0] + '.xlsx'
excel_path = "\\".join(xmind_path.split('\\')[:-1]) + "\\" + excel_name
print(excel_path)
# print("通过切片得到所有分支的内容:", xmind_dict[0]['topic']['topics'])
xmind_to_excel(xmind_dict[0]['topic']['topics'], excel_path)
if __name__ == '__main__':
xmind_path_ = r"F:\Desktop\coder\python_operate_files\用例模板.xmind"
run(xmind_path_)
代码解析
1. 调用xmind_to_dict()方法将XMind中所有内容取出并转成字典
xmind_dict = xmind_to_dict(xmind_path)
[{'title': '画布 1', 'topic': {'title': '需求名称', 'topics': [{'title': '模块', 'topics': [{'title': '功能点1', 'topics': [{'title': '测试点1', 'topics': [{'title': '预期结果', 'topics': [{'title': '实际结果'}]}]}, {'title': '测试点2', 'topics': [{'title': '预期结果', 'topics': [{'title': '实际结果'}]}]}, {'title': '测试点3'}]}, {'title': '功能点2', 'topics': [{'title': '测试点1'}, {'title': '测试点2', 'topics': [{'title': '预期结果', 'topics': [{'title': '实际结果'}]}]}]}, {'title': '功能点3'}]}]}, 'structure': 'org.xmind.ui.logic.right'}]
2. 通过切片得到所有分支的内容
xmind_dict[0]['topic']['topics']
[{'title': '模块', 'topics': [{'title': '功能点1', 'topics': [{'title': '测试点1', 'topics': [{'title': '预期结果', 'topics': [{'title': '实际结果'}]}]}, {'title': '测试点2', 'topics': [{'title': '预期结果', 'topics': [{'title': '实际结果'}]}]}, {'title': '测试点3'}]}, {'title': '功能点2', 'topics': [{'title': '测试点1'}, {'title': '测试点2', 'topics': [{'title': '预期结果', 'topics': [{'title': '实际结果'}]}]}]}, {'title': '功能点3'}]}]
3. 通过递归取出每个主分支下的所有小分支并将其作为一个列表
def resolve_path(dict_, lists, title):
"""
通过递归取出每个主分支下的所有小分支并将其作为一个列表
:param dict_:
:param lists:
:param title:
:return:
"""
# 去除title首尾空格
title = title.strip()
# 若title为空,则直接取value
if len(title) == 0:
concat_title = dict_["title"].strip()
else:
concat_title = title + "\t" + dict_["title"].strip()
if not dict_.__contains__("topics"):
lists.append(concat_title)
else:
for d in dict_["topics"]:
resolve_path(d, lists, concat_title)
for h in range(0, len(list_)):
lists: List[Any] = []
resolve_path(list_[h], lists, "")
print(lists)
print('\n'.join(lists)) # 主分支下的小分支
for j in range(0, len(lists)):
# 将主分支下的小分支构成列表
lists[j] = lists[j].split('\t')
print(lists[j])
lists:
['模块\t功能点1\t测试点1\t预期结果\t实际结果', '模块\t功能点1\t测试点2\t预期结果\t实际结果', '模块\t功能点1\t测试点3', '模块\t功能点2\t测试点1', '模块\t功能点2\t测试点2\t预期结果\t实际结果', '模块\t功能点3']
主分支下的小分支:
模块 功能点1 测试点1 预期结果 实际结果
模块 功能点1 测试点2 预期结果 实际结果
模块 功能点1 测试点3
模块 功能点2 测试点1
模块 功能点2 测试点2 预期结果 实际结果
模块 功能点3
将主分支下的小分支构成列表:
['模块', '功能点1', '测试点1', '预期结果', '实际结果']
['模块', '功能点1', '测试点2', '预期结果', '实际结果']
['模块', '功能点1', '测试点3']
['模块', '功能点2', '测试点1']
['模块', '功能点2', '测试点2', '预期结果', '实际结果']
['模块', '功能点3']
4. 写入Excel(生成单sheet的Excel文件、生成固定的表头标题、列序号取值、固定标题外的自定义标题)
f = xlwt.Workbook()
# 生成单sheet的Excel文件,sheet名自取
sheet = f.add_sheet("签署模块", cell_overwrite_ok=True)
# 第一行固定的表头标题
row_header = ["序号", "模块", "功能点"]
for i in range(0, len(row_header)):
sheet.write(0, i, row_header[i])
for n in range(0, len(lists[j])):
# 生成第一列的序号
sheet.write(j + index + 1, 0, j + index + 1)
sheet.write(j + index + 1, n + 1, lists[j][n])
# 自定义内容,比如:测试点/用例标题、预期结果、实际结果、操作步骤、优先级……
# 这里为了更加灵活,除序号、模块、功能点的标题固定,其余以【自定义+序号】命名,如:自定义1,需生成Excel表格后手动修改
if n >= 2:
sheet.write(0, n + 1, "自定义" + str(n - 1))
Python实现XMind测试用例快速转Excel用例的更多相关文章
- 使用Python将xmind脑图转成excel用例(一)
最近接到一个领导需求,将xmind脑图直接转成可以导入的excel用例,并且转换成gui可执行的exe文件,方便他人使用. 因为对Python比较熟悉,所以就想使用Python来实现这个功能,先理一下 ...
- python中将xmind转成excel
需求:最近公司项目使用tapd进行管理,现在遇到的一个难题就是,使用固定的模板编写测试用例,使用excel导入tapd进行测试用例管理,觉得太过麻烦,本人一直喜欢使用导图来写测试用例,故产生了这个工具 ...
- 测试用例逐步演进-xmind2excel(Python版)测试用例逐步演进-xmind2excel(Python版)
最近,我在做项目的时候,经常被问到一个问题:如何做测试评审会更有效呢? 只要做过测试用例评审,特别是比较复杂的测试用例评审的时候,很多测试同学都会苦恼于如何能更有效的向大家说出自己的测试设计思路. 当 ...
- python:利用xlrd模块操作excel
在自动化测试过程中,对测试数据的管理和维护是一个不可忽视的点.一般来说,如果测试用例数据不是太多的话,使用excel管理测试数据是个相对来说不错的选择. 这篇博客,介绍下如何利用python的xlrd ...
- 对比3种接口测试的工具:jmeter+ant;postman;python的requests+unittest或requests+excel
这篇随笔主要是对比下笔者接触过的3种接口测试工具,从实际使用的角度来分析下3种工具各自的特点 分别为:jmeter.postman.python的requests+unittest或requests+ ...
- Python+Bottle+Sina SAE快速构建网站
Bottle是新生一代Python框架的代表,利用Bottle构建网站将十分简单. Sina SAE是国内较出名的云平台之一,十分适用于个人网站的开发或创业公司网站开发. 下面将介绍如果通过Pytho ...
- Python笔记:使用pywin32处理excel文件
因为前端同事须要批量的对excel文件做特殊处理,删除指定行,故写了此脚本.同一时候配合config.ini方便不熟悉py的同事使用 #!/usr/bin/env python #-*- coding ...
- Python解析Xmind工具
使用Xmind写用例 使用Python解析Xmind,统计用例个数 代码: from xmindparser import xmind_to_dict import tkinter as tk fro ...
- Ubuntu 如何为 XMind 添加快速启动方式和图标
目录 Ubuntu 如何为 XMind 添加快速启动方式和图标 Ubuntu 如何为 XMind 添加快速启动方式和图标 按照教程Ubuntu16.04LTS安装XMind8并创建运行图标进行Xmin ...
随机推荐
- BUUCTF-小明的保险箱
小明的保险箱 16进制打开可以发现存在一个RAR压缩包,压缩包里面应该就是flag文本 使用ARCHPR破解即可
- BSS应用程序云原生部署的8大挑战
云原生部署改变了软件开发.根据云原生计算基金会(CNCF)2021年年度调查,96%的组织正在使用或评估Kubernetes.更确切地说,560万开发者在使用Kubernetes,比去年增加了67%. ...
- nifi从入门到实战(保姆级教程)——环境篇
背景: 公司领导决定将各种基础数据的导入从代码中分离出来,用Apache Nifi替换.使开发者们更关注在业务上,而不用关心基础的由来. Apache Nifi对于整个团队都是一个全新的工具,之前大家 ...
- SAP 实例 13 Random Grouping with LOOP
REPORT demo_loop_group_by_random. CLASS demo DEFINITION. PUBLIC SECTION. CLASS-METHODS: main, class_ ...
- SAP BOM 读取
1.查找 物料号.工厂.物料描述. 表:MARA MARC MAKT 逻辑: 输入物料(选择选项)中的物料编号(MARA-MATNR)和 输入工厂(选择选项 ...
- JAVA设计模式总结—建造者模式
建造者模式 模式动机与定义 首先建造者模式的动机是为了创建复杂对象,简化传统的创建方法,提高创建的效率和可读性. 像图中的这个例子,用户的需求是驾驶一辆汽车,但是对于用户来说是不需要了解汽车装 ...
- 在Visual Studio Code 中配置Python 中文乱码问题
在Visual Studio Code 中配置Python 中文乱码问题 方法一:直接代码修改字符集 添加前四行代码 import io import sys #改变标准输出的默认编码 sys.std ...
- C4C中更方便的消息管理
- 虚拟机使用docker 外部机器无法访问端口问题
1,排查防火墙firewall-cmd --state 如果输出的是"not running"则FirewallD没有在运行,且所有的防护策略都没有启动,那么可以排除防火墙阻断连接 ...
- AI2(App Inventor 2) 离线版
介绍 我们的目标:搭建一个本地多用户的App Inventor 2 服务器目的:课堂教学,社团活动,兴趣学习优势:管理权限(用户管理,账号切换,资源打包),网络链接速度快,拥有配套服务.注意:每次退出 ...