DHorse日志收集原理
实现原理
基于k8s的日志收集主要有两种方案,一是使用daemoset,另一种是基于sidecar。两种方式各有优缺点,目前DHorse是基于daemoset实现的。如图1所示:
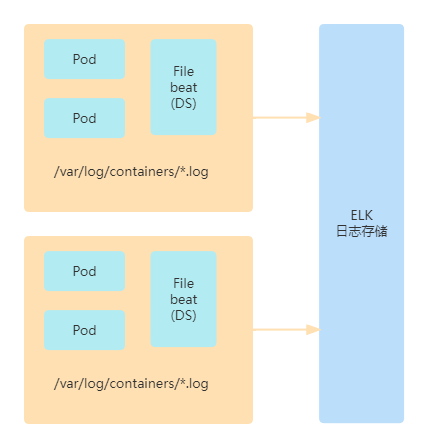
图1
在每个k8s集群中启动一个daemoset组件,即Filebeat的服务,监控/var/log/containers目录下的日志文件变动,然后把日志内容推送到ELK集群。
DHorse日志配置
在DHorse的安装目录conf子目录下,可以通过filebeat-k8s.yml文件进行日志收集的相关配置,如下:
---
apiVersion: v1
kind: ConfigMap
metadata:
# 默认名称,不允许修改
name: filebeat-config
# 默认命名空间,不允许修改
namespace: dhorse-system
labels:
# 默认标签名,不允许修改
app: filebeat
data:
filebeat.yml: |-
filebeat.inputs:
- type: container
paths:
- /var/log/containers/*.log
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
# To enable hints based autodiscover, remove `filebeat.inputs` configuration and uncomment this:
#filebeat.autodiscover:
# providers:
# - type: kubernetes
# node: ${NODE_NAME}
# hints.enabled: true
# hints.default_config:
# type: container
# paths:
# - /var/log/containers/*${data.kubernetes.container.id}.log
processors:
- add_cloud_metadata:
- add_host_metadata:
cloud.id: ${ELASTIC_CLOUD_ID}
cloud.auth: ${ELASTIC_CLOUD_AUTH}
output.elasticsearch:
hosts: ['${ELASTICSEARCH_HOST:elasticsearch}:${ELASTICSEARCH_PORT:9200}']
username: ${ELASTICSEARCH_USERNAME}
password: ${ELASTICSEARCH_PASSWORD}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
# 默认名称,不允许修改
name: filebeat
# 默认命名空间,不允许修改
namespace: dhorse-system
labels:
# 默认标签名,不允许修改
app: filebeat
spec:
selector:
matchLabels:
# 默认标签名,不允许修改
app: filebeat
template:
metadata:
labels:
# 默认标签名,不允许修改
app: filebeat
spec:
terminationGracePeriodSeconds: 30
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: filebeat
# 替换成你自己的filebeat镜像
image: docker.elastic.co/beats/filebeat:8.1.0
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
#替换成你自己的es地址和账号
env:
- name: ELASTICSEARCH_HOST
value: 127.0.0.1
- name: ELASTICSEARCH_PORT
value: "9200"
- name: ELASTICSEARCH_USERNAME
value: elastic
- name: ELASTICSEARCH_PASSWORD
value: changeme
- name: ELASTIC_CLOUD_ID
value:
- name: ELASTIC_CLOUD_AUTH
value:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
runAsUser: 0
# If using Red Hat OpenShift uncomment this:
#privileged: true
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: data
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: varlog
mountPath: /var/log
readOnly: true
- name: hosttime
mountPath: /etc/localtime
readOnly: true
volumes:
- name: config
configMap:
defaultMode: 0640
name: filebeat-config
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: varlog
hostPath:
path: /var/log
- name: hosttime
hostPath:
path: /etc/localtime
# data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart
- name: data
hostPath:
# When filebeat runs as non-root user, this directory needs to be writable by group (g+w).
path: /var/lib/filebeat-data
type: DirectoryOrCreate
然后,需要开启目标集群的日志开关即可,如图2所示:
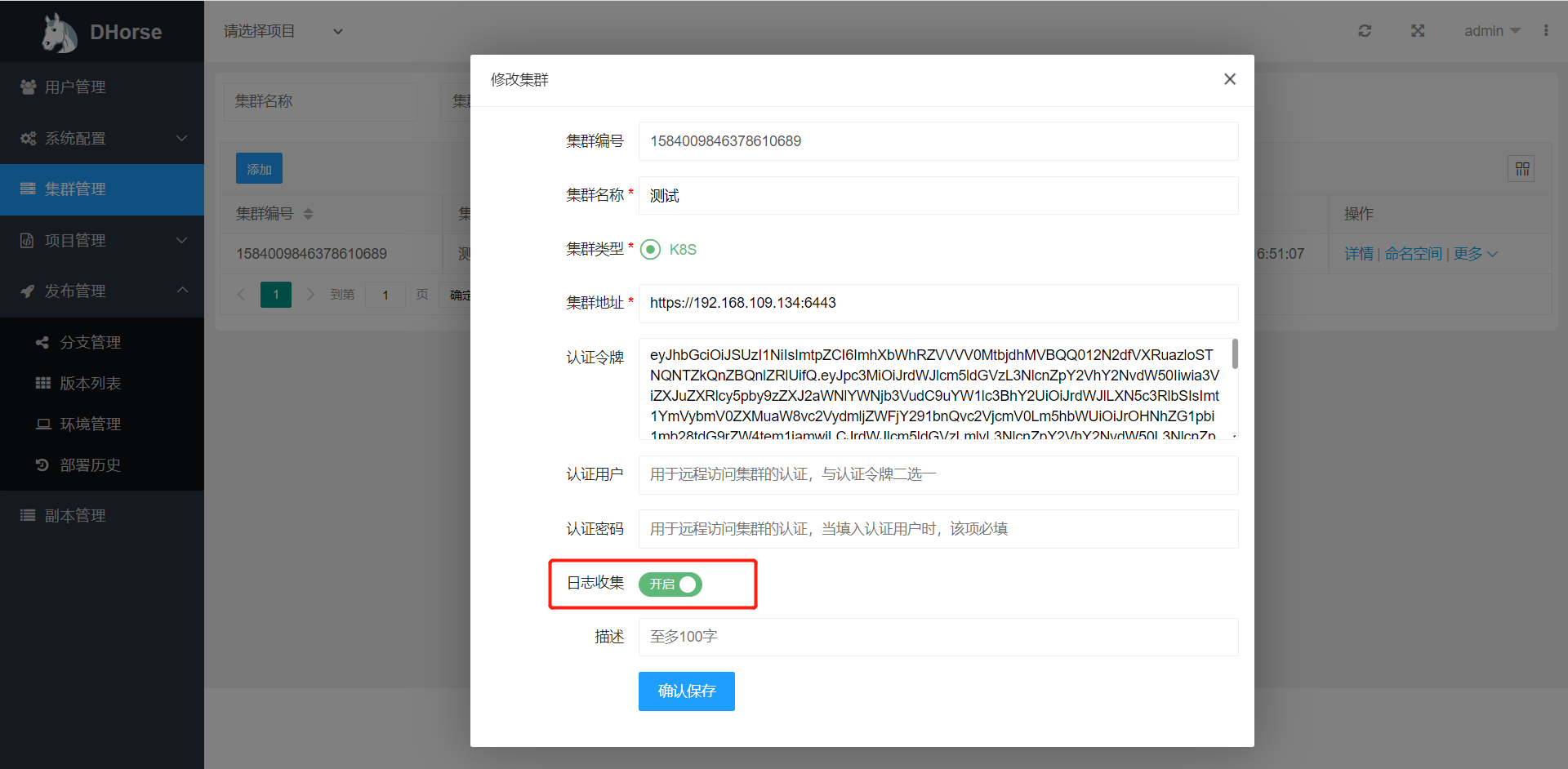
图2
DHorse日志收集原理的更多相关文章
- ELK分布式日志收集搭建和使用
大型系统分布式日志采集系统ELK全框架 SpringBootSecurity1.传统系统日志收集的问题2.Logstash操作工作原理3.分布式日志收集ELK原理4.Elasticsearch+Log ...
- 日志收集系统ELK搭建
一.ELK简介 在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常低下.因此我们需要集中化的管理 ...
- ELK 日志收集系统
传统系统日志收集的问题 在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常底下. 通常,日志被分 ...
- 网站统计中的数据收集原理及实现(share)
转载自:http://blog.codinglabs.org/articles/how-web-analytics-data-collection-system-work.html 网站数据统计分析工 ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- 用fabric部署维护kle日志收集系统
最近搞了一个logstash kafka elasticsearch kibana 整合部署的日志收集系统.部署参考lagstash + elasticsearch + kibana 3 + kafk ...
- 日志收集之kafka
日志收集之kafka http://www.jianshu.com/p/f78b773ddde5 一.介绍 Kafka是一种分布式的,基于发布/订阅的消息系统.主要设计目标如下: 以时间复杂度为O(1 ...
- Docker日志收集最佳实践
传统日志处理 说到日志,我们以前处理日志的方式如下: · 日志写到本机磁盘上 · 通常仅用于排查线上问题,很少用于数据分析 ·需要时登录到机器上,用grep.awk等工具分析 那么,这种方式有什么缺点 ...
- G1收集器的收集原理
G1收集器的收集原理 来源 http://blog.jobbole.com/109170/ JVM 8 内存模型 原文:https://blog.csdn.net/bruce128/article/d ...
- 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
作者:大数据女神-诺蓝(微信公号:dashujunvshen).本文是36大数据专稿,转载必须标明来源36大数据. 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要 ...
随机推荐
- mongodb集群搭建(分片+副本)开启安全认证
关于安全认证得总结: 这个讲述的步骤也是先创建超管用户,关闭服务,然后生成密钥文件,开启安全认证,启动服务 相关概念 先来看一张图: 从图中可以看到有四个组件:mongos.config server ...
- 2. 在 Kubernetes 上安装 Gitlab
总结: 所需要的三个yaml文件的下载地址:https://files.cnblogs.com/files/sanduzxcvbnm/k8s-gitlab.zip Gitlab官方提供了 Helm 的 ...
- 【前端必会】不知道webpack插件? webpack插件源码分析BannerPlugin
背景 不知道webpack插件是怎么回事,除了官方的文档外,还有一个很直观的方式,就是看源码. 看源码是一个挖宝的行动,也是一次冒险,我们可以找一些代码量不是很大的源码 比如webpack插件,我们就 ...
- Do not use “@ts-ignore” because it alters compilation errors的解决办法
在@ts-ignore上面添加一行代码: // eslint-disable-next-line @typescript-eslint/ban-ts-comment // @ts-ignore
- GitLab + Jenkins + Harbor 工具链快速落地指南
目录 一.今天想干啥? 二.今天干点啥? 三.今天怎么干? 3.1.常规打法 3.2.不走寻常路 四.开干吧! 4.1.工具链部署 4.2.网络配置 4.3.验证工具链部署结果 4.3.1.GitLa ...
- BigDecimal 用法总结
转载请注明出处: 目录 1.BigDecimal 简介 2.构造BigDecimal的对象 3.常用方法总结 4.divide方法使用 5.setScale 方法使用 6.BigDecimal 数据库 ...
- 实时营销引擎在vivo营销自动化中的实践 | 引擎篇04
作者:vivo 互联网服务器团队 本文是<vivo营销自动化技术解密>的第5篇文章,重点分析介绍在营销自动化业务中实时营销场景的背景价值.实时营销引擎架构以及项目开发过程中如何利用动态队列 ...
- Java一次返回中国所有省市区三级树形级联+前端vue展示【200ms内】
一.前言 中国省市区还是不少的,省有34个,市有391个,区有1101个,这是以小编的库里的,可能不是最新的,但是个数也差不了多少. 当一次返回所有的数据,并且还要组装成一个三级树,一般的for,会循 ...
- 11.MongoDB系列之连接副本集
1. Python连接副本集 from pymongo import MongoClient from bson.codec_options import CodecOptions from retr ...
- Vue学习之--------组件在Vue脚手架中的使用(代码实现)(2022/7/24)
文章目录 1.第一步编写组件 1.1 编写一个 展示学校的组件 1.2 定义一个展示学生的信息组件 2.第二步引入组件 3.制作一个容器 4.使用Vue接管 容器 5.实际效果 6.友情提示: 7.项 ...