MySQL优化之索引解析
索引的本质
MySQL索引或者说其他关系型数据库的索引的本质就只有一句话,以空间换时间。
索引的作用
索引关系型数据库为了加速对表中行数据检索的(磁盘存储的)数据结构
索引的分类
数据结构上面的分类
HASH 索引
- 等值匹配效率高
- 不支持范围查找
树形索引
二叉树,递归二分查找法,左小右大
平衡二叉树,二叉树到平衡二叉树,主要原因是左旋右旋
- 缺点1,IO次数过多
- 缺点2,IO利用率不高,IO饱和度
多路平衡查找树(B-Tree)
- 特点,大大的减少了树的高度
B+树
特点,采用左闭合的比较方式
根节点支节点没有数据区,只有叶子结点才包含数据区(说白了就是即便在根节点和子节点已经定位到,因为没有数据区的原因也不会停留,会一直找到叶子结点为止。)
- 当我们搜索13这条数据时,在根节点和子节点 都能定位,但是一直会找到叶子结点。

二叉树平衡二叉树,B树对比
如图显示如果是自增主键情况下:
二叉树显然不适合做关系型数据库索引(和全表扫描没什么区别)。
平衡二叉树呢,虽然解决了这种情况,但是同样会导致这棵树,又瘦又高,这同样会造成上文所提到查询IO次数过多以及IO利用率不高。
B树呢,显然已经解决了这两个问题,所以下文来解释,为什么在这种情况下MySQL还用了B+树,又做了那些增强。

B树和B+树比较
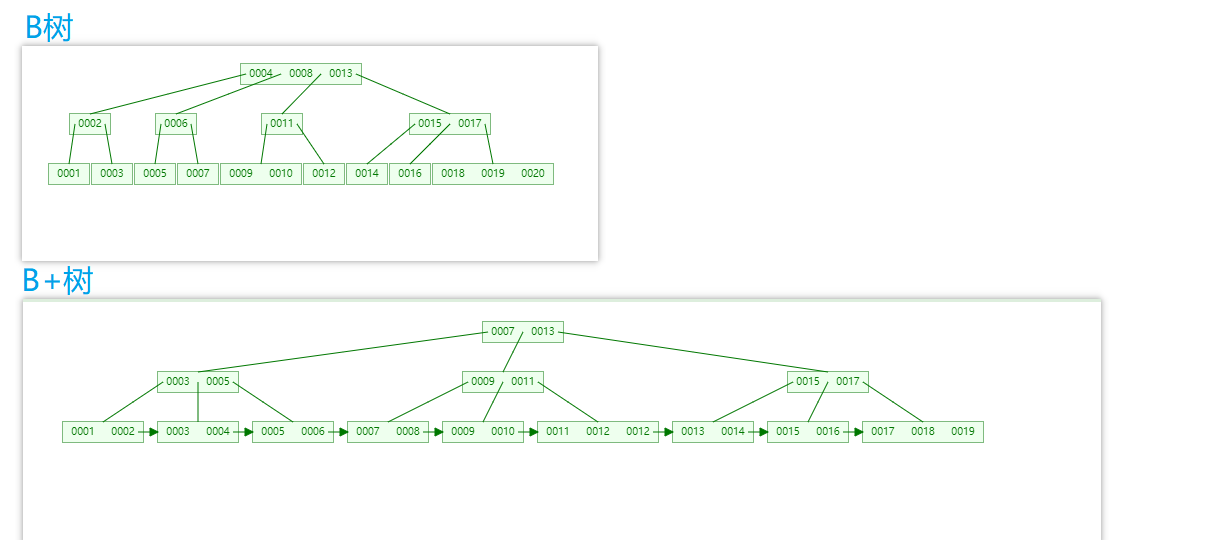
B+树在B树上面的优化
IO效率更高(B树每个节点都会保留数据区,而B+树则不会,假设我们查询一条数据要遍历三层,那么显然B+树查询中IO消耗更小)
范围查找效率更高(如图,B+树已经形成了一个天然链表形式,只需要根据最结尾的链式结构查找)

基于索引的数据扫描效率更高。
索引类型的分类
索引类型可分为两类:
- 主键索引
- 辅佐索引(二级索引)
- 唯一性索引
- 复合索引
- 普通索引
- 覆盖索引
主键索引相对来说性能是最好的,但是对于SQL优化,其实大多时候我们都在辅佐索引上面做一些改进和补充。
B+树在储存引擎层面落地
我们创建两个表分别为test_innodb(采用InnoDB作为储存引擎)test_myisam(采用MyISAM作为储存引擎)下图是两张表磁盘落地的相关文件,这两个储存引擎在B+树磁盘落地式截然不同的。

B+树在MyISAM落地
- *.frm文件是表格骨架文件比如这个表中的id字段name字段是什么类型的存储在这里
- *.MYD(D=data)则储存数据
- *.MYI (I=index)则储存索引

比如现在执行如下sql语句 ,那么在MyISAM中他就是先在test_myisam.MYI中查找到103然后拿到0x194281这个地址然后再去test_myisam.MYD中找到这个数据返回。
SELECT id,name from test_myisam where id =103

如果test_myisam表中,id为主键索引,name也是一个索引,那么在test_myisam.MYI中则会有两个平级的B+树,这也导致MyISAM引擎中主键索引和二级索引是没有主次之分的,是平级关系。因为这种机制在MyISAM引擎中,有可能使用多个索引,在InnoDB中则不会出现这种情况。
B+树在InnoDB落地


InnoDB不像MyISAM来独立一个MYD 文件来存储数据,它的数据直接存储在叶子结点关键字对应的数据区在这保存这一个id列所有行的详细记录。
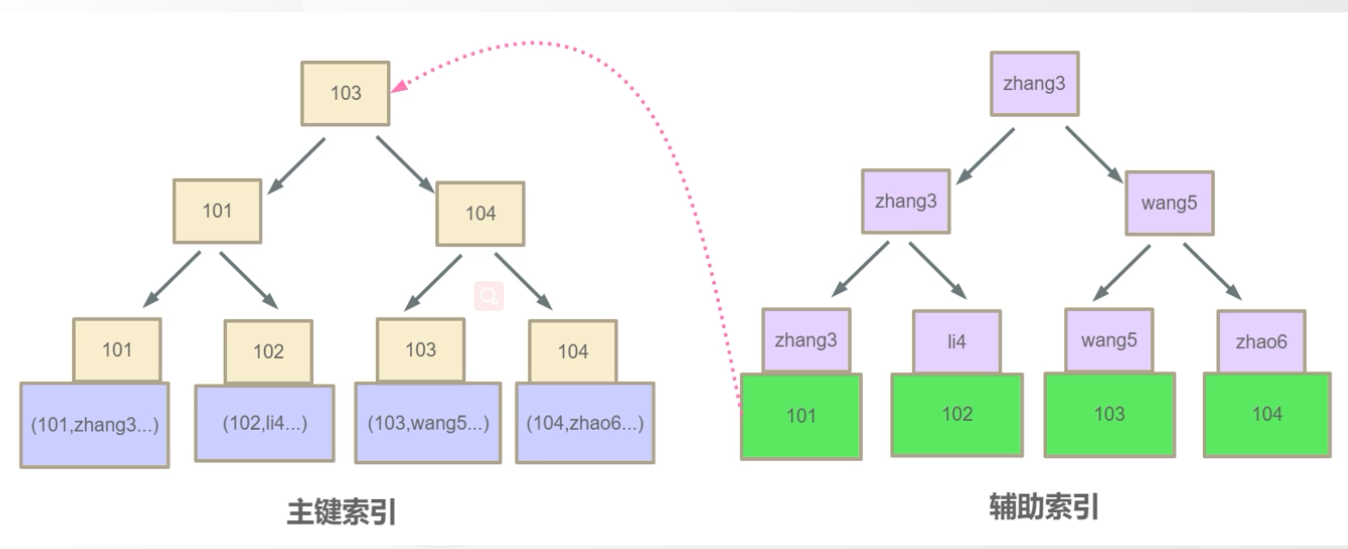
InnoDB 主键索引和辅助索引关系
我们现在执行如下SQL语句,他会先去找辅助索引,然后找到辅助索引下101的主键,再去回表(二次扫描)根据主键索引查询103这条数据将其返回。
SELECT id,name from test_myisam where name ='zhangsan'
这里就有一个问题了,为什么不像MyISAM在辅助索引下直接记录磁盘地址,而是要多此一举再去回表扫描主键索引,这个问题在下面相关面试题中回答,记一下这个问题是这里来的。
相关面试题
为什么MySQL选择B+树作为索引结构
这个就不说了,上文应该讲清楚了。
B+树在MyISAM和InnoDB落地区别。
这个可以总结一下,MyISAM落地数据储存会有三个类型文件 ,.frm文件是表骨架文件,.MYD(D=data)则储存数据 ,.MYI (I=index)则储存索引,MyISAM引擎中主键索引和二级索引平级关系,在MyISAM引擎中,有可能使用多个索引,InnoDB则相反,主键索引和二级索有严格的主次之分在InnoDB一条语句只能用一个索引要么不用。
如何判断一条sql语句是否使用了索引。
可以通过执行计划来判断 可以在sql语句前explain/ desc
set global optimizer_trace='enabled=on' 打开执行计划开关他将会把每一条查询sql执行计划记录在information_schema 库中OPTIMIZER_TRACE表中
为什么主键索引最好选择自增列?
自增列,数据插入时整个索引树是只有右边在增加的,相对来说索引树的变动更小。
为什么经常变动的列不建议使用索引?
和上一个问题原因一样,当一个索引经常发生变化,那么就意味这,这个缩印树也要经常发生变化。4
为什么说重复度高的列,不建议建立索引?
这个原因是因为离散性,比如说,一张一百万数据的表,其中一个字段代表性别,0代表男1代表女,把这字段加了索引,那么在索引树上,将会有大量的重复数据。而我们常见的索引建立一般都是驱动型的。其目的是,尽可能的删减数据的查询范围,这个显然是不匹配的。
什么是联合索引
联合索引是一个包含了多个功效的索引,他只是一个索引而不是多个,
其次,单列索引是一种特殊的联合索引
联合索引的创立要遵循最左前置原则(最常用列>离散度>占用空间小)
什么是覆盖索引
通过索引项信息可直接返回所需要查询的索引列,该索引被称之为覆盖索引,说白了就是不需要做回表操作,可以从二级索引中直接取到所需数据。
什么是ICP机制
索引下推,简单点来说就是,在sql执行过程中,面对where多条件过滤时,通过一个索引,完成数据搜索和过滤条件其,特点能减少io操作。
在InnoDB表中不可能没有主键对还是不对原因是什么?
- 首先这句话是对的,但是情况有三种:
- 就是在你手动显式指定这一个字段为主键时候,会以这一个字段为聚集索引。
- 在没有显式指定主键时候有两种情况:
- 他会寻找第一个UK(unique key)作为主键索引组织索引编排。
- 如果既没有指定主键也没有UK的情况下,此时会以rowId(在InnoDB表中每一个记录都会有一个隐藏(6byte)的rowId)为聚集索引。
- 首先这句话是对的,但是情况有三种:
什么是回表操作
在InnoDB 中基于辅助索引查询的内容,从辅助索引中无法直接获取,需要基于主键索引的二次扫描的操作叫做回表操作。
为什么在InnoDB 中辅助索引叶子结点数据区记录的是主键索引的值而不是像MyISAM中去记录磁盘地址。
- 这个原因其实很简单,因为主键索引的数据结构是会经常发生变化的,如果在辅助索引数据区记录磁盘地址,那么假设我们有10个辅助索引,当我们主键索引结构发生变化后,还要一个个去通知辅助索引,且主键索引结构是经常发生变化的,增删都有可能影响他的数据结构。
版权归属: 泪梦红尘
本文链接: https://www.bss2.com/archives/mysql-opt-index
- 这个原因其实很简单,因为主键索引的数据结构是会经常发生变化的,如果在辅助索引数据区记录磁盘地址,那么假设我们有10个辅助索引,当我们主键索引结构发生变化后,还要一个个去通知辅助索引,且主键索引结构是经常发生变化的,增删都有可能影响他的数据结构。
MySQL优化之索引解析的更多相关文章
- mysql 优化之索引的使用
mysql 优化之索引的使用 1:MySQL 索引简介: MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度. 打个比方,如果合理的设计且使用索引的MySQL ...
- mysql优化之索引篇
对mysql优化是一个综合性的技术,主要包括 a: 表的设计合理化(符合3NF) b: 添加适当索引(index) [四种: 普通索引.主键索引.唯一索引unique.全文索引] c: 分表技术(水平 ...
- mysql优化之索引优化
Posted by Money Talks on 2012/02/23 | 第一篇 序章第二篇 连接优化第三篇 索引优化第四篇 查询优化第五篇 到实战中去 索引优化 索引优化涉及到几个方面,包括了索引 ...
- Mysql优化之索引和字段
Mysql优化是一个老生常谈的问题, 优化的方向也优化很多:从架构层;从设计层;从存储层;从SQL语句层; 今天讲解一下从索引和字段: 字段优化: ① 尽量使用TINYINT.SMALLINT.ME ...
- 第九课——MySQL优化之索引和执行计划
一.创建索引需要关注什么? 1.关注基数列唯一键的数量: 比如性别,该列只有男女之分,所以性别列基数是2: 2.关注选择性列唯一键与行数的比值,这个比值范围在0~1之前,值越小越好: 其实,选择性列唯 ...
- mysql优化之索引建立的规则
索引经常使用的数据结构为B+树.结构例如以下 如上图,是一颗b+树,关于b+树的定义能够參见B+树,这里仅仅说一些重点.浅蓝色的块我们称之为一个磁盘块,能够看到每一个磁盘块包括几个数据项(深蓝色所看到 ...
- MySQL优化四 索引优化
索引为什么能提高数据访问性能? 很多人只知道索引能够提高数据库的性能,但并不是特别了解其原理,其实我们可以用一个生活中的示例来理解. 我们让一位不太懂计算机的朋友去图书馆确认一本叫做<MySQL ...
- Mysql优化之索引
前言 这几天抽了个时间将<高性能Mysql>看了一下忽觉索引非常之重要,习之然后总结巩固知识.本文索引使用的是InnoDB存储引擎.因为本文并不是说用索引的好处,所以并不会书写QPS之类的 ...
- 【Mysql优化】索引优化策略
1:索引类型 1.1 B-tree索引 注: 名叫btree索引,大的方面看,都用的平衡树,但具体的实现上, 各引擎稍有不同, 比如,严格的说,NDB引擎,使用的是T-tree Myisam,in ...
随机推荐
- IDEA导入maven项目时,报各种包找不到--com.sunyard.encrypt.function
IDEA错误归类 问题描述1 IDEA启动项目时,报maven引入的包找不到 暂时解决办法 问题描述2 IDEA启动项目时,报普通项目引入的包找不到 解决办法 总结: 问题1和问题2的解决办法明显冲突 ...
- Spring @Cacheable 缓存不生效的问题
最近在项目中使用了Ehcache缓存,使用方式是用Spring提供的 @Cacheable 注解的方式,这种方式简单.快速.方便,推荐使用. 在使用的过程中,遇到了缓存不生效的情况,经过分析处理,总结 ...
- 基于redis实现tomcat的session会话保持 (转)
出处:https://cloud.tencent.com/developer/article/1402997 基于redis实现tomcat的session会话保持 在实际生产中,我们经常部署应用服务 ...
- urlencode编码与urldecode解码
转载请注明来源:https://www.cnblogs.com/hookjc/ <script type="text/javascript"><!--functi ...
- Emoji与unicode特殊字符的处理
遇到了一个很让人纠结的问题:emoji表情在使用的过程中,会莫名其妙的消失,或者变成乱码,同时数据库用utf8mb4来存储,但是也出现了问题,冷备过后,导入进库的时候,变成了不可见字符,神奇的消失了! ...
- 类扩展(Class Extension)
类扩展(Class Extension) 也有人称为匿名分类 - 作用 - 能为某个类增加额外的属性.成员变量.方法声明 - 一般将类扩展写到.m文件中 - 一般将一些私有的属 ...
- bash_profile和bashsrc的区别
感谢大佬:http://unclealan.cn/index.php/system/128.html 描述 在类Linux或者MACOS系统中,家目录(用户目录)中我们会看到,.bash_profil ...
- 关于 BSGS 以及 ExBSGS 算法的理解
BSGS 引入 求解关于\(X\)的方程, \[A^X\equiv B \pmod P \] 其中\(Gcd(A,P)=1\) 求解 我们令\(X=i*\sqrt{P}-j\),其中\(0<=i ...
- 浅谈Java之反射
反射 四种获取Class实例的方法 定义测试结构 获取属性结构 获取方法结构 获取构造器结构(包括父类泛型) 获取实现的接口 获取所在包 获取注解 获取并创建指定构造器 获取指定属性 获取并运行指定方 ...
- suging闲谈-netty 的异步非阻塞IO线程与业务线程分离
前言 surging 对外沉寂了一段时间了,但是作者并没有闲着,而是针对于客户的需要添加了不少功能,也给我带来了不少外快收益, 就比如协议转化,consul 的watcher 机制,JAVA版本,sk ...