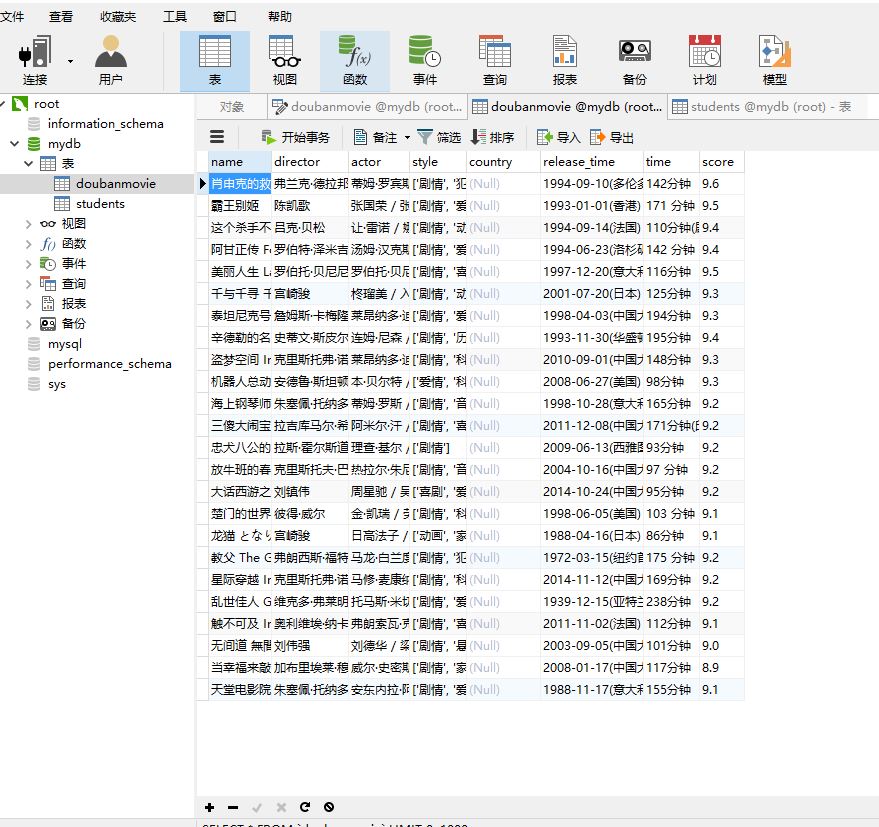
爬取豆瓣电影top250并存储到mysql数据库
import requests
from lxml import etree
import re
import pymysql
import time conn= pymysql.connect(host='localhost',user='root',passwd='root',db='mydb',port=3306,charset='utf8')
cursor=conn.cursor() headers={
#'User-Agent':'Nokia6600/1.0 (3.42.1) SymbianOS/7.0s Series60/2.0 Profile/MIDP-2.0 Configuration/CLDC-1.0'
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
} def get_movie_url(url):
html=requests.get(url,headers=headers)
selector=etree.HTML(html.text)
movie_hrefs=selector.xpath('//div[@class="hd"]/a/@href')
for movie_href in movie_hrefs:
get_movie_info(movie_href)
time.sleep(2) def get_movie_info(url):
html=requests.get(url,headers=headers)
print("开始")
selector=etree.HTML(html.text)
try:
name=selector.xpath('//*[@id="content"]/h1/span[1]/text()')[0]
director=selector.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')[0]
actors=selector.xpath('//*[@id="info"]/span[3]/span[2]')[0]
actor=actors.xpath('string(.)')
#style=selector.xpath('//*[@id="info"]/span[5]/text()')[0]
style=re.findall('<span property="v:genre">(.*?)</span>',html.text,re.S) #爬取制片国家不成功
#country=re.findall('<span class="pl">制片国家/地区:</span>(.*?)<b',selector.text,re.S)[0]
#country=re.findall('<span property="v:genre">.*?地区:</span>(.*?)<b',selector.text,re.S)[0]
#countrys=selector.xpath('//*[@id="info"]/br[4]')[0]
#country=selector.xpath('//*[@id="info"]/text()[2]')[0] release_time=re.findall('上映日期:</span>.*?>(.*?)</span>',html.text,re.S)[0]
time=re.findall('片长:</span>.*?>(.*?)</span>',html.text,re.S)[0]
score=selector.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/strong/text()')[0]
cursor.execute("insert into doubanmovie (name,director,actor,style,release_time,time,score)values(%s,%s,%s,%s,%s,%s,%s)",(str(name),str(director),str(actor),str(style),str(release_time),str(time),str(score))) except IndexError:
pass if __name__=='__main__':
urls=['https://movie.douban.com/top250?start={}'.format(str(i)) for i in range(0,25,25)]
for url in urls:
get_movie_url(url)
time.sleep(2)
conn.commit()
print("结束")
爬取豆瓣电影top250并存储到mysql数据库的更多相关文章
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- urllib+BeautifulSoup无登录模式爬取豆瓣电影Top250
对于简单的爬虫任务,尤其对于初学者,urllib+BeautifulSoup足以满足大部分的任务. 1.urllib是Python3自带的库,不需要安装,但是BeautifulSoup却是需要安装的. ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
随机推荐
- ubuntu12.04+virtualbox+winxp的关于摄像头无法使用,声音出不来的问题
前天在ubuntu上安装了个virtualbox的虚拟机.以前在windows下面是用的vmware.结果到了ubuntu下面折腾半天用不了,于是就装了个virtualbox,在virtualbox里 ...
- POJ - 2031 Building a Space Station 三维球点生成树Kruskal
Building a Space Station You are a member of the space station engineering team, and are assigned a ...
- Spring Data JPA stackoverflow
1.禁止使用lombok 的@Data 注释 使用@Data注释后,默认会重写父类的toString()方法,hashcode()等方法,在往map里存的时候,会根据equals和hashcode方法 ...
- TCP/IP之大明邮差
大明王朝天启四年, 清晨. 天色刚蒙蒙亮,我就赶着装满货物的马车来到了南城门, 这里是集中处理货物的地方 , 一队一队的马车都来到这里, 城头的士兵带着头盔,身披盔甲, 手持长枪, 虎视眈眈的注视这下 ...
- [UE4]Montage动画设置Slot
最后一张图看下,配合官网motage教程,容易理解push anim具体用法 http://aigo.iteye.com/blog/2277545 如何新建一个Montage的步骤这里省略了,网上很多 ...
- 字符环(openjudge 2755)
字符环 总时间限制: 1000ms 内存限制: 65536kB 描述 有两个由字符构成的环.请写一个程序,计算这两个字符环上最长连续公共字符串的长度.例如,字符串“ABCEFAGADEGKABUV ...
- 【并发编程】一文带你读懂深入理解Java内存模型(面试必备)
并发编程这一块内容,是高级资深工程师必备知识点,25K起如果不懂并发编程,那基本到顶.但是并发编程内容庞杂,如何系统学习?本专题将会系统讲解并发编程的所有知识点,包括但不限于: 线程通信机制,深入JM ...
- HTML+CSS注意点
1. 对于中文网页,需要在header中使用<meta charset="utf-8">声明编码,否则会出现乱码. 2. 属性 属性 描述 class 为html元素定 ...
- 去除vue路由跳转地址栏后的哈希值#
去除vue路由跳转地址栏后的哈希值#,我们只需要在路由跳转的管理文件router目录下的index.js中加上一句代码即可去掉哈希值# mode:"history" import ...
- [软件工程基础]Alpha 阶段事后分析
设想和目标 1. 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述? 帮助选修物理实验的学生撰写实验报告,计算实验数据,验证计算结果,并提供一个讨论的平台. 全体成员认 ...