Elasticsearch检索分类详解
前言
Elasticsearch中当我们设置Mapping(分词器、字段类型)完毕后,就可以按照设定的方式导入数据。
有了数据后,我们就需要对数据进行检索操作。根据实际开发需要,往往我们需要支持包含但不限于以下类型的检索:
1)精确匹配,类似mysql中的 “=”操作;
2)模糊匹配,类似mysql中的”like %关键词% “查询操作;
3)前缀匹配;
4)通配符匹配;
5)正则表达式匹配;
6)跨索引匹配;
7)提升精读匹配。
细数一下,我们的痛点在于:
1)ES究竟支持哪些检索操作?
2)如何实现ES精确值检索、指定索引检索、全文检索?
这些就是本文着重参考ES最新官方文档,针对ES5.X版本探讨的内容。
0、检索概览
检索子句的行为取决于查询应用于过滤(filter)上下文还是查询/分析(query)上下文。
过滤上下文——对应于结构化检索
)核心回答的问题是:“这个文档是否符合这个查询条款?” )答案是简单的是或否,不计算分数。 )过滤器上下文主要用于过滤结构化数据。类似于Mysql中判定某个字段是否存在:
例如:
a. 时间戳字段:是否属于2015年或2016年?
b. 状态字段:是否设置为“已发布”?
经常使用的过滤器将被Elasticsearch**自动缓存,以加快性能**。
分析上下文——对应于全文检索
1)核心回答了“本文档与此查询子句是否匹配?”的问题。
2)除了决定文档是否匹配之外,查询子句还会计算一个_score,表示文档与其他文档的匹配程度。
综合应用场景如下:
GET /_search
{ "query": { "bool": { "must": [
{ "match": { "title": "Search" }},
{ "match": { "content": "Elasticsearch" }}
], "filter": [
{ "term": { "status": "published" }},
{ "range": { "publish_date": { "gte": "2015-01-01" }}}
]
}
}
}
以上检索,title中包含”Search”并且content中包含 “Elasticsearch”,status中精确匹配”published”,并且publish_date 大于“2015-01-01”的全部信息。以下,以“脑图”的形式直观展示检索分类:
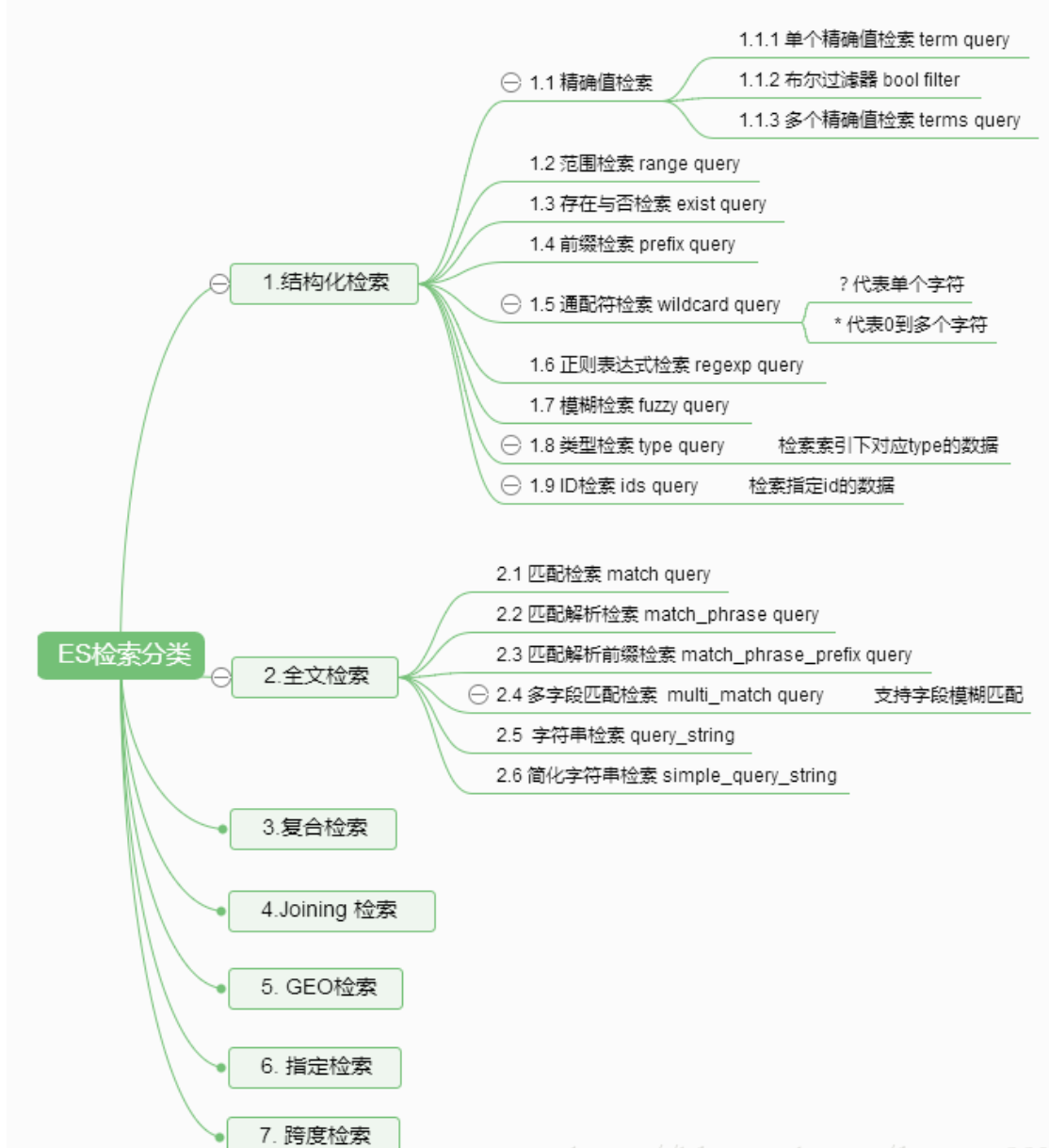
以下内容的原文需要参考ES官方文档(随着版本变化,后续会有更新)
1、结构化检索
针对字段类型: 日期、时间、数字类型,以及精确的文本匹配。
结构化检索特点:
* 1)结构化查询,我们得到的结果 总是 非是即否,要么存于集合之中,要么存在集合之外。
* 2)结构化查询不关心文件的相关度或评分;它简单的对文档包括或排除处理。
1.1 精确值查找
1.1.1 单个精确值查找(term query)
term 查询会查找我们指定的精确值。term 查询是简单的,它接受一个字段名以及我们希望查找的数值。
想要类似mysql中如下sql语句的查询操作:
SELECT document FROM products WHERE price = 20;
DSL写法:
GET /my_store/products/_search
{
"query" : {
"term" : {
"price" :
}
}
}
当进行精确值查找时, 我们会使用过滤器(filters)。过滤器很重要,因为它们执行速度非常快,不会计算相关度(直接跳过了整个评分阶段)而且很容易被缓存。如下: 使用 constant_score 查询以非评分模式来执行 term 查询并以一作为统一评分。
GET /my_store/products/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"price" :
}
}
}
}
}
注意:5.xES中,对于字符串类型,要进行精确值匹配。需要讲类型设置为text和keyword两种类型。mapping设置如下:
POST testindex/testtype/_mapping
{
"testtype ":{
"properties":{
"title":{
"type":"text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_max_word",
"fields":{
"keyword":{
"type":"keyword"
}
}
}
}
}
1.1.2 布尔过滤器
一个 bool 过滤器由三部分组成:
{
"bool" : {
"must" : [],
"should" : [],
"must_not" : [],
"filter": []
}
}
must ——所有的语句都 必须(must) 匹配,与 AND 等价。
must_not ——所有的语句都 不能(must not) 匹配,与 NOT 等价。
should ——至少有一个语句要匹配,与 OR 等价。
filter——必须匹配,运行在非评分&过滤模式。
就这么简单! 当我们需要多个过滤器时,只须将它们置入 bool 过滤器的不同部分即可。
举例:
GET /my_store/products/_search
{
"query" : {
"filtered" : {
"filter" : {
"bool" : {
"should" : [
{ "term" : {"price" : }},
{ "term" : {"productID" : "XHDK-A-1293-#fJ3"}}
],
"must_not" : {
"term" : {"price" : }
}
}
}
}
}
}
1.1.3 多个值精确查找(terms query)
{
"terms" : {
"price" : [, ]
}
}
如上,terms是包含的意思,包含20或者包含30。
如下实现严格意义的精确值检索, tag_count代表必须匹配的次数为1。
GET /my_index/my_type/_search
{
"query": {
"constant_score" : {
"filter" : {
"bool" : {
"must" : [
{ "term" : { "tags" : "search" } },
{ "term" : { "tag_count" : } }
]
}
}
}
}
}
1.2 范围检索(range query)
range 查询可同时提供包含(inclusive)和不包含(exclusive)这两种范围表达式,可供组合的选项如下:
gt: > 大于(greater than)
lt: < 小于(less than)
gte: >= 大于或等于(greater than or equal to)
lte: <= 小于或等于(less than or equal to)
类似Mysql中的范围查询:
SELECT document
FROM products
WHERE price BETWEEN AND
ES中对应的DSL如下:
GET /my_store/products/_search
{
"query" : {
"constant_score" : {
"filter" : {
"range" : {
"price" : {
"gte" : ,
"lt" :
}
}
}
}
}
}
1.3 存在与否检索(exist query)
mysql中,有如下sql:
SELECT tags FROM posts WHERE tags IS NOT NULL;
ES中,exist查询某个字段是否存在:
GET /my_index/posts/_search
{
"query" : {
"constant_score" : {
"filter" : {
"exists" : { "field" : "tags" }
}
}
}
}
https://blog.csdn.net/laoyang360/article/details/77623013 1.3接着往下面开始
Elasticsearch检索分类详解的更多相关文章
- (转)dp动态规划分类详解
dp动态规划分类详解 转自:http://blog.csdn.NET/cc_again/article/details/25866971 动态规划一直是ACM竞赛中的重点,同时又是难点,因为该算法时间 ...
- Elasticsearch SQL用法详解
Elasticsearch SQL用法详解 mp.weixin.qq.com 本文详细介绍了不同版本中Elasticsearch SQL的使用方法,总结了实际中常用的方法和操作,并给出了几个具体例子 ...
- 【Java】Lucene检索引擎详解
基于Java的全文索引/检索引擎——Lucene Lucene不是一个完整的全文索引应用,而是是一个用Java写的全文索引引擎工具包,它可以方便的嵌入到各种应用中实现针对应用的全文索引/检索功能. L ...
- elasticsearch 安装配置详解
一.安装 简单的安装与启动于前文ElasticSearch初探(一)已有讲述,这里不再重复说明. 二.启动 1.自带脚本启动 1)bin/elasticsearch,不太任何参数,默认在前端启动 2) ...
- ELK学习笔记之ElasticSearch的索引详解
0x00 ElasticSearch的索引和MySQL的索引方式对比 Elasticsearch是通过Lucene的倒排索引技术实现比关系型数据库更快的过滤.特别是它对多条件的过滤支持非常好,比如年龄 ...
- 【打分策略】Elasticsearch打分策略详解与explain手把手计算
一.目的 一个搜索引擎使用的时候必定需要排序这个模块,一般情况下在不选择按照某一字段排序的情况下,都是按照打分的高低进行一个默认排序的,所以如果正式使用的话,必须对默认排序的打分策略有一个详细的了解才 ...
- 【elasticsearceh】elasticsearch.yml配置文件详解
主要内容如下: cluster.name: elasticsearch 配置es的集群名称,默认是elasticsearch,es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个 ...
- Elasticsearch的Search详解
介绍 ES不是新技术,是将全文检索和数据分析.分布式整合到一起. 基于lucene开发,提供简单的restful api接口.java api接口.其他语言开发接口等. 实现了分布式的搜索引擎和分析引 ...
- Elasticsearch删除操作详解
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484022&idx=1&sn=7a4de21 ...
随机推荐
- 性能测试--测试流程、APDEX、linux性能知识
测试流程.APDEX.linux性能知识 一.性能测试流程: 整体流程:收集需求-->搭建测试环境-->设计性能测试场景-->开发测试脚本-->执行测试-->收集数据-- ...
- 【题解】Fence(单调队列)
[题解]Fence(单调队列) POJ - 1821 题目大意 有\(k\)个粉刷匠,每个粉刷匠一定要粉刷某个位置\(S_i\),一个粉刷匠可以粉刷至多\(l_i\)个位置(必须连续\(l_i\)互不 ...
- JSP中的内容布局
参考 :https://stackoverflow.com/questions/10529963/what-is-the-best-way-to-create-jsp-layout-template ...
- CUDA: 共享内存与同步
CUDA C支持共享内存, 将CUDA C关键字__shared__添加到变量声明中,将使这个变量驻留在共享内存中.对在GPU上启动的每个线程块,CUDA C编译器都将创建该变量的一个副本.线程块中的 ...
- Java for LeetCode 117 Populating Next Right Pointers in Each Node II
Follow up for problem "Populating Next Right Pointers in Each Node". What if the given tre ...
- [2018-08-25]模板引擎Razor Engine 用法示例
好久没写博客了,回宁波后最近几个月一直忙些线下的事情. 敲代码方面脱产有阵子了,生疏了,回头一看,这行业果然更新飞快. 最近线下的事情基本忙完,准备开始干回老本行,最重要的一件事就是升级abplus库 ...
- 【转】数据存储——APP 缓存数据线程安全问题探讨
http://blog.cnbang.net/tech/3262/ 问题 一般一个 iOS APP 做的事就是:请求数据->保存数据->展示数据,一般用 Sqlite 作为持久存储层,保存 ...
- 3D立方体旋转动画
在线演示 本地下载
- linux中fflush函数和printf函数 【转】
本文转载自:http://blog.chinaunix.net/uid-30058258-id-5029847.html printf是一个行缓冲函数printf函数是标准函数,最终会调用到系统调用函 ...
- SqlServer 按逗号分隔
SELECT ORDER_ID,LTRIM(MAX(SYS_CONNECT_BY_PATH(GOODS_NAME, ',')), ',') GOODS_NAME FROM (SELECT GOODS_ ...