创建自定义 Estimator
ref
本文档介绍了自定义 Estimator。具体而言,本文档介绍了如何创建自定义 Estimator 来模拟预创建的 Estimator DNNClassifier 在解决鸢尾花问题时的行为。要详细了解鸢尾花问题,请参阅预创建的 Estimator 这一章。
要下载和访问示例代码,请执行以下两个命令:
git clone https://github.com/tensorflow/models/
cd models/samples/core/get_started
在本文档中,我们将介绍 custom_estimator.py。您可以使用以下命令运行它:
python custom_estimator.py
如果您时间并不充足,欢迎对比 custom_estimator.py 与 premade_estimator.py(位于同一个目录中)。
预创建的 Estimator 与自定义 Estimator
如下图所示,预创建的 Estimator 是 tf.estimator.Estimator 基类的子类,而自定义 Estimator 是 tf.estimator.Estimator 的实例:
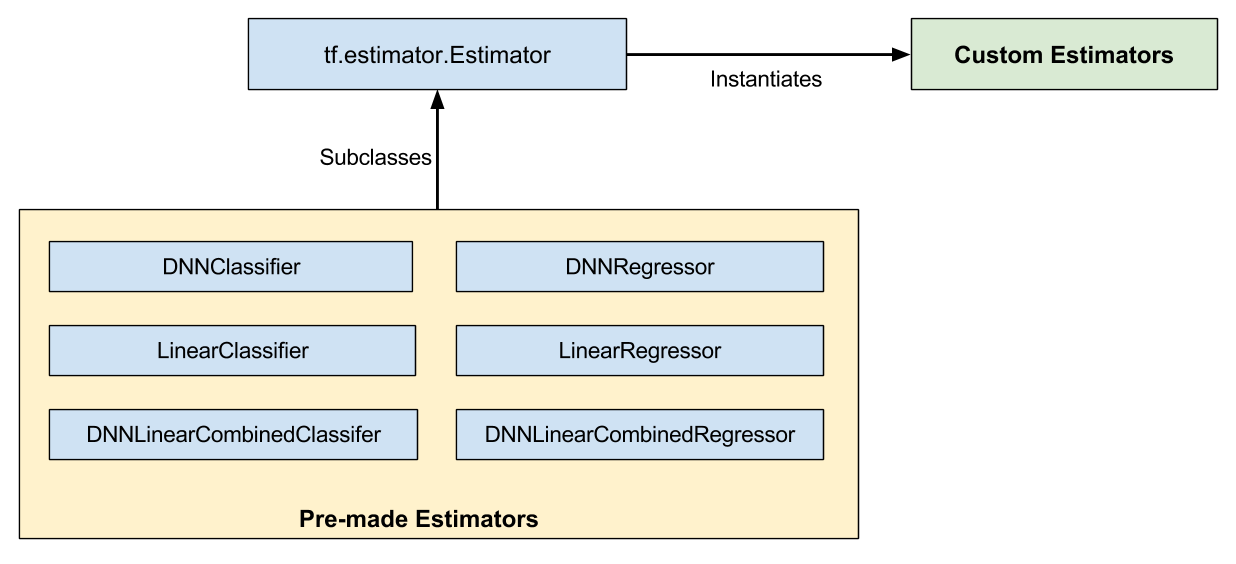
预创建的 Estimator 和自定义 Estimator 都是 Estimator。
预创建的 Estimator 已完全成形。不过有时,您需要更好地控制 Estimator 的行为。这时,自定义 Estimator 就派上用场了。您可以创建自定义 Estimator 来完成几乎任何操作。如果您需要以某种不寻常的方式连接隐藏层,则可以编写自定义 Estimator。如果您需要为模型计算独特的指标,也可以编写自定义 Estimator。基本而言,如果您需要一个针对具体问题进行了优化的 Estimator,就可以编写自定义 Estimator。
模型函数(即 model_fn)会实现机器学习算法。采用预创建的 Estimator 和自定义 Estimator 的唯一区别是:
- 如果采用预创建的 Estimator,则有人已为您编写了模型函数。
- 如果采用自定义 Estimator,则您必须自行编写模型函数。
您的模型函数可以实现各种算法,定义各种各样的隐藏层和指标。与输入函数一样,所有模型函数都必须接受一组标准输入参数并返回一组标准输出值。正如输入函数可以利用 Dataset API 一样,模型函数可以利用 Layers API 和 Metrics API。
我们来看看如何使用自定义 Estimator 解决鸢尾花问题。快速提醒:以下是我们尝试模拟的鸢尾花模型的结构:
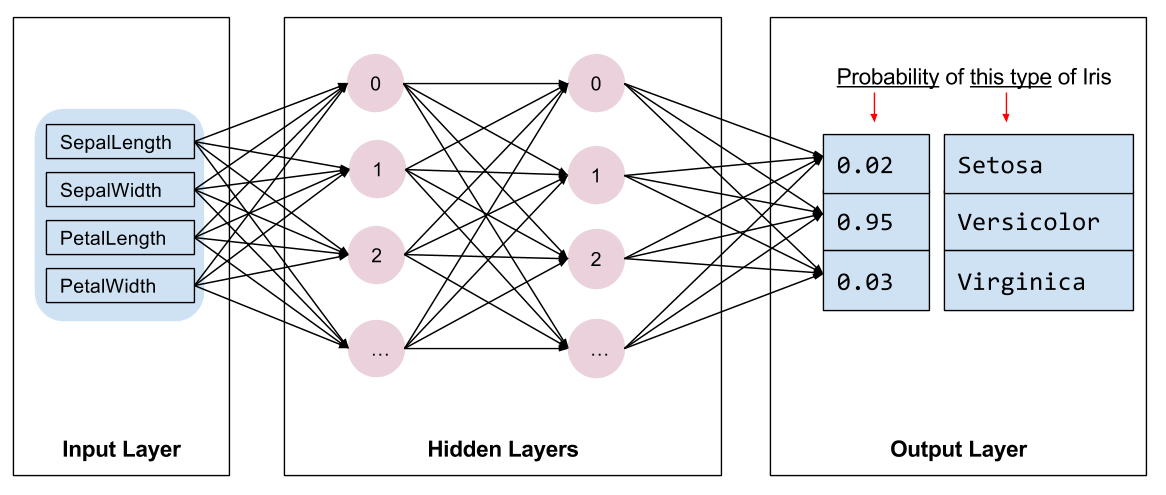
我们的鸢尾花实现包含四个特征、两个隐藏层和一个对数输出层。
编写输入函数
我们的自定义 Estimator 实现与我们的预创建的 Estimator 实现使用的是同一输入函数(来自 iris_data.py)。即:
def train_input_fn(features, labels, batch_size):
"""An input function for training"""
# Convert the inputs to a Dataset.
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))
# Shuffle, repeat, and batch the examples.
dataset = dataset.shuffle(1000).repeat().batch(batch_size)
# Return the read end of the pipeline.
return dataset.make_one_shot_iterator().get_next()
此输入函数会构建可以生成批次 (features, labels) 对的输入管道,其中 features 是字典特征。
创建特征列
按照预创建的 Estimator 和特征列章节中详细介绍的内容,您必须定义模型的特征列来指定模型应该如何使用每个特征。无论是使用预创建的 Estimator 还是自定义 Estimator,您都要使用相同的方式定义特征列。
以下代码为每个输入特征创建一个简单的 numeric_column,表示应该将输入特征的值直接用作模型的输入:
# Feature columns describe how to use the input.
my_feature_columns = []
for key in train_x.keys():
my_feature_columns.append(tf.feature_column.numeric_column(key=key))
编写模型函数
我们要使用的模型函数具有以下调用签名:
def my_model_fn(
features, # This is batch_features from input_fn
labels, # This is batch_labels from input_fn
mode, # An instance of tf.estimator.ModeKeys
params): # Additional configuration
前两个参数是从输入函数中返回的特征和标签批次;也就是说,features 和 labels 是模型将使用的数据的句柄。mode 参数表示调用程序是请求训练、预测还是评估。
调用程序可以将 params 传递给 Estimator 的构造函数。传递给构造函数的所有 params 转而又传递给 model_fn。在 custom_estimator.py 中,以下行将创建 Estimator 并设置参数来配置模型。此配置步骤与我们配置 tf.estimator.DNNClassifier(在预创建的 Estimator 中)的方式相似。
classifier = tf.estimator.Estimator(
model_fn=my_model,
params={
'feature_columns': my_feature_columns,
# Two hidden layers of 10 nodes each.
'hidden_units': [10, 10],
# The model must choose between 3 classes.
'n_classes': 3,
})
要实现一般的模型函数,您必须执行下列操作:
定义模型
基本的深度神经网络模型必须定义下列三个部分:
定义输入层
在 model_fn 的第一行调用 tf.feature_column.input_layer,以将特征字典和 feature_columns 转换为模型的输入,如下所示:
# Use `input_layer` to apply the feature columns.
net = tf.feature_column.input_layer(features, params['feature_columns'])
上面的行会应用特征列定义的转换,从而创建模型的输入层。
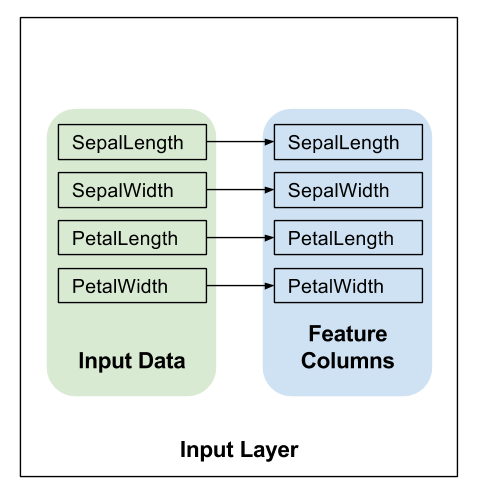
隐藏层
如果您要创建深度神经网络,则必须定义一个或多个隐藏层。Layers API 提供一组丰富的函数来定义所有类型的隐藏层,包括卷积层、池化层和丢弃层。对于鸢尾花,我们只需调用 tf.layers.dense 来创建隐藏层,并使用 params['hidden_layers'] 定义的维度。在 dense 层中,每个节点都连接到前一层中的各个节点。下面是相关代码:
# Build the hidden layers, sized according to the 'hidden_units' param.
for units in params['hidden_units']:
net = tf.layers.dense(net, units=units, activation=tf.nn.relu)
这里的变量 net 表示网络的当前顶层。在第一次迭代中,net 表示输入层。在每次循环迭代时,tf.layers.dense 都使用变量 net 创建一个新层,该层将前一层的输出作为其输入。
创建两个隐藏层后,我们的网络如下所示。为了简单起见,下图并未显示各个层中的所有单元。
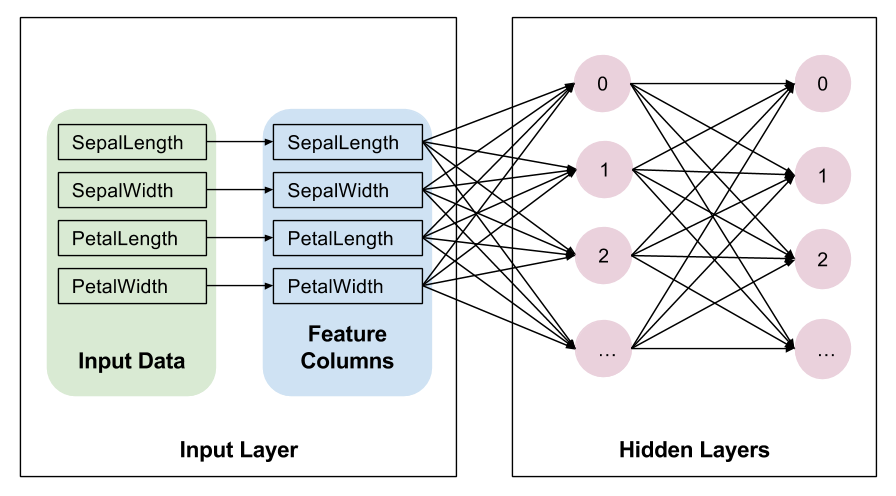
请注意,tf.layers.dense 提供很多其他功能,包括设置多种正则化参数的功能。不过,为了简单起见,我们只接受其他参数的默认值。
输出层
我们再次调用 tf.layers.dense 来定义输出层,这次不使用激活函数:
# Compute logits (1 per class).
logits = tf.layers.dense(net, params['n_classes'], activation=None)
在这里,net 表示最后的隐藏层。因此,所有的层如下所示连接在一起:
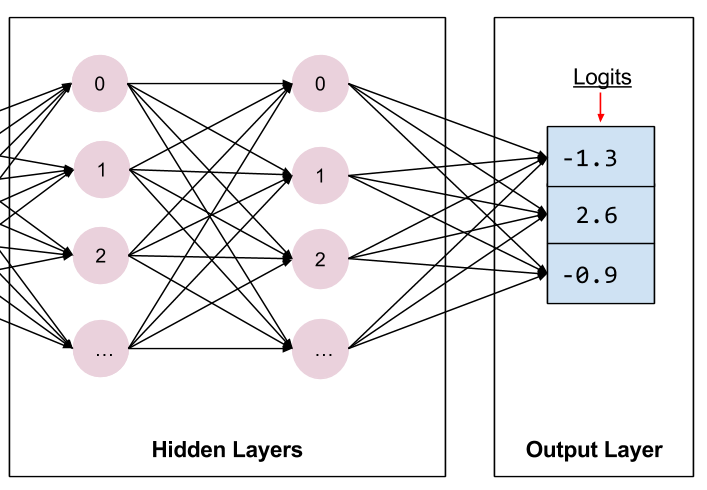
最后的隐藏层馈送到输出层。
定义输出层时,units 参数会指定输出的数量。因此,通过将 units 设置为 params['n_classes'],模型会为每个类别生成一个输出值。输出向量的每个元素都将包含针对相关鸢尾花类别(山鸢尾、变色鸢尾或维吉尼亚鸢尾)分别计算的分数或“对数”。
之后,tf.nn.softmax 函数会将这些对数转换为概率。
实现训练、评估和预测
创建模型函数的最后一步是编写实现预测、评估和训练的分支代码。
每当有人调用 Estimator 的 train、evaluate 或 predict 方法时,就会调用模型函数。您应该记得,模型函数的签名如下所示:
def my_model_fn(
features, # This is batch_features from input_fn
labels, # This is batch_labels from input_fn
mode, # An instance of tf.estimator.ModeKeys, see below
params): # Additional configuration
重点关注第三个参数 mode。如下表所示,当有人调用 train、evaluate 或 predict 时,Estimator 框架会调用模型函数并将 mode 参数设置为如下所示的值:
| Estimator 方法 | Estimator 模式 |
|---|---|
train() |
ModeKeys.TRAIN |
evaluate() |
ModeKeys.EVAL |
predict() |
ModeKeys.PREDICT |
例如,假设您实例化自定义 Estimator 来生成名为 classifier 的对象。然后,您做出以下调用:
classifier = tf.estimator.Estimator(...)
classifier.train(input_fn=lambda: my_input_fn(FILE_TRAIN, True, 500))
然后,Estimator 框架会调用模型函数并将 mode 设为 ModeKeys.TRAIN。
模型函数必须提供代码来处理全部三个 mode 值。对于每个 mode 值,您的代码都必须返回 tf.estimator.EstimatorSpec 的一个实例,其中包含调用程序需要的信息。我们来详细了解各个 mode。
预测
如果调用 Estimator 的 predict 方法,则 model_fn 会收到 mode = ModeKeys.PREDICT。在这种情况下,模型函数必须返回一个包含预测的 tf.estimator.EstimatorSpec。
该模型必须经过训练才能进行预测。经过训练的模型存储在磁盘上,位于您实例化 Estimator 时建立的 model_dir 目录中。
此模型用于生成预测的代码如下所示:
# Compute predictions.
predicted_classes = tf.argmax(logits, 1)
if mode == tf.estimator.ModeKeys.PREDICT:
predictions = {
'class_ids': predicted_classes[:, tf.newaxis],
'probabilities': tf.nn.softmax(logits),
'logits': logits,
}
return tf.estimator.EstimatorSpec(mode, predictions=predictions)
预测字典中包含模型在预测模式下运行时返回的所有内容。

predictions 存储的是下列三个键值对:
class_ids存储的是类别 ID(0、1 或 2),表示模型对此样本最有可能归属的品种做出的预测。probabilities存储的是三个概率(在本例中,分别是 0.02、0.95 和 0.03)logit存储的是原始对数值(在本例中,分别是 -1.3、2.6 和 -0.9)
我们通过 predictions 参数(属于 tf.estimator.EstimatorSpec)将该字典返回到调用程序。Estimator 的 predict 方法会生成这些字典。
计算损失
对于训练和评估,我们都需要计算模型的损失。这是要进行优化的目标。
我们可以通过调用 tf.losses.sparse_softmax_cross_entropy 来计算损失。此函数返回的值将是最低的,接近 0,而正确类别的概率(索引为 label)接近 1.0。随着正确类别的概率不断降低,返回的损失值越来越大。
此函数会针对整个批次返回平均值。
# Compute loss.
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
评估
如果调用 Estimator 的 evaluate 方法,则 model_fn 会收到 mode = ModeKeys.EVAL。在这种情况下,模型函数必须返回一个包含模型损失和一个或多个指标(可选)的 tf.estimator.EstimatorSpec。
虽然返回指标是可选的,但大多数自定义 Estimator 至少会返回一个指标。TensorFlow 提供一个指标模块 tf.metrics来计算常用指标。为简单起见,我们将只返回准确率。tf.metrics.accuracy 函数会将我们的预测值与真实值进行比较,即与输入函数提供的标签进行比较。tf.metrics.accuracy 函数要求标签和预测具有相同的形状。下面是对 tf.metrics.accuracy 的调用:
# Compute evaluation metrics.
accuracy = tf.metrics.accuracy(labels=labels,
predictions=predicted_classes,
name='acc_op')
针对评估返回的 EstimatorSpec 通常包含以下信息:
loss:这是模型的损失eval_metric_ops:这是可选的指标字典。
我们将创建一个包含我们的唯一指标的字典。如果我们计算了其他指标,则将这些指标作为附加键值对添加到同一字典中。然后,我们将在 eval_metric_ops 参数(属于 tf.estimator.EstimatorSpec)中传递该字典。具体代码如下:
metrics = {'accuracy': accuracy}
tf.summary.scalar('accuracy', accuracy[1])
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(
mode, loss=loss, eval_metric_ops=metrics)
tf.summary.scalar 会在 TRAIN 和 EVAL 模式下向 TensorBoard 提供准确率(后文将对此进行详细的介绍)。
训练
如果调用 Estimator 的 train 方法,则会调用 model_fn 并收到 mode = ModeKeys.TRAIN。在这种情况下,模型函数必须返回一个包含损失和训练操作的 EstimatorSpec。
构建训练操作需要优化器。我们将使用 tf.train.AdagradOptimizer,因为我们模仿的是 DNNClassifier,它也默认使用 Adagrad。tf.train 文件包提供很多其他优化器,您可以随意尝试它们。
下面是构建优化器的代码:
optimizer = tf.train.AdagradOptimizer(learning_rate=0.1)
接下来,我们使用优化器的 minimize 方法根据我们之前计算的损失构建训练操作。
minimize 方法还具有 global_step 参数。TensorFlow 使用此参数来计算已经处理过的训练步数(以了解何时结束训练)。此外,global_step 对于 TensorBoard 图能否正常运行至关重要。只需调用 tf.train.get_global_step 并将结果传递给 minimize 的 global_step 参数即可。
下面是训练模型的代码:
train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step())
针对训练返回的 EstimatorSpec 必须设置了下列字段:
loss:包含损失函数的值。train_op:执行训练步。
下面是用于调用 EstimatorSpec 的代码:
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op)
模型函数现已完成。
自定义 Estimator
通过 Estimator 基类实例化自定义 Estimator,如下所示:
# Build 2 hidden layer DNN with 10, 10 units respectively.
classifier = tf.estimator.Estimator(
model_fn=my_model,
params={
'feature_columns': my_feature_columns,
# Two hidden layers of 10 nodes each.
'hidden_units': [10, 10],
# The model must choose between 3 classes.
'n_classes': 3,
})
在这里,params 字典与 DNNClassifier 的关键字参数用途相同;即借助 params 字典,您无需修改 model_fn 中的代码即可配置 Estimator。
使用 Estimator 训练、评估和生成预测要用的其余代码与预创建的 Estimator 一章中的相同。例如,以下行将训练模型:
# Train the Model.
classifier.train(
input_fn=lambda:iris_data.train_input_fn(train_x, train_y, args.batch_size),
steps=args.train_steps)
TensorBoard
您可以在 TensorBoard 中查看自定义 Estimator 的训练结果。要查看相应报告,请从命令行启动 TensorBoard,如下所示:
# Replace PATH with the actual path passed as model_dir
tensorboard --logdir=PATH
然后,通过以下网址打开 TensorBoard:http://localhost:6006
所有预创建的 Estimator 都会自动将大量信息记录到 TensorBoard 上。不过,对于自定义 Estimator,TensorBoard 只提供一个默认日志(损失图)以及您明确告知 TensorBoard 要记录的信息。对于您刚刚创建的自定义 Estimator,TensorBoard 会生成以下内容:
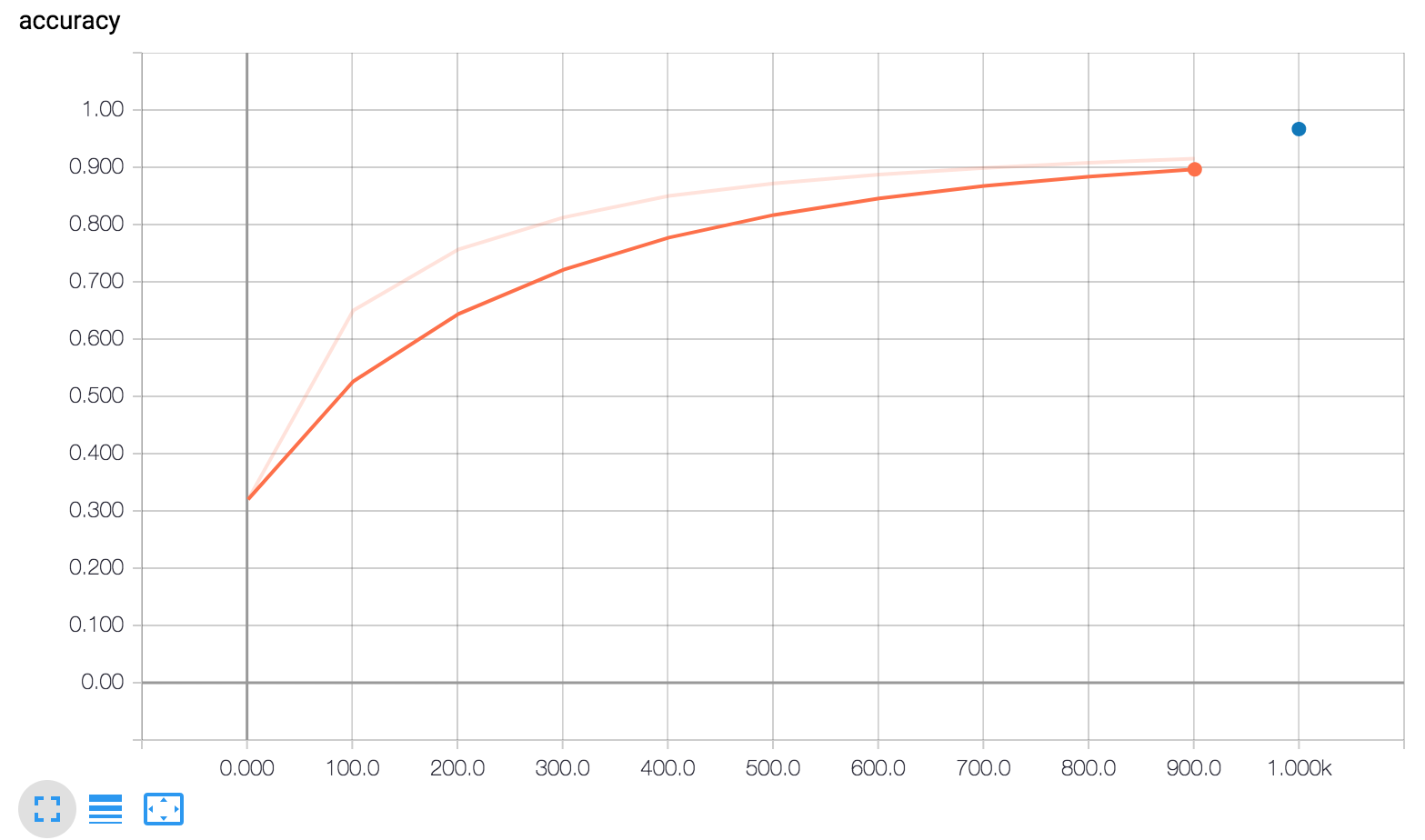
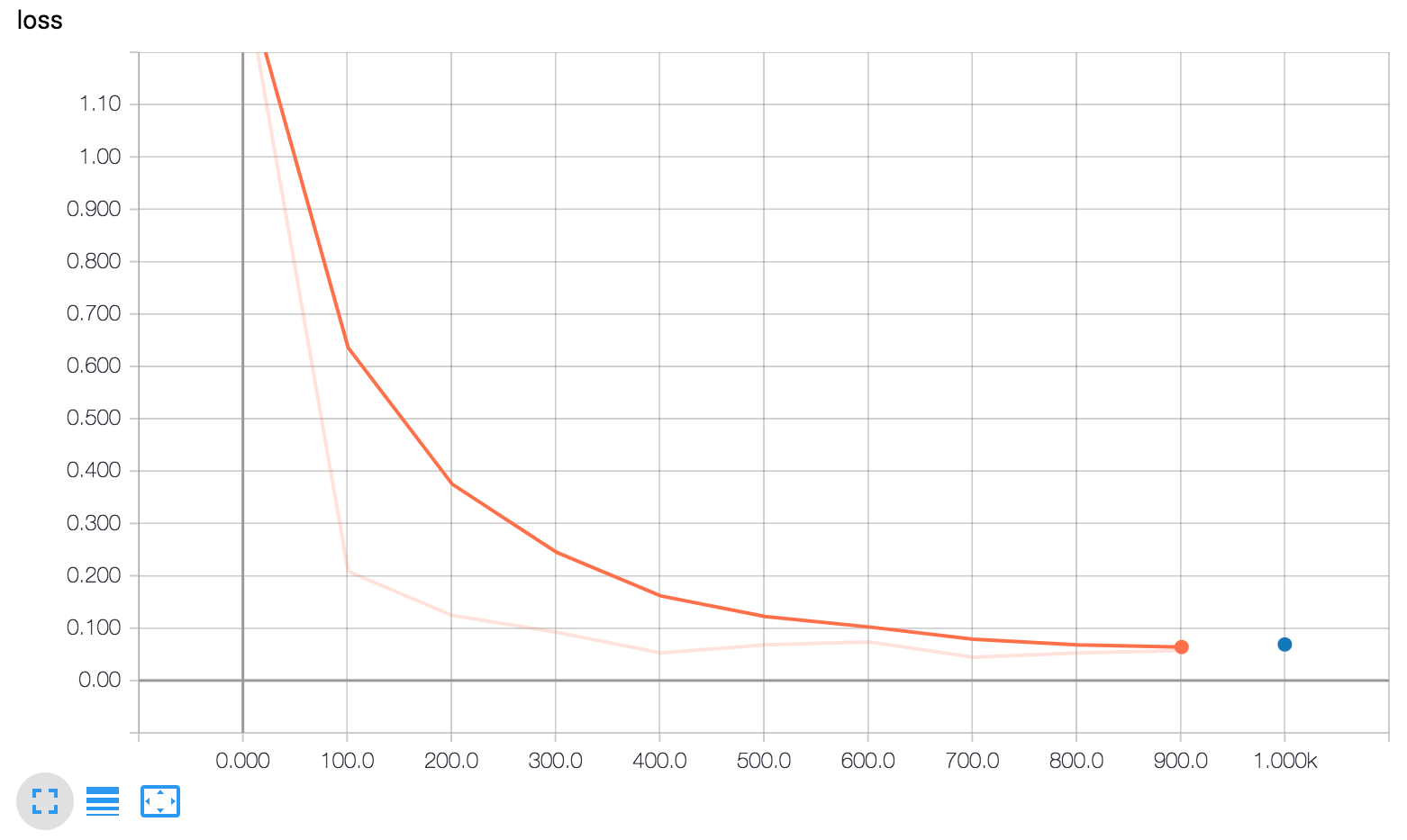
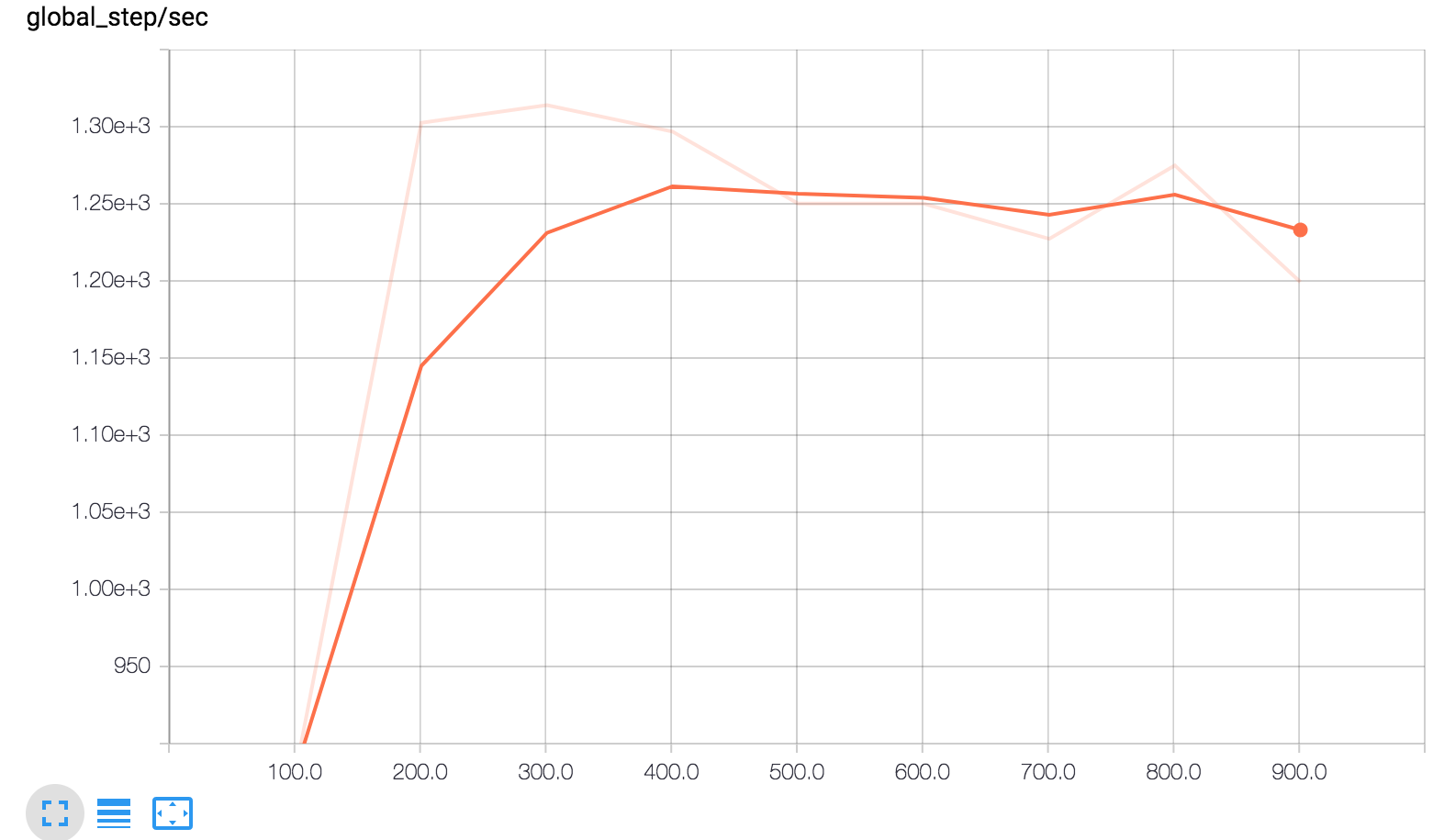
TensorBoard 显示了三张图。
简而言之,下面是三张图显示的内容:
global_step/sec:这是一个性能指标,显示我们在进行模型训练时每秒处理的批次数(梯度更新)。
loss:所报告的损失。
accuracy:准确率由下列两行记录:
eval_metric_ops={'my_accuracy': accuracy}(评估期间)。tf.summary.scalar('accuracy', accuracy[1])(训练期间)。
这些 Tensorboard 图是务必要将 global_step 传递给优化器的 minimize 方法的主要原因之一。如果没有它,模型就无法记录这些图的 x 坐标。
注意 my_accuracy 和 loss 图中的以下内容:
- 橙线表示训练。
- 蓝点表示评估。
在训练期间,系统会随着批次的处理定期记录摘要信息(橙线),因此它会变成一个跨越 x 轴范围的图形。
相比之下,评估在每次调用 evaluate 时仅在图上生成一个点。此点包含整个评估调用的平均值。它在图上没有宽度,因为它完全根据特定训练步(一个检查点)的模型状态进行评估。
如下图所示,您可以使用左侧的控件查看并选择性地停用/启用报告。
启用或停用报告。
总结
虽然使用预创建的 Estimator 可以快速高效地创建新模型,但您通常需要使用自定义 Estimator 才能实现所需的灵活性。幸运的是,预创建的 Estimator 和自定义 Estimator 采用相同的编程模型。唯一的实际区别是您必须为自定义 Estimator 编写模型函数;除此之外,其他都是相同的。
要了解详情,请务必查看:
- 官方 TensorFlow MNIST 实现:使用了自定义 Estimator。
- TensorFlow 官方模型代码库:其中包含更多使用自定义 Estimator 的精选示例。
- TensorBoard 视频:介绍了 TensorBoard。
- 低阶 API 简介:展示了如何直接使用 TensorFlow 的低阶 API 更轻松地进行调试。
创建自定义 Estimator的更多相关文章
- tensorflow创建自定义 Estimator
https://www.tensorflow.org/guide/custom_estimators?hl=zh-cn 创建自定义 Estimator 本文档介绍了自定义 Estimator.具体而言 ...
- ASP.NET MVC随想录——创建自定义的Middleware中间件
经过前2篇文章的介绍,相信大家已经对OWIN和Katana有了基本的了解,那么这篇文章我将继续OWIN和Katana之旅——创建自定义的Middleware中间件. 何为Middleware中间件 M ...
- 带你走近AngularJS - 创建自定义指令
带你走近AngularJS系列: 带你走近AngularJS - 基本功能介绍 带你走近AngularJS - 体验指令实例 带你走近AngularJS - 创建自定义指令 ------------- ...
- [转]maven创建自定义的archetype
创建自己的archetype一般有两种方式,比较简单的就是create from project 1.首先使用eclipse创建一个新的maven project,然后把配置好的一些公用的东西放到相应 ...
- ArcGIS Engine环境下创建自定义的ArcToolbox Geoprocessing工具
在上一篇日志中介绍了自己通过几何的方法合并断开的线要素的ArcGIS插件式的应用程序.但是后来考虑到插件式的程序的配置和使用比较繁琐,也没有比较好的错误处理机制,于是我就把之前的程序封装成一个类似于A ...
- Dockerfile创建自定义Docker镜像以及CMD与ENTRYPOINT指令的比较
1.概述 创建Docker镜像的方式有三种 docker commit命令:由容器生成镜像: Dockerfile文件+docker build命令: 从本地文件系统导入:OpenVZ的模板. 关于这 ...
- .NET微信公众号开发-2.0创建自定义菜单
一.前言 开发之前,我们需要阅读官方的接口说明文档,不得不吐槽一下,微信的这个官方文档真的很烂,但是,为了开发我们需要的功能,我们也不得不去看这些文档. 接口文档地址:http://mp.weixin ...
- HTML5 UI框架Kendo UI Web教程:创建自定义组件(三)
Kendo UI Web包 含数百个创建HTML5 web app的必备元素,包括UI组件.数据源.验证.一个MVVM框架.主题.模板等.在前面的2篇文章<HTML5 Web app开发工具Ke ...
- HTML5 UI框架Kendo UI Web中如何创建自定义组件(二)
在前面的文章<HTML5 UI框架Kendo UI Web自定义组件(一)>中,对在Kendo UI Web中如何创建自定义组件作出了一些基础讲解,下面将继续前面的内容. 使用一个数据源 ...
随机推荐
- 【TIDB】4、业界使用情况
一.小米 1.背景 小米关系型存储数据库首选 MySQL,单机 2.6T 磁盘.由于小米手机销量的快速上升和 MIUI 负一屏用户量的快速增加,导致负一屏快递业务数据的数据量增长非常快, 每天的读写量 ...
- DOM事件-级别
DOM事件0~3 不同级别的DOM事件因其实现方式不同,都有自己的特性. 0级:是在dom元素上提供相关事件类型属性,js程序可以通过这些特定类型的属性注册事件处理程序. 特性:一个元素同种类型的事件 ...
- Jmeter 跨线程组传递参数 之两种方法
终于搞定了Jmeter跨线程组之间传递参数,这样就不用每次发送请求B之前,都需要同时发送一下登录接口(因为同一个线程组下的请求是同时发送的),只需要发送一次登录请求,请求B直接用登录请求的参数即可,直 ...
- HDU-3072-IntelligenceSystem(tarjan,贪心)
链接:https://vjudge.net/problem/HDU-3072 题意: 给你n个点,1个点到另一个点连接花费c,但是如果几个点可以相互可达,则这几个点连通花费为0. 求将整个图连通的最小 ...
- [NWPU2016][寒假作业][正常版第三组]I
素数环,简单的dfs,但这道题我有个小地方写错了半天发现不了..就是flag数组的位置.一定要放在if里面,刚开始没注意,一不小心写到外面了. #include <iostream> #i ...
- CentOS7.2配置本地yum源
1.检查是否有本地yum源 1)检查是否能连网 ping www.baidu.com 2)检查是否有本地yum源 yum list 2.挂载镜像文件 以上检查,说明确实是内网,也确实没有本地yum源, ...
- SQL 索引查找
索引查找信息 在非聚集索引里,会为每条记录存储一份非聚集索引索引键的值和一份聚集索引索引键 [在没有聚集索引的表格里,是RID值指向数据页面,有聚集索引的话指向聚集索引的键(在不使用include时) ...
- XML文件的一些操作
XML 是被设计用来传输和存储数据的, XML 必须含有且仅有一个 根节点元素(没有根节点会报错) 源码下载 http://pan.baidu.com/s/1ge2lpM7 好了,我们 先看一个 XM ...
- C# 操作 sqlite
1.下载sqlite:http://system.data.sqlite.org/downloads/1.0.94.0/sqlite-netFx20-setup-bundle-x86-2005-1.0 ...
- spring中自动装配bean
首先用@Component注解类: package soundsystem: import org.springframework.stereotype.Component; @Component p ...