PostgreSQL 务实应用(三/5)分表复制
问题的提出
在项目中,有些表的记录增长非常快,记录数过大时会使得查询变得困难,导致整个数据库处理性能下降。此时,我们会考虑按一定的规则进行分表存储。
常用的分表方式是按时间周期,如每月一张,每天一张等。当每月或每天首条记录到达时,根据表结构创建该周期为后缀的表进行存储。
相关考虑
这其中主要考虑两个问题:
(1)如何复制表
采用分表机制,通常会建立一个模板表。所谓模板表,是只定义结构不存储数据的,也可称之为类表,而分表,通常会以增加后缀的方式命名,如 log_201901,分表实际存储数据,可称之为实例表。
表存在关联、键、索引、约束等,这让表的复制听起来比较繁琐,即便通过元数据得到这些信息,还需要自己考虑如索引的命名冲突等问题。而 PostgreSQL 为我们提供了极其便捷的方式。
CREATE TABLE [IF NOT EXISTS] 实例表 (LIKE 模板表 [INCLUDING ALL]);
其中 [ ] 内表示可选项,INCLUDING 除了 ALL 还要其它细分的选项,具体可参考帮助文档。
(2)数据存储的逻辑过程
首先得知道表存不存在,不存在则要创建,然后执行数据操作语句。
由于表名是动态的,在应用系统中可以先取得表名形成 SQL 语句再执行,在数据库存储过程中则可以使用 EXECUTE 执行动态SQL语句。
分表实例
下边,本文以日志记录表为例来完整地实践分表处理过程。
功能描述:日志数量大,当前日志查询频繁,历史日志需要全部保存。要求每天一个分表,日志主键要求全局保持唯一性(即多个分表间不重复),日志到达自动根据当前的时间进行分表存储。
首先创建日志模板表,命名为 log_template,并为其建立相关索引,主键序列。
-- 创建模板表,log_id 主键,log_at 日志时间, log_content 日志内容
CREATE TABLE log_template (log_id bigint PRIMARY KEY,
log_at timestamp, log_content varchar(1000));
-- 对日志时间索引
CREATE INDEX idx_log_at on log_template (log_at);
-- 用于主键的序列(各分表使用同一序列)
CREATE SEQUENCE seq_log_id;
我们通过一个过程来完成日志的自动分表存储。
CREATE OR REPLACE FUNCTION func_log(v_conent varchar) RETURNS bool LANGUAGE 'plpgsql'
AS $$
DECLARE
lv_log_at timestamp := current_timestamp;
lv_suffix_tname varchar; -- 带后缀的分表名
lv_dsql text; -- 动态SQL
BEGIN
-- 根据时间得到应使用的分表名称
lv_suffix_tname := 'log_' || to_char(lv_log_at, 'YYYYMMDD');
-- 判断是否存在,不存在时复制模板创建分表
lv_dsql := 'CREATE TABLE IF NOT EXISTS ' || lv_suffix_tname || ' (LIKE log_template INCLUDING ALL)';
EXECUTE lv_dsql;
-- 将数据保存至分表
lv_dsql := 'INSERT INTO ' || lv_suffix_tname || '(log_id, log_at, log_content) VALUES($1, $2, $3)';
EXECUTE lv_dsql USING nextval('seq_log_id'), lv_log_at, v_conent;
RETURN true;
END $$;
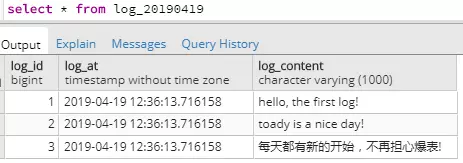
执行以下语句来看看预期的结果。
SELECT func_log('hello, the first log!');
SELECT func_log('toady is a nice day!');
SELECT func_log('每天都有新的开始,不再担心爆表!');
结束语
分表能够避免单表记录过于庞大,提高查询性能。但同时,分表也会给部分查询或数据处理带有复杂性,因此是否分表应该根据业务需要来,同时应尽早规划,后期更改相对繁琐。
在 MySQL 中也有类似的 CREATE TABLE LIKE 语法,我想都是应运而生,简单就是美。
PostgreSQL 务实应用(三/5)分表复制的更多相关文章
- Mysql性能优化三(分表、增量备份、还原)
接上篇Mysql性能优化二 对表进行水平划分 如果一个表的记录数太多了,比如上千万条,而且需要经常检索,那么我们就有必要化整为零了.如果我拆成100个表,那么每个表只有10万条记录.当然这需要数据在逻 ...
- elasticsearch系列(三)分表分库
首先ES没有库和表的概念,只有index,type,document(详细术语可以看ES的系列一 http://www.cnblogs.com/ulysses-you/p/6736926.html), ...
- mysql 分表与分区
一.操作环境 数据达到百w甚于更多的时候,我们的mysql查询将会变得比较慢, 如果再加上连表查询,程序可能会卡死.即使你设置了索引并在查询中使用到了索引,查询还是会慢.这时候你就要考虑怎么样来提高查 ...
- MySQL分表
一.概念 1.为什么要分表和分区?日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询 ...
- MySQL分区和分表
一.概念 1.为什么要分表和分区?日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询 ...
- MySql从一窍不通到入门(五)Sharding:分表、分库、分片和分区
转载:用sharding技术来扩展你的数据库(一)sharding 介绍 转载:MySQL架构方案 - Scale Out & Scale Up. 转载: 数据表分区策略及实现(一) 转载:M ...
- MySql分库分表与分区的区别和思考
一.分分合合 说过很多次,不要拘泥于某一个技术的一点,技术是相通的.重要的是编程思想,思想是最重要的.当数据量大的时候,需要具有分的思想去细化粒度.当数据量太碎片的时候,需要具有合的思想来粗化粒度. ...
- mysql分表的三种方法
先说一下为什么要分表当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间.根据个人经验,mysql执行一 ...
- SpringCloud微服务实战——搭建企业级开发框架(二十七):集成多数据源+Seata分布式事务+读写分离+分库分表
读写分离:为了确保数据库产品的稳定性,很多数据库拥有双机热备功能.也就是,第一台数据库服务器,是对外提供增删改业务的生产服务器:第二台数据库服务器,主要进行读的操作. 目前有多种方式实现读写分离,一种 ...
随机推荐
- 转_【大话IT】你离大数据架构师有多远?
话题背景: 首先,先科普下“数据架构师”的相关职责:数据架构师要负责建立和维持公司数据储存的技术基准,策划硬体和软体的结构,确保数据储存系统可以支持未来的数据量和分析需求. 据了解,美国地区数据架构师 ...
- jquery动态加载脚本
如果你使用的是jQuery,它里面有一个内置的方法可以用来加载单个JS文件.当你需要延迟加载一些js插件或其它类型的文件时,可以使用这个方法. 一.jQuery getScript()方法加载java ...
- Sping框架概述
一.什么是spring框架 spring是J2EE应用程序框架,是轻量级的IoC和AOP的容器框架,主要是针对javaBean的生命周期进行管理的轻量级容器,可以单独使用,也可以和Struts框架,i ...
- 关于js开发的小问题
一.开发当中经常会动态拼接html,当然为了简便性好多人直接就是使用内联事件: $('#td1').html( '<a href="#" onclick="app. ...
- Hadoop实战-Flume之Hdfs Sink(十)
a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = ...
- 在图片上加字符-base64转图片-图片转base64
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- LLVM的总结
LLVM 写在前面的话:无意中看到的LLVM的作者Chris Lattner相关的介绍和故事,觉得很有意思就贴上来,如果不感兴趣,可以直接跳入下一章. 关于LLVM 如果你对LLVM的由来陌生,那么我 ...
- emWin 移植 - 基于红牛开发板
一直想利用所学的东西自己设计一个精致一些的作品,手头正好有一块红牛开发板,就先用它来写一些软件,熟悉一下过程和一些想法的可行性.首先当然是选择一个操作系统了,对比了几种之后选择了emWin.那就移植一 ...
- (linux)BSP板级支持包开发理解
1. 概述 嵌入式系统由硬件环境.嵌入式操作系统和应用程序组成,硬件环境是操作系统和应用程序运行的硬件平台,它随应用的不同而有不同的要求.硬件平台的多样性是嵌入式系统的主要特点,如何使嵌入式操作系统在 ...
- HDU5950 Recursive sequence —— 矩阵快速幂
题目链接:https://vjudge.net/problem/HDU-5950 Recursive sequence Time Limit: 2000/1000 MS (Java/Others) ...