Spark学习(二) -- Spark整体框架
标签(空格分隔): Spark
还记得上次的wordCount程序嘛?通过这个小程序,我们来一窥Spark的框架是什么样子的。
sc.textFile("/usr/local/Cellar/apache-spark/1.3.0/README.md").flatMap(line => line.split(" ")).map(w => (w, 1)).reduceByKey(_+_).foreach(println)
整个单词统计的过程可以分为4个阶段:1)读取文件;2)单词分割;3)单词计数;4)单词归并。前三步都是非常容易并行的,但最后一步的并行度并不是很高。
RDD
将上面的单词计数操作用另一种形式表示:
Data1 ---Operation1---> Data2 ---Operation2---> Data3 ...... -->DataN
所以,整个过程其实就是在不断的进行数据输入和数据处理。
RDD(Resilient Distributed Dataset),弹性分布式数据集,用来包装数据输入和数据处理,其主要特点是:
- 数据全集被分割为多个正相交的子集,每个子集可以被派发到任一计算节点进行处理;
- 计算的中间结果会被保存。出于可靠性,同一个计算结果会被保存于多个计算节点;
- 如果其中某一数据子集在处理中出现问题,针对该子集的处理会被重新调度进而重新处理。
Operation
Operation有两种类型:Transformation和Action。
- Transformation是领取任务的过程;
- Action则是真正触发执行的过程。
Spark的运行框架
1. 作业提交
Spark在接收到提交的作业后,会进行如下处理:
- RDD之间的依赖性分析。RDD之间形成一个有向无环图,这个依赖关系的分析和判断由DAGScheduler负责;
- 根据DAG的分析结果将一个作业分成多个Stage。划分Stage的一个主要依据就是当前的计算因子输入是否是确定的,如果是则划分在一个Stage中;
- DAGScheduler确定完Stage之后,会向TaskScheduler提交任务集,而TaskScheduler负责将这些任务一一分到集群的计算节点。
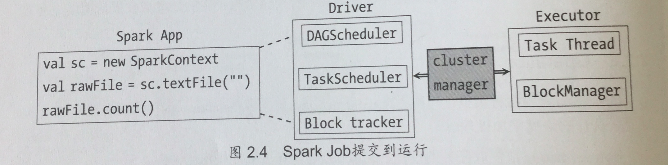
2. 集群节点的构成
Spark集群由4个节点构成:Driver, Master, Worker, Executor.
Spark学习(二) -- Spark整体框架的更多相关文章
- Spark学习之Spark调优与调试(7)
Spark学习之Spark调优与调试(7) 1. 对Spark进行调优与调试通常需要修改Spark应用运行时配置的选项. 当创建一个SparkContext时就会创建一个SparkConf实例. 2. ...
- Spark学习之Spark Streaming(9)
Spark学习之Spark Streaming(9) 1. Spark Streaming允许用户使用一套和批处理非常接近的API来编写流式计算应用,这就可以大量重用批处理应用的技术甚至代码. 2. ...
- Spark学习之Spark SQL(8)
Spark学习之Spark SQL(8) 1. Spark用来操作结构化和半结构化数据的接口--Spark SQL. 2. Spark SQL的三大功能 2.1 Spark SQL可以从各种结构化数据 ...
- Spark学习之Spark调优与调试(二)
下面来看看更复杂的情况,比如,当调度器进行流水线执行(pipelining),或把多个 RDD 合并到一个步骤中时.当RDD 不需要混洗数据就可以从父节点计算出来时,调度器就会自动进行流水线执行.上一 ...
- Spark学习(一) Spark初识
一.官网介绍 1.什么是Spark 官网地址:http://spark.apache.org/ Apache Spark™是用于大规模数据处理的统一分析引擎. 从右侧最后一条新闻看,Spark也用于A ...
- Spark学习一:Spark概述
1.1 什么是Spark Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. 一站式管理大数据的所有场景(批处理,流处理,sql) spark不涉及到数据的存储,只 ...
- Spark学习之Spark Streaming
一.简介 许多应用需要即时处理收到的数据,例如用来实时追踪页面访问统计的应用.训练机器学习模型的应用,还有自动检测异常的应用.Spark Streaming 是 Spark 为这些应用而设计的模型.它 ...
- Spark学习之Spark调优与调试(一)
一.使用SparkConf配置Spark 对 Spark 进行性能调优,通常就是修改 Spark 应用的运行时配置选项.Spark 中最主要的配置机制是通过 SparkConf 类对 Spark 进行 ...
- Spark学习笔记--Spark在Windows下的环境搭建
本文主要是讲解Spark在Windows环境是如何搭建的 一.JDK的安装 1.1 下载JDK 首先需要安装JDK,并且将环境变量配置好,如果已经安装了的老司机可以忽略.JDK(全称是JavaTM P ...
- Spark学习笔记--Spark在Windows下的环境搭建(转)
本文主要是讲解Spark在Windows环境是如何搭建的 一.JDK的安装 1.1 下载JDK 首先需要安装JDK,并且将环境变量配置好,如果已经安装了的老司机可以忽略.JDK(全称是JavaTM P ...
随机推荐
- 可爱的Python_课后习题_CDay0 时刻准备着!发布
请根据软件发布的流程和软件开发的编码规范,将读者在前面章节所写的程序修改并发 布出去.另外,可以查找下除了 epydoc 外还有哪些较好的 py 文档生成器? pydoc是Python自带的模块,主要 ...
- 对bootstrap中confirm alert进行封装
HTML: <!-- system modal start --> <div id="ycf-alert" class="modal"> ...
- Python —条件语句
条件语句 Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块. 可以通过下图来简单了解条件语句的执行过程: Python程序语言指定任何非0和非空(null ...
- ZOJ 2412 Farm Irrigation
Farm Irrigation Time Limit: 2 Seconds Memory Limit: 65536 KB Benny has a spacious farm land to ...
- com.android.ide.common.process.ProcessException: org.gradle.process.internal.ExecException: Process 'command ' finished with non-zero exit value 1
Error:Execution failed for task ':lenovoAlbum:processReleaseResources'. > com.android.ide.common. ...
- union和union all有什么不同?
union和union all有什么不同? 相同点:用来获取两个或者两个以上结果集的并集 不同点: union会自动去重,排序 union all没有去重,排序
- tk画图
Page 387 of chapter 7 """ 6-23 page 343 play media files """ def odd() ...
- linux mysql root密码重置
MySQL安装解决方法:重改密码 先停止 Mysql # stop mysql 重要:输入下面的代码# mysqld_safe --user=mysql --skip-grant-tables --s ...
- 什么是JAVAbean
JavaBean 是一种JAVA语言写成的可重用组件.为写成JavaBean,类必须是具体的和公共的,并且具有无参数的构造器.JavaBean 通过提供符合一致性设计模式的公共方法将内部域暴露成员属性 ...
- $.Ajax({});方法使用 返回json格式 string格式
//Json格式 $.ajax({ url: url + "?action=Save1", type: "post", dataType: "json ...