SQL Server逻辑读、预读和物理读
SQL Server数据存储的形式
- 预读:用估计信息,去硬盘读取数据到缓存。预读100次,也就是估计将要从硬盘中读取了100页数据到缓存。
- 物理读:查询计划生成好以后,如果缓存缺少所需要的数据,让缓存再次去读硬盘。物理读10页,从硬盘中读取10页数据到缓存。
- 逻辑读:从缓存中取出所有数据。逻辑读100次,也就是从缓存里取到100页数据。
SQL Server存储的最小单位是页,每一页大小为8K,SQL Server对于页的读取是原子性的,要么读完一页,要么完全不读。即使是仅仅要获得一条数据,也要读完一页。而页之间的数据组织结构为B树结构。所以SQL Server对于逻辑读、预读、物理读的单位是页。
先来看一个查询:
DBCC DROPCLEANBUFFERS --清空缓存
SET STATISTICS IO ON --开启IO统计
SELECT * FROM Person --查询语句
显示消息如下:
(147517 行受影响)
表 'Person'。扫描计数 1,逻辑读取 2237 次,物理读取 6 次,预读 2226 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响)
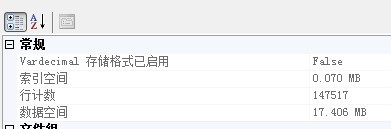
上表的大小是17.406M。
每一页存储的数据是:8K=8192字节-96字节(页头)-36字节(行偏移)= 8060字节。
17.406*1024*1024 / 8060 ≈ 2 264
另外表中还有一些非数据占用的空间,因此上式的结果约等于逻辑读次数。
基本上,逻辑读、物理读、预读都等于是扫描了多少个页。
从执行顺序上理解各种读
SQL Server的查询从理解各种读的步骤来看,可以理解为以下图:
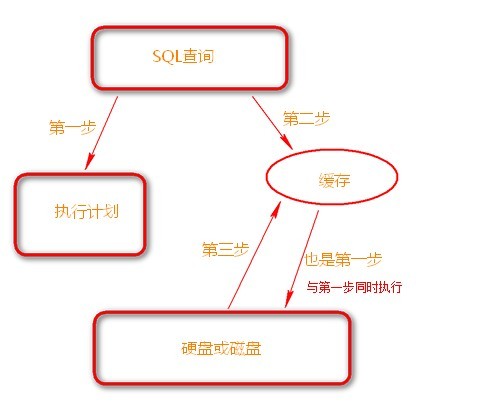 (图是CareySon大哥的)
(图是CareySon大哥的)
通过上图来讲解各种读:
当SQL Server执行一个查询语句时,SQL Serer会开始第一步,生成查询计划,同时用估计的数据去磁盘读取数据(预读),这两个第一步是并行的。SQL Server通过这种方式来提高查询性能。
查询计划生成好了以后去缓存读取数据,当发现缓存缺少所需要的数据后让缓存再次去读硬盘(物理读),然后从缓存中取出所有数据(逻辑读)。
估计的页数可以通过DMV看到
SELECT
page_count
FROM sys.dm_db_index_physical_stats
(DB_ID('TestDataCenter'),OBJECT_ID('Person'),NULL,NULL,'sampled')
显示结果如下:

SQL Server就是根据这个东西进行预读。
如果此时我们再执行上面的查询语句:
SELECT * FROM Person --查询语句
看到消息如下:
(147517 行受影响)
表 'Person'。扫描计数 1,逻辑读取 2237 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响)
为什么这次全部都是逻辑读呢。因为刚才读过一次,数据全部都已经在缓存当中了,只需要从缓存中读就可以了,不需要再读取硬盘。
本文学习自:http://www.cnblogs.com/CareySon/archive/2011/12/23/2299127.html
SQL Server逻辑读、预读和物理读的更多相关文章
- 初谈SQL Server逻辑读、物理读、预读
前言 本文涉及的内容均不是原创,是记录自己在学习IO.执行计划的过程中学习其他大牛的博客和心得并记录下来,之所以想写下来是为了记录自己在追溯的过程遇到的几个问题,并把这些问题弄清楚. 本章最后已贴出原 ...
- 初谈SQL Server逻辑读、物理读、预读【转】
前言 本文涉及的内容均不是原创,是记录自己在学习IO.执行计划的过程中学习其他大牛的博客和心得并记录下来,之所以想写下来是为了记录自己在追溯的过程遇到的几个问题,并把这些问题弄清楚. 本章最后已贴出原 ...
- SQL SERVER 2005修改数据库名称,包括物理文件名和逻辑名称
SQL SERVER 2005修改数据库名称,包括物理文件名和逻辑名称 原来数据库名称为 aa,物理文件名称为 aa.mdf 和 aa_log.ldf: 需要修改数据库名称为 bb,物理文件名 ...
- SQL Server索引进阶:第九级,读懂执行计划
原文地址: Stairway to SQL Server Indexes: Level 9,Reading Query Plans 本文是SQL Server索引进阶系列(Stairway to SQ ...
- 理解SQL SERVER中的逻辑读,预读和物理读
转自:https://www.cnblogs.com/CareySon/archive/2011/12/23/2299127.html 在我的上一篇关于SQL SERVER索引的博文,有圆友问道关于逻 ...
- SQL Server中STATISTICS IO物理读和逻辑读的误区
SQL Server中STATISTICS IO物理读和逻辑读的误区 大家知道,SQL Server中可以利用下面命令查看某个语句读写IO的情况 SET STATISTICS IO ON 那么这个命令 ...
- sqlserver性能调优中的逻辑读,物理读,预读是什么意思
表 'T_EPZ_INOUT_ENTRY_DETAIL'.扫描计数 1,逻辑读 4825 次,物理读 6 次,预读 19672 次.SQL SERVER 数据库引擎当遇到一个查询语句时,SQL SER ...
- SQL Server 中的事务与事务隔离级别以及如何理解脏读, 未提交读,不可重复读和幻读产生的过程和原因
原本打算写有关 SSIS Package 中的事务控制过程的,但是发现很多基本的概念还是需要有 SQL Server 事务和事务的隔离级别做基础铺垫.所以花了点时间,把 SQL Server 数据库中 ...
- SQL Server中的事务与其隔离级别之脏读, 未提交读,不可重复读和幻读
原本打算写有关 SSIS Package 中的事务控制过程的,但是发现很多基本的概念还是需要有 SQL Server 事务和事务的隔离级别做基础铺垫.所以花了点时间,把 SQL Server 数据库中 ...
随机推荐
- Android 环境搭建
一.Android 环境搭建 开发工具: Android Studio(开发工具,前提是先装 java JDK) 下载地址:http://www.androiddevtools.cn/ Oracl ...
- 蛙蛙推荐:WEB安全入门
信息安全基础 信息安全目标 真实性:对信息的来源进行判断,能对伪造来源的信息予以鉴别, 就是身份认证. 保密性:保证机密信息不被窃听,盗取,或窃听者不能了解信息的真实含义. 完整性:保证数据的一致性, ...
- Android 各层调用的方式
所有的android的app启动都有三种深入启动的方式: ①app——Runtime Service——Lib 这种启动方式是: Ⅰapp程序中启动application framework 层中Ru ...
- ENode 1.0 - 框架的总体目标
开源地址:https://github.com/tangxuehua/enode 本文想介绍一下enode框架要实现的目标以及部分实现分析思路剖析.总体来说enode框架是一个基于cqrs架构和消息驱 ...
- Sensor(GYROSCOPE)
package com.example.sensor01; import java.util.List; import android.hardware.Sensor; import android. ...
- dojo/dom源码学习
dojo/dom模块作为一个基础模块,最常用的就是byId方法.除此之外还有isDescendant和setSelectable方法. dom.byId(myId)方法: 各种前端类库都免不了与D ...
- JavaScript使用DeviceOne开发实战(四)仿优酷视频应用
开发之前需要考虑系统的差异性,比如ios手机没有回退键,所以在开发时一定要考虑二级界面需要有回退键,否则ios的手机就会陷入到这个页面出不去了.安卓系统有回退键,针对这个情况需要要求用户在3秒钟之内连 ...
- .net开发笔记(十二) 设计时与运行时的区别(续)
上一篇博客详细讲到了设计时(DesignTime)和运行时(RunTime)的概念与区别,不过没有给出实际的Demo,今天整理了一下,做了一个例子,贴出来分享一下,巩固前一篇博客讲到的内容. 简单回顾 ...
- Homework 1 -- The beginning
我是在北京在读的一位大学生.如果问我学的什么专业,我会用一个冷笑话回答你:我精通多种语言,在老家我说家乡话:跟北京我讲普通话:跟老外就玩English:我跟机器得敲代码.现在你知道我学的就是计算机了. ...
- AngularJS快速入门指南17:Includes
使用AngularJS,你可以在HTML中包含其它的HTML文件. 在HTML中包含其它HTML文件? 当前的HTML文档还不支持该功能.不过W3C建议在后续的HTML版本中增加HTML import ...