Spark API 之 combineByKey(一)
1 前言
combineByKey是使用Spark无法避免的一个方法,总会在有意或无意,直接或间接的调用到它。从它的字面上就可以知道,它有聚合的作用,对于这点不想做过多的解释,原因很简单,因为reduceByKey、aggregateByKey、foldByKey等函数都是使用它来实现的。
combineByKey是一个高度抽象的聚合函数,可以用于数据的聚合和分组,由它牵出的shuffle也是Spark中重中之重,现在就让我们去看看它到底是怎么去实现的。
不足或错误之处, 烦请指出更正。
2 方法源码介绍
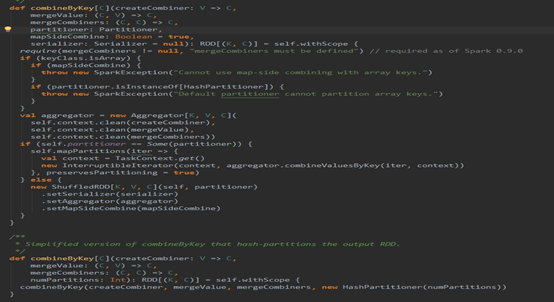
这是PairRDDFunctions里面的combineByKey的方法片段,这两个方法放在一块,就是说明了,调用该方法若不填分区函数Partitioner则使用HashPartitioner,默认情况下会使用Map段合并(这个是对shuffle而言的)。
3 方法源码走读
废话不多说,直接贴源码,
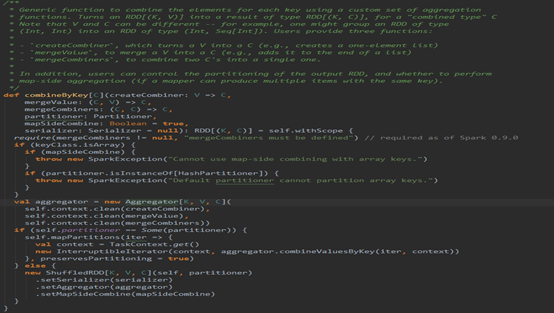
有注释,则看注释,注释要表达的意思就是combineByKey是一个范函数,使用一组自定义聚合函数以Key为聚合条件进行聚合,至于其他的就不多说了,往下看代码。
首先就进行了判断,Key是否为数组,假如是数组则不能使用Map段合并和HashPartitioner,原因:
要想进行Map段合并和Hash分区,那么Key就必须可以通过比较内容是否相同来确定Key是否相等以及通过内容计算hash值,进而进行合并和分区,然而数组判断相等和计算hash值并不是根据它里面的内容,而是根据数组在堆栈中的信息来实现的。
接着往下,构造了一个Aggregator,这玩意可以说是combineByKey的核心,因为聚合全是交给它来完成的。进去看看下Aggregator。

上面是Aggregator的默认构造器,需要传入三个自定义的方法,现在重点说说这三个方法的意义:
首先紧跟着Aggregator的三个泛型,第一个K,这个是你进行combineByKey也就是聚合的条件Key,可以是任意类型。后面的V,C两个泛型是需要聚合的值的类型,和聚合后的值的类型,两个类型是可以一样,也可以不一样,例如,Spark中用的多的reduceByKey这个方法,若聚合前的值为long,那么聚合后仍为long。再比如groupByKey,若聚合前为String,那么聚合后为Iterable<String>。
再看三个自定义方法:
- createCombiner
这个方法会在每个分区上都执行的,而且只要在分区里碰到在本分区里没有处理过的Key,就会执行该方法。执行的结果就是在本分区里得到指定Key的聚合类型C(可以是数组,也可以是一个值,具体还是得看方法的定义了。)
2. mergeValue
这方法也会在每个分区上都执行的,和createCombiner不同,它主要是在分区里碰到在本分区内已经处理过的Key才执行该方法,执行的结果就是将目前碰到的Key的值聚合到已有的聚合类型C中。
其实方法1和2放在一起看,就是一个if判断条件,进来一个Key,就去判断一下若以前没出现过就执行方法1,否则执行方法2.
3. mergeCombiner
前两个方法是实现分区内部的相同Key值的数据合并,而这个方法主要用于分区间的相同Key值的数据合并,形成最终的结果。
接下来就看看Aggregator实现了哪些方法。
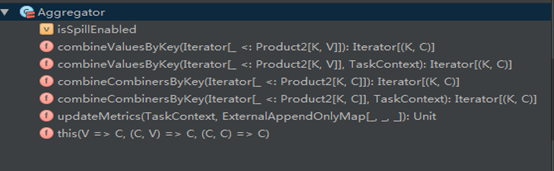
从它的方法列表上来看,其实就它只有三个方法,那就依次来看看这三个方法是干嘛的:
- combineValuesByKey
看到这个名字,再根据构造器,就可以猜出,这个方法主要实现的就是分区内部的数据合并。看它的代码:
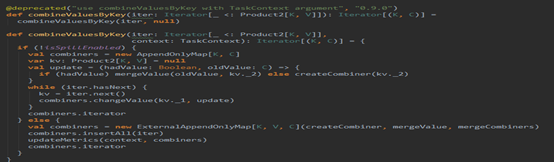
这里根据是否可以刷磁盘分了两条路,其实做的事情都是一样的,区别是在存储数据的时候一个当内存不够是直接oom,一个是可以刷磁盘。代码的实现很简单,就是迭代一个分区的数据,然后不断插入或更新Map里面的数据,这里就不再细说。
2. combineCombinersByKey
这个方法主要是实现分区间的数据合并,也就是合并combineValuesByKey的结果,看它是怎么实现的:

代码就不说了,和combineValuesByKey如出一辙,只是使用的自定义的方法不同而已。
3. updateMetrics
这个方法和刷磁盘有关,

就是记录下,当前是否刷了磁盘,刷了多少。
到这里Aggregator就结束了,接着combineByKey往下。
实例化Aggregator后,接着就是判断,是否需要重新分区(shuffle):
- 不需要分区
当self.partitioner == Some(partitioner)时,也就是分区实例是同一个的时候,就不需要分区了,因此只需要对先用的分区进行combineValuesByKey操作就好了,没有分区间的合并了,也不需要shuffle了。
2. 需要分区
两个分区器不一样,需要对现在分区的零散数据按Key重新分区,目的就是在于将相同的Key汇集到同一个分区上,由于数据分布的不确定性,因此有可能现在的每个分区的数据是由重新分区后的所有分区的部分数据构成的(宽依赖),因此需要shuffle,则构建ShuffledRDD,
其实到这里,我们就应该意识到,combineByKey的关键在于分区器partitioner,它是针对分区的一个操作,分区器的选择就决定了执行combineByKey后的结果,如果所给的分区器不能保证相同的Key值被分区到同一个分区,那么最终的合并的结果可能存在多个分区里有相同的Key。
Shuffle的目的就是将零散于所有分区的数据按Key分区并集中。
需要shuffle的部分下部分再细说。
Spark API 之 combineByKey(一)的更多相关文章
- Spark:将RDD[List[String,List[Person]]]中的List[Person]通过spark api保存为hdfs文件时一直出现not serializable task,没办法找到"spark自定义Kryo序列化输入输出API"
声明:本文转自<在Spark中自定义Kryo序列化输入输出API> 在Spark中内置支持两种系列化格式:(1).Java serialization:(2).Kryo seriali ...
- [Dynamic Language] pyspark Python3.7环境设置 及py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe解决!
pyspark Python3.7环境设置 及py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spa ...
- 03、IDEA下Spark API编程
03.IDEA下Spark API编程 3.1 编程实现Word Count 3.1.1 创建Scala模块 3.1.2 添加maven支持,并引入spark依赖 <?xml version=& ...
- spark api之一:Spark官方文档 - 中文翻译
转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 引入Spark(Linking with Spark) 3 初始化Spark(Initi ...
- py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe. : java.lang.IllegalArgumentException: Unsupported class file major version 55
今天小编用Python编写Spark程序报了如下异常: py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apach ...
- 图解Spark API
初识spark,需要对其API有熟悉的了解才能方便开发上层应用.本文用图形的方式直观表达相关API的工作特点,并提供了解新的API接口使用的方法.例子代码全部使用python实现. 1. 数据源准备 ...
- Spark RDD :Spark API--图解Spark API
面试题引出: 简述Spark的宽窄依赖,以及Spark如何划分stage,每个stage又根据什么决定task个数? Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个 ...
- spark算子:combineByKey
假设我们有一组个人信息,我们针对人的性别进行分组统计,并进行统计每个分组中的记录数. scala> val people = List(("male", "Mobi ...
- spark中的combineByKey函数的用法
一.函数的源码 /** * Simplified version of combineByKeyWithClassTag that hash-partitions the resulting RDD ...
随机推荐
- WPF快速入门系列(9)——WPF任务管理工具实现
转载自:http://www.cnblogs.com/shanlin/p/3954531.html WPF系列自然需要以一个实际项目为结束.这里分享一个博客园博客实现的一个项目,我觉得作为一个练手的项 ...
- C#实现 word、pdf、ppt 转为图片
office word文档.pdf文档.powerpoint幻灯片是非常常用的文档类型,在现实中经常有需求需要将它们转换成图片 -- 即将word.pdf.ppt文档的每一页转换成一张对应的图片,就像 ...
- Html做三个平台原生APP啦
DeviceOne之前介绍过了,现在来介绍一下DeviceOne快速开发到什么程度 使用js只需要5分钟就可以打出垮Android.ios.windows三大平台的纯原生UI的安装包. 只需要6个小时 ...
- FastUI快速界面原型制作工具
FastUI是一款快速制作应用程序界面原型的小工具,它之所以快,是因为它体积小巧.功能简洁实用. 在真正的应用程序(包括winform.手机app.网站等)开始编码之前,一般要先设计出原型,以便确认需 ...
- java指定路径写、读文件
package com.util; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File; ...
- C#设计模式-简单工厂
工厂模式专门负责将大量有共同接口的类实例化.工厂模式可以动态决定将哪一个类实例化,不必事先知道每次要实例化哪一个类.工厂模式有以下几种形态: 简单工厂(Simple Factory)模式 工厂方法(F ...
- 学习ASP.NET MVC(五)——我的第一个ASP.NET MVC CURD页面
在上一篇文章中我们已经创建了实体类,在这一篇文章中,我将创建一个新的控制器类——BookController,使用BookController对Books表中的数据进行CURD操作的方法,并使用视图模 ...
- angularjs可交互的directive
angularjs可交互的directive http://jsfiddle.net/revolunet/s4gm6/ directive开发上手练手,以注释的方式说明 html <body n ...
- Eclipse 启动时提示“发现了以元素'd:skin'开头的无效内容,此处不应含有子元素“
今天打开 Eclipse 时遇到了这个提示,如图所示: 关闭后发现控制台也有提示: [2016-04-19 11:11:20 - Android SDK] Error when loading the ...
- java 中获取2个时间段中所包含的周数(股票的周数->从周六到周五)
Calendar 类中是以周日为开始的第一天的,所以Calendar.DAY_OF_WEEK为1的时候是周日. 在股票中有日K 周K和月K的数据. 在此之中的周K是指交易日中一周的数据,周六到周五为 ...