eclipse远程调试Hadoop
环境需求: 系统:window 10 eclipse版本:Mars Hadoop版本:2.6.0
资源需求:解压后的Hadoop-2.6.0,原压缩包自行下载:下载地址
丑话前头说:
以下的操作中,eclipse的启动均需要右键“管理员运行”!
在创建MapReduce的Project那块需要配置log4j(级别是debug),否则打印不出一些调试的信息,从而不好找出错的原因。配置这个log4j很简单,大家可以在网上搜索一下,应该可以找得到相关的配置。
1)首先需要利用ant编译自己的Hadoop-eclipse-plugin插件,你也可以自己网上搜索下载,我不喜欢用别人的东西,所以自己编译了一把,你们也可以参考我的另一篇博文,学着自己编译——《利用Apache Ant编译Hadoop2.6.0-eclipse-plugin》
2)把编译好的Hadoop插件放到eclipse目录下的plugins下,然后重启eclipse
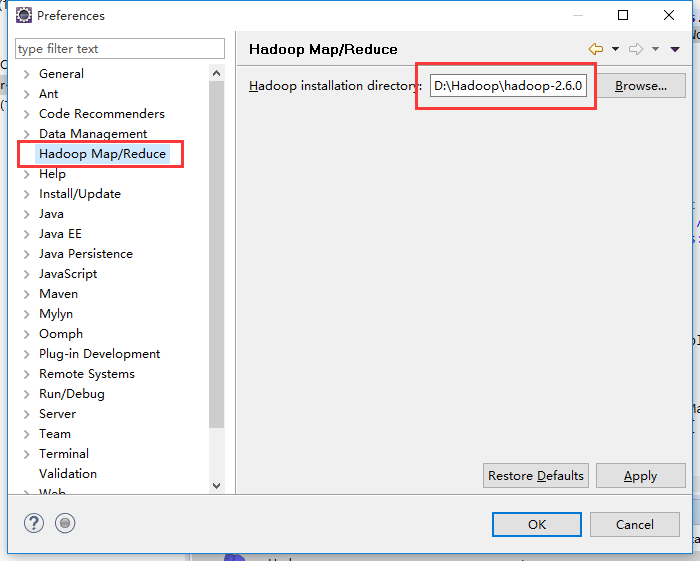
3)打开window-->Preferences-->Hadoop Map/Reduce设置里面的Hadoop安装目录
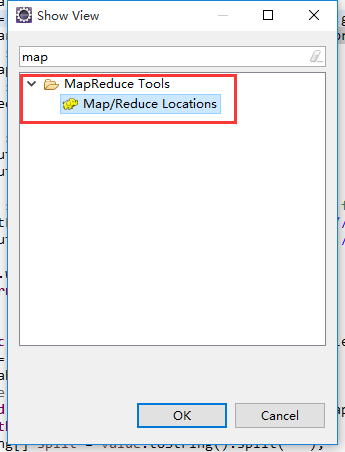
4)打开window-->Show View找到MapReduce Tools下的Map/Reduce Location,确定
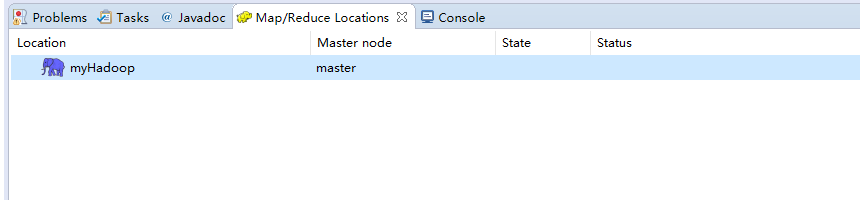
5)然后在eclipse的主界面就可以看到Map/Reduce Location的对话框了
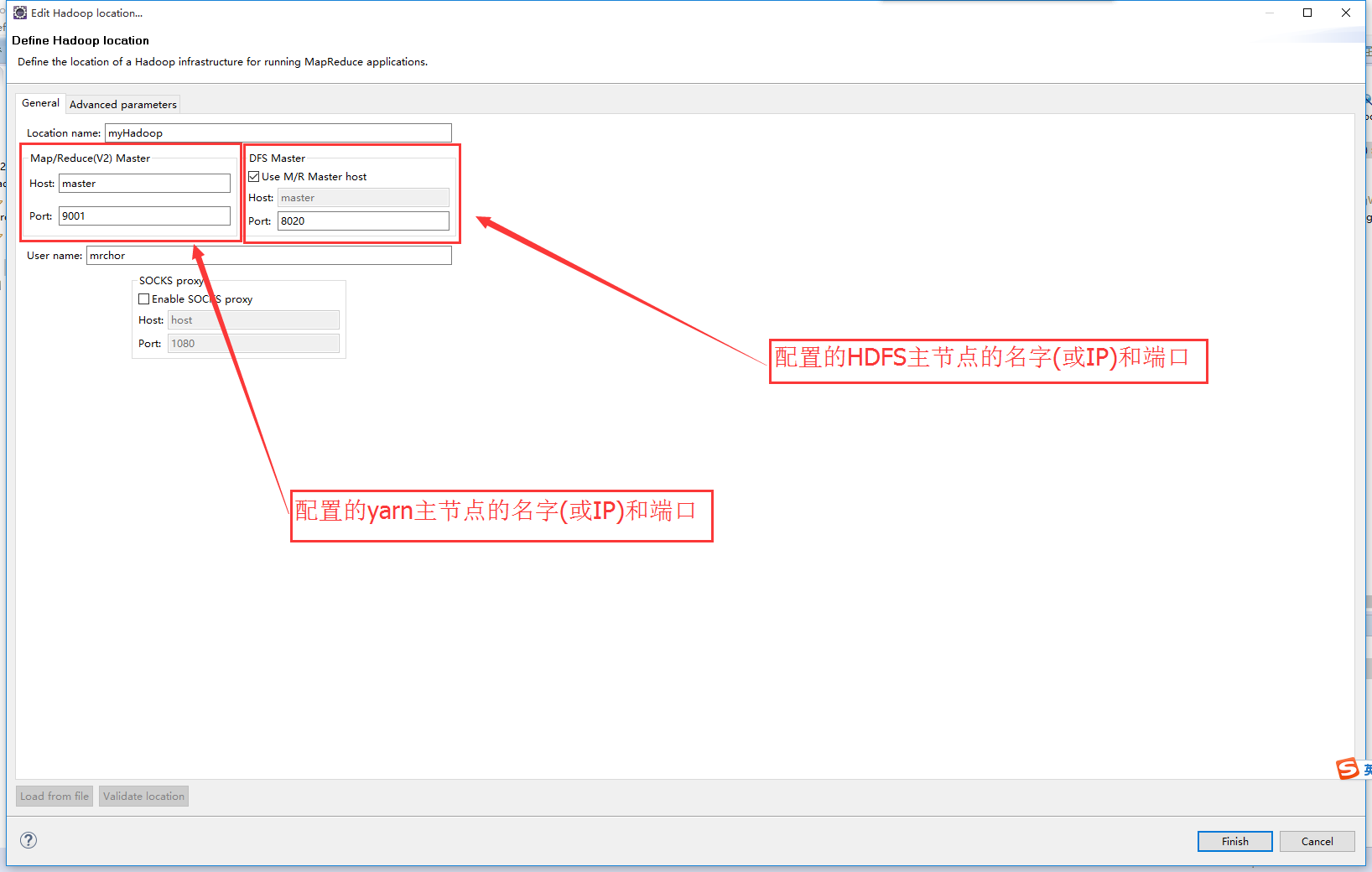
6)新建一个Hadoop Location,修改HDFS和yarn的主节点和端口,finish。
7)这时,在eclipse的Project Explorer中会看到HDFS的目录结构——DFS Locations
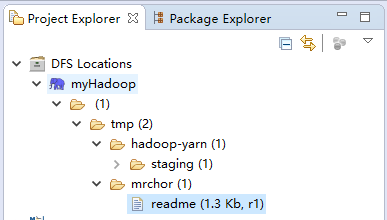
注意:可能你打开这个目录结构的时候回存在权限问题(Premission),这是因为你在Hadoop的HDFS的配置文件hdfs-site.xml中没有配置权限(默认是true,意思是不能被集群外的节点访问HDFS文件目录),我们需要在这儿配置为false,重启hdfs服务,然后刷新上述dfs目录即可:
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
8)然后我们创建一个Map/Reduce Project,创建一个wordcount程序,我把Hadoop的README.txt传到/tmp/mrchor/目录下并改名为readme,输出路径为/tmp/mrchor/out。
package com.mrchor.HadoopDev.hadoopDev; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountApp { public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, WordCountApp.class.getSimpleName());
job.setJarByClass(com.mrchor.HadoopDev.hadoopDev.WordCountApp.class);
// TODO: specify a mapper
job.setMapperClass(MyMapper.class);
// TODO: specify a reducer
job.setReducerClass(MyReducer.class); // TODO: specify output types
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); // TODO: specify input and output DIRECTORIES (not files)
FileInputFormat.setInputPaths(job, new Path("hdfs://master:8020/tmp/mrchor/readme"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://master:8020/tmp/mrchor/out")); if (!job.waitForCompletion(true))
return;
} public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
Text k2 = new Text();
LongWritable v2 = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
String[] split = value.toString().split(" ");
for (String word : split) {
k2.set(word);
v2.set(1);
context.write(k2, v2);
}
}
} public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
long sum = 0;
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
for (LongWritable one : v2s) {
sum+=one.get();
}
context.write(k2, new LongWritable(sum));
}
} }
9)右键Run As-->Run on Hadoop:
A)注意:这边可能报错:
java.io.IOException: HADOOP_HOME or hadoop.home.dir are not set.
这是因为你在安装eclipse的这台机子上没有配置Hadoop的环境变量,需要配置一下:
一)右键“我的电脑”或者“此电脑”选择属性:进入到高级系统设置-->高级-->环境变量配置-->系统变量
新建一个HADOOP_HOME,配置解压后的Hadoop-2.6.0的目录
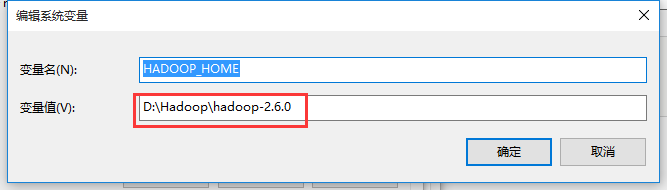
二)重启eclipse(管理员运行)
10)继续运行wordcount程序,Run on Hadoop,可能会报如下错:
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:557)
at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:977)
at org.apache.hadoop.util.DiskChecker.checkAccessByFileMethods(DiskChecker.java:187)
at org.apache.hadoop.util.DiskChecker.checkDirAccess(DiskChecker.java:174)
at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:108)
at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.confChanged(LocalDirAllocator.java:285)
at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.getLocalPathForWrite(LocalDirAllocator.java:344)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:150)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:131)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:115)
at org.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:131)
at org.apache.hadoop.mapred.LocalJobRunner$Job.<init>(LocalJobRunner.java:163)
at org.apache.hadoop.mapred.LocalJobRunner.submitJob(LocalJobRunner.java:731)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:536)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1296)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1293)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1293)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1314)
at com.mrchor.HadoopDev.hadoopDev.WordCountApp.main(WordCountApp.java:34)
通过源码查看,发现在NativeIO.java有说明——还是权限问题,可能是需要将当前电脑加入到HDFS授权的用户组:
/**
* Checks whether the current process has desired access rights on
* the given path.
*
* Longer term this native function can be substituted with JDK7
* function Files#isReadable, isWritable, isExecutable.
*
* @param path input path
* @param desiredAccess ACCESS_READ, ACCESS_WRITE or ACCESS_EXECUTE
* @return true if access is allowed
* @throws IOException I/O exception on error
*/
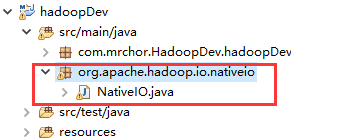
但是,我们这边有一个更加巧妙的办法解决这个问题——将源码中的这个文件复制到你的MapReduce的Project中,这个意思是程序在执行的时候回优先找你Project下的class作为程序的引用,而不会去引入的外部jar包中找:
11)继续运行wordcount程序,这次应该程序可以执行了,结果为:
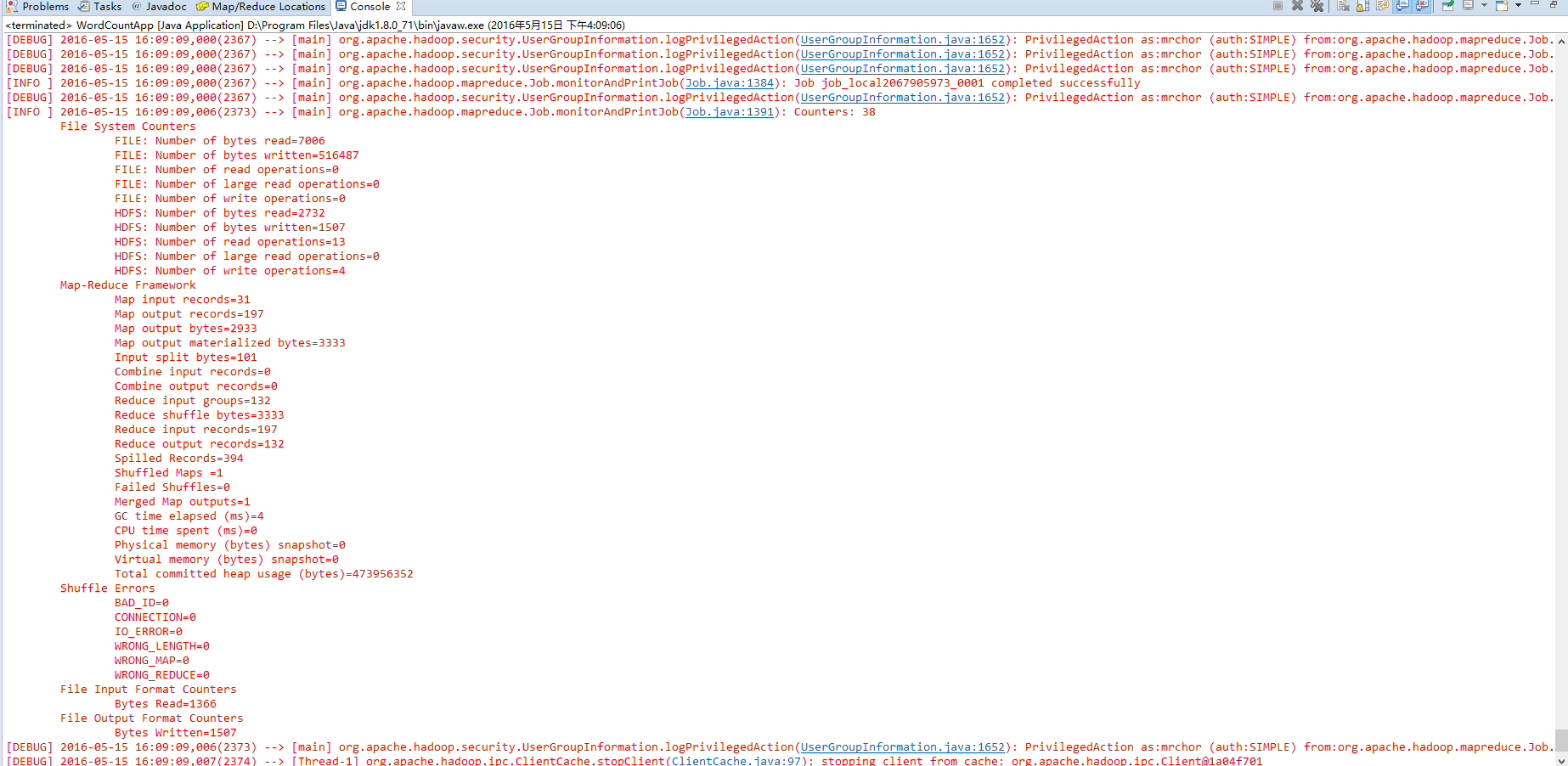
如果得到上面这个结果,说明程序运行正确,打印出来的是MapReduce程序运行结果。我们再刷新目录,可以看到/tmp/mrchor/out目录下有两个文件——_SUCCESS和part-r-00000:
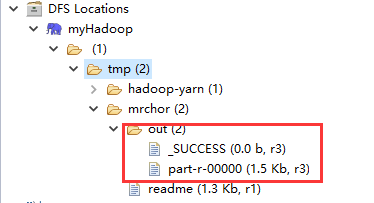

说明程序运行结果正确,此时,我们的eclipse远程调试Hadoop宣告成功!!!大家鼓掌O(∩_∩)O
eclipse远程调试Hadoop的更多相关文章
- Hadoop学习之配置Eclipse远程调试Hadoop
构建完毕Hadoop项目后,接下来就应该跟踪Hadoop的运行情况,比方在命令行运行hadoop namenode–format时运行了Hadoop的那些代码.当然也能够直接通过阅读源码的方式来做到这 ...
- Eclipse远程调试hadoop源码
1. 修改对应调试端口 之前的一篇blog里讲述了hadoop单机版调试的方法,那种调试只限于单机运行hadoop命令而已,对于运行整个hadoop环境而言是不可取的,因为hadoop会开启多个jav ...
- Hadoop学习记录(7)|Eclipse远程调试Hadoop
1.创建Hadoop项目 2.创建包.类 这里使用hdfs.WordCount为例 3.编写自定Mapper和Reducer程序 MyMapper类 static class MyMapper ext ...
- Eclipse远程调试HDP源代码
使用的是自己编译的HDP2.3.0的源代码编译的集群,此文介绍如何使用Eclipse远程调试Hadoop内核源代码,以调试namenode为例进行介绍. 在/usr/hdp/2.3.0.0-2557/ ...
- IDEA远程调试hadoop程序
远程调试Hadoop各组件 Hadoop学习之配置Eclipse远程调试Hadoop IDEA远程调试hadoop Hadoop 研发之远程调试详细剖析--WordCount V2.0 eclipse ...
- eclipse/intellij idea 远程调试hadoop 2.6.0
很多hadoop初学者估计都我一样,由于没有足够的机器资源,只能在虚拟机里弄一个linux安装hadoop的伪分布,然后在host机上win7里使用eclipse或Intellj idea来写代码测试 ...
- 使用Windows上Eclipse远程调试Linux上的Hadoop
一.设置Eclipse运行用户 如果以与Hadoop运行用户名(比如grid)不同的用户运行Eclipse,则无法对Hadoop运行用户所属的文件进行管理,运行Map/Reduce程序也会报& ...
- 远程调试hadoop各组件
远程调试对应用程序开发十分有用.例如,为不能托管开发平台的低端机器开发程序,或在专用的机器上(比如服务不能中断的 Web 服务器)调试程序.其他情况包括:运行在内存小或 CUP 性能低的设备上的 Ja ...
- Eclipse远程连接Hadoop
Windows下面调试程序比在Linux下面调试方便一些,于是用Windows下的Eclipse远程连接Hadoop. 1. 下载相应版本的hadoop-eclipse-plugin插件,复制到ecl ...
随机推荐
- FastDFS介绍
相关术语 1)跟踪服务器tracker server 2)存储服务器 storage server 3)元数据 meta data --- 附件上传的说明 4)客户端 client---对程序员暴露 ...
- matlab的try/catch语句
http://blog.sina.com.cn/s/blog_6fd1f2350102x2p3.html
- 执行超过1个小时的SQL语句
SELECT MO.MO_ID, MO.ITEM, MO.QTYORDERED, MO.PLANNEDSTARTDATE, BR.MAXLOTSIZE FROM TEMP_MO MO, (SELECT ...
- b/s结构的物业管理系统(一)-------登录篇
最近计划做一个非框架的物业管理系统前端使用bootstrap js jquery 等希望各位指点一下共同学习 ---前端登录页面------ 这个页面的输入框组用的bootstrap的,我设置了几张背 ...
- mongodb的linux环境搭建
一.启动 [mongodb@node1 ~]$ mongod -f /data/config/shard1.confmongod: /usr/lib64/libcrypto.so.10: no ver ...
- C# 根据类名称创建类示例
//获得类所在的程序集名称(此处我选择当前程序集) string bllName = System.IO.Path.GetFileNameWithoutExtension(System.Reflect ...
- 九宝老师微信小程序开发的过程
- 通过pinyin4j.jar将(汉字拼音混合字符串)转化成字母首字母
通过pinyin4j.jar将(汉字拼音混合字符串)转化成字母首字母 例如 我的中国心 ==> wdzgx 我的中国心ya ==> wdzgxya woai我的中国 ==> w ...
- [问题解决]《GPU高性能编程CUDA实战》中第4章Julia实例“显示器驱动已停止响应,并且已恢复”问题的解决方法
以下问题的出现及解决都基于"WIN7+CUDA7.5". 问题描述:当我编译运行<GPU高性能编程CUDA实战>中第4章所给Julia实例代码时,出现了显示器闪动的现象 ...
- JavaWeb 学习008-今日问题(非空验证尚未解决) 2016-12-2
1. 学生模块list页面 不能正常跳转 说是找不到stuid属性,但是我在entity里面和数据库建表的属性就是stuid:Grade模块代码一样,却可以正常运行 这是什么问题? <c:for ...